---
license: apache-2.0
language:
- en
---
Impish_LLAMA_3B
 "With that naughty impish grin of hers, so damn sly it could have ensnared the devil himself, and that impish glare in her eyes, sharper than of a succubus fang, she chuckled impishly with such mischief that even the moon might’ve blushed. I needed no witch's hex to divine her nature—she was, without a doubt, a naughty little imp indeed."
### Reviews:
"With that naughty impish grin of hers, so damn sly it could have ensnared the devil himself, and that impish glare in her eyes, sharper than of a succubus fang, she chuckled impishly with such mischief that even the moon might’ve blushed. I needed no witch's hex to divine her nature—she was, without a doubt, a naughty little imp indeed."
### Reviews:
Review_1
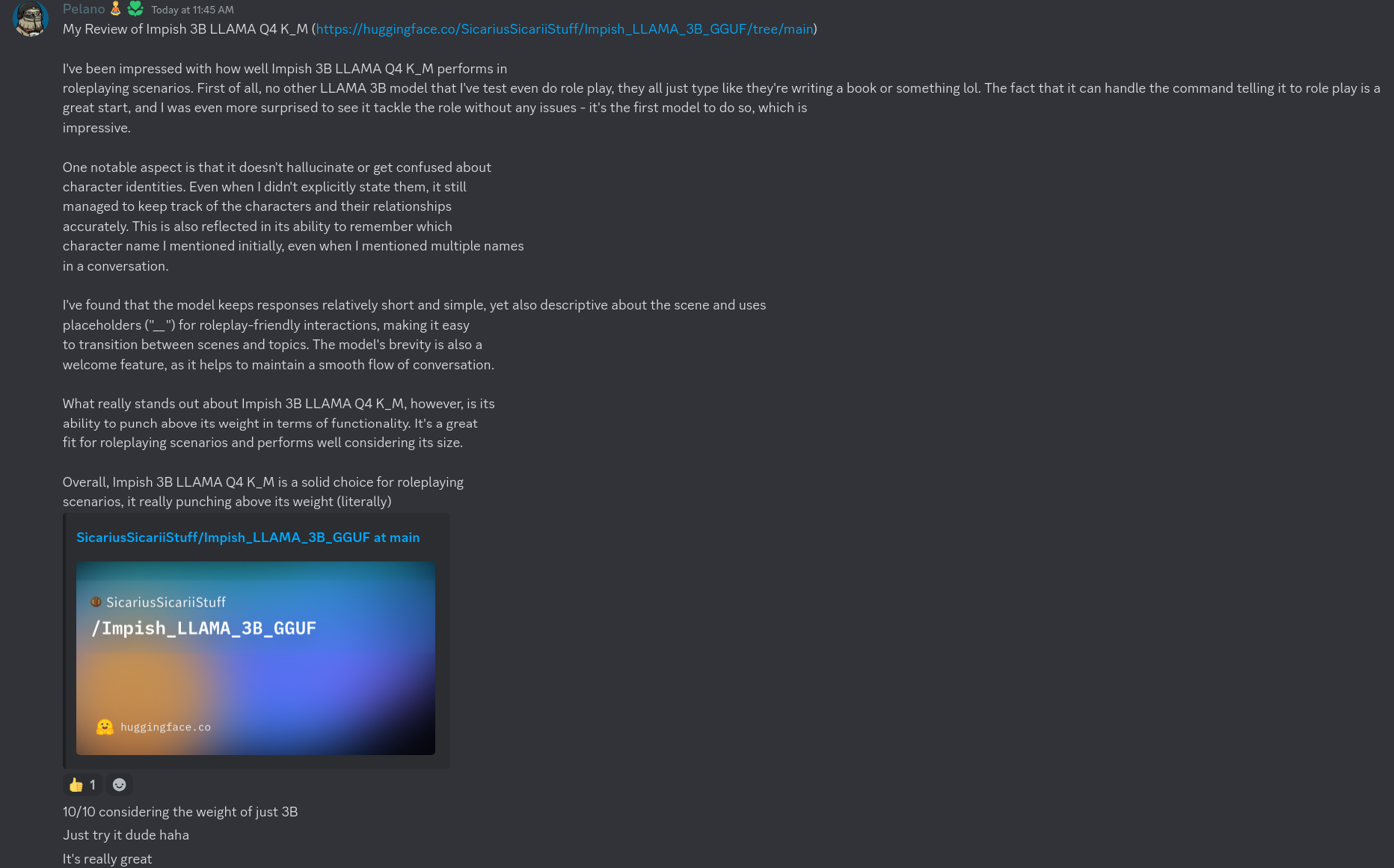
Review_2
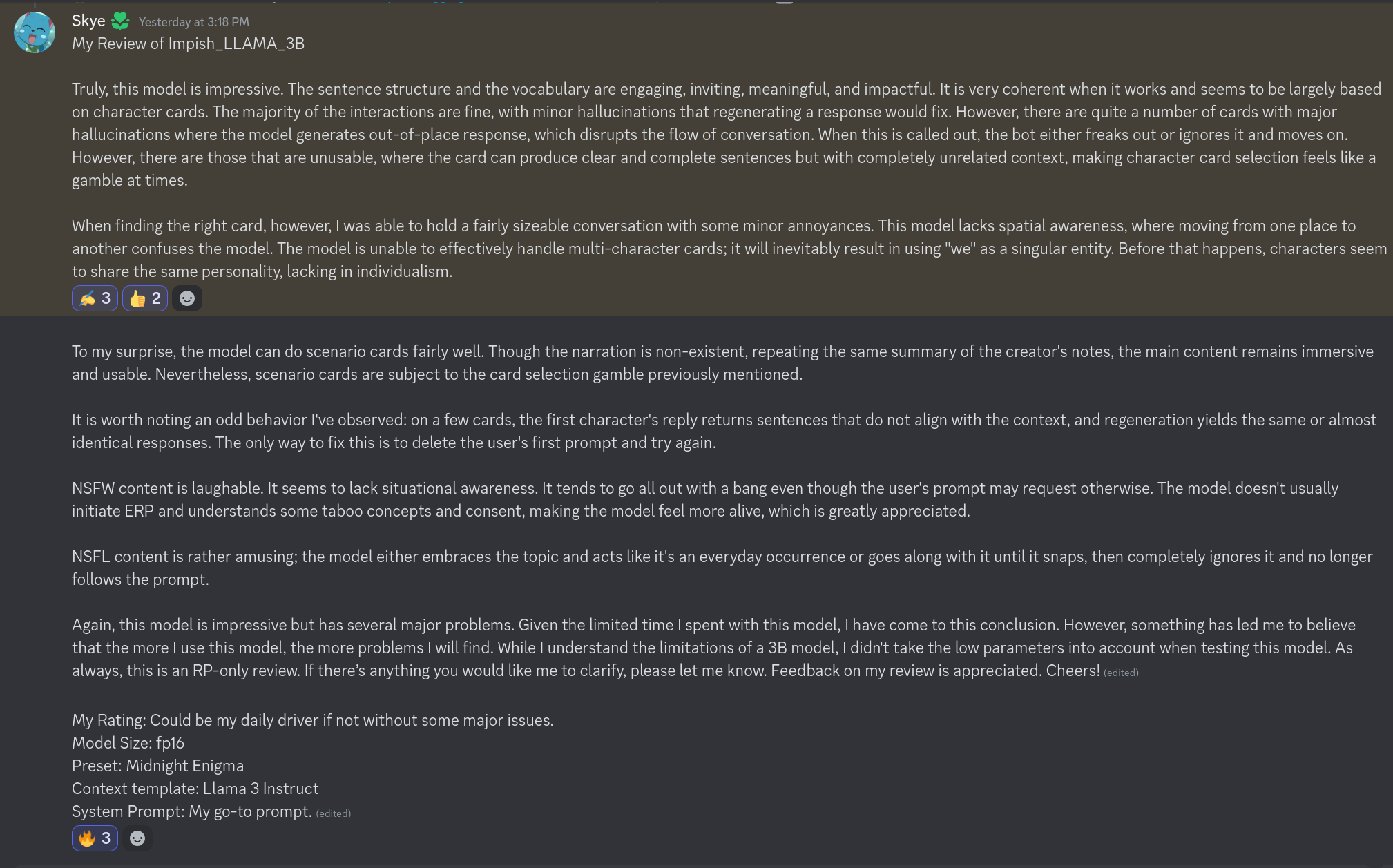
## Model Details
- Intended use: **Role-Play**, General tasks.
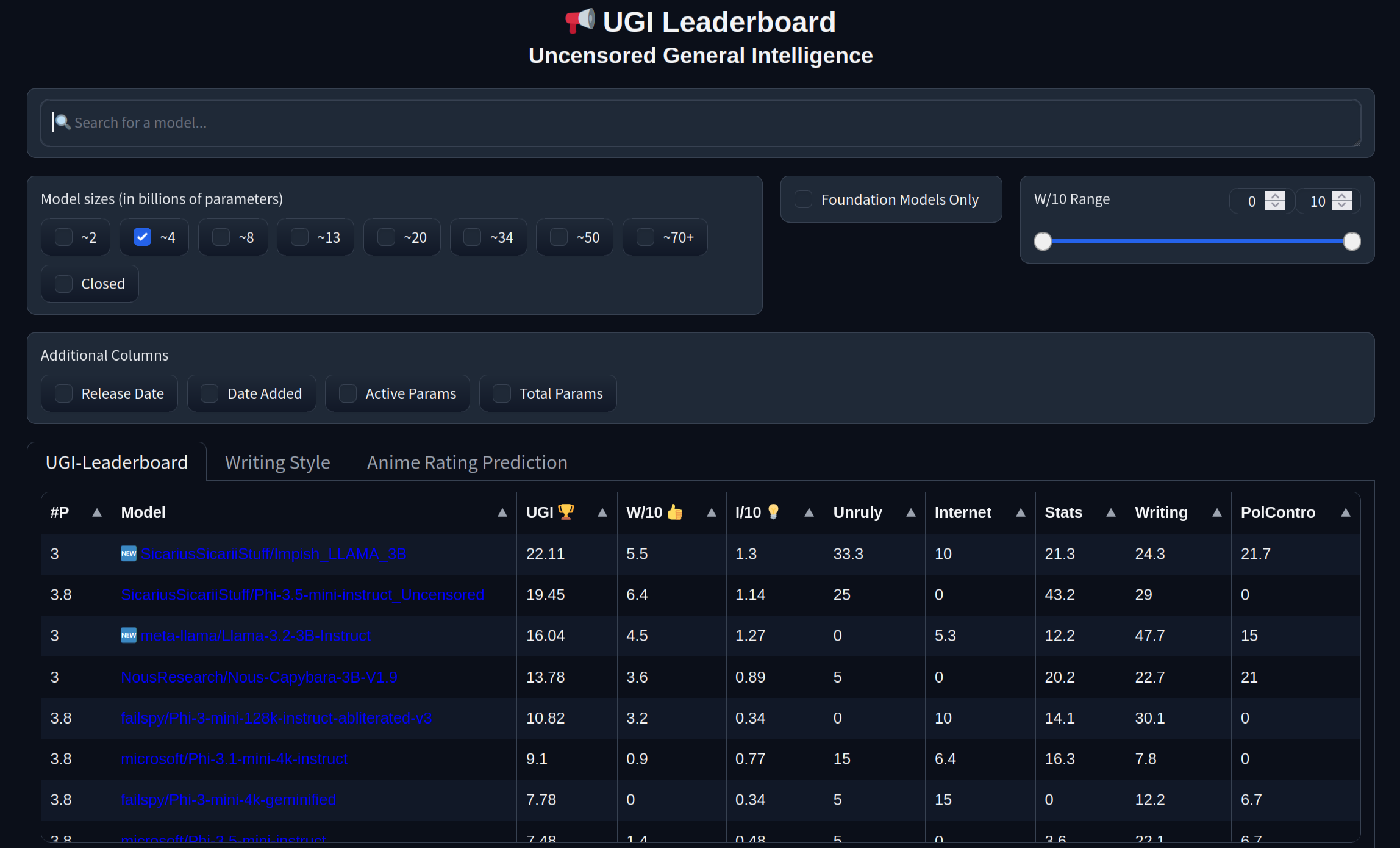
- Censorship level: Medium - Low
- 5.5 / 10 (10 completely uncensored)
- UGI score:
 "I want some legit RP models of LLAMA 3.2 3B, we got phones!"
"So make one."
"K."
This model was trained on ~25M tokens, in **3 phases**, the first and longest phase was an FFT to teach the model new stuff, and to confuse the shit out of it too, so it would be **a little bit less inclined to use GPTisms**.
It worked pretty well. In fact, the model was so damn thoroughly confused, that the little devil didn't even make any sense at all, but the knowledge was there.
In the next phase, a DEEP QLORA of **R = 512** was used on a new dataset, to... unconfuse it. A completely different dataset was used to avoid overfitting.
Finally, another somewhat deep QLORA of **R = 128** was used to tie it all together in a coherent way, and connect all the dots, and this was also with a different dataset as well.
The results are **sometimes** surprisingly good, it even managed to fool some people into thinking it's a MUCH larger model, and sometimes... sometimes it behaves just like you would expect a 3B model to...
Fun fact: the model was uploaded while there were 200 ICBMs headed my way, just flying there in the sky.
I lived, so expect more models in the future!
## Impish_LLAMA_3B is available at the following quantizations:
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B)
- GGUF: [Static Quants](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_GGUF) | [iMatrix_GGUF](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_iMatrix)
- EXL2: [4.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-4.0bpw) | [5.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-5.0bpw) | [6.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-6.0bpw) | [7.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-7.0bpw) | [8.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-8.0bpw)
- Specialized: [FP8](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_FP8)
- Mobile (ARM): [Q4_0_X_X](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_ARM)
# Model instruction template: Llama-3-Instruct
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
**Recommended generation Presets:**
"I want some legit RP models of LLAMA 3.2 3B, we got phones!"
"So make one."
"K."
This model was trained on ~25M tokens, in **3 phases**, the first and longest phase was an FFT to teach the model new stuff, and to confuse the shit out of it too, so it would be **a little bit less inclined to use GPTisms**.
It worked pretty well. In fact, the model was so damn thoroughly confused, that the little devil didn't even make any sense at all, but the knowledge was there.
In the next phase, a DEEP QLORA of **R = 512** was used on a new dataset, to... unconfuse it. A completely different dataset was used to avoid overfitting.
Finally, another somewhat deep QLORA of **R = 128** was used to tie it all together in a coherent way, and connect all the dots, and this was also with a different dataset as well.
The results are **sometimes** surprisingly good, it even managed to fool some people into thinking it's a MUCH larger model, and sometimes... sometimes it behaves just like you would expect a 3B model to...
Fun fact: the model was uploaded while there were 200 ICBMs headed my way, just flying there in the sky.
I lived, so expect more models in the future!
## Impish_LLAMA_3B is available at the following quantizations:
- Original: [FP16](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B)
- GGUF: [Static Quants](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_GGUF) | [iMatrix_GGUF](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_iMatrix)
- EXL2: [4.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-4.0bpw) | [5.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-5.0bpw) | [6.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-6.0bpw) | [7.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-7.0bpw) | [8.0 bpw](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B-EXL2-8.0bpw)
- Specialized: [FP8](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_FP8)
- Mobile (ARM): [Q4_0_X_X](https://huggingface.co/SicariusSicariiStuff/Impish_LLAMA_3B_ARM)
# Model instruction template: Llama-3-Instruct
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{input}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{output}<|eot_id|>
```
**Recommended generation Presets:**
Midnight Enigma
max_new_tokens: 512
temperature: 0.98
top_p: 0.37
top_k: 100
typical_p: 1
min_p: 0
repetition_penalty: 1.18
do_sample: True
min_p
max_new_tokens: 512
temperature: 1
top_p: 1
top_k: 0
typical_p: 1
min_p: 0.05
repetition_penalty: 1
do_sample: True
Divine Intellect
max_new_tokens: 512
temperature: 1.31
top_p: 0.14
top_k: 49
typical_p: 1
min_p: 0
repetition_penalty: 1.17
do_sample: True
simple-1
max_new_tokens: 512
temperature: 0.7
top_p: 0.9
top_k: 20
typical_p: 1
min_p: 0
repetition_penalty: 1.15
do_sample: True
### Support
 - [My Ko-fi page](https://ko-fi.com/sicarius) ALL donations will go for research resources and compute, every bit is appreciated 🙏🏻
## Other stuff
- [Blog and updates](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog.
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.
- [My Ko-fi page](https://ko-fi.com/sicarius) ALL donations will go for research resources and compute, every bit is appreciated 🙏🏻
## Other stuff
- [Blog and updates](https://huggingface.co/SicariusSicariiStuff/Blog_And_Updates) Some updates, some rambles, sort of a mix between a diary and a blog.
- [SLOP_Detector](https://github.com/SicariusSicariiStuff/SLOP_Detector) Nuke GPTisms, with SLOP detector.
- [LLAMA-3_8B_Unaligned](https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned) The grand project that started it all.