LLM数据工程3——数据收集魔法:获取顶级训练数据的方法






本文是DataTager团队关于大模型数据的系列文章十万字总结《从数据到AGI:开启大模型智能的秘密》中的数据收集部分,以下是本文的同步链接:
https://huggingface.co/blog/JessyTsu1/data-collect
https://datatager.com/blog/data_collect_zh
https://zhuanlan.zhihu.com/p/700613165
ChatGPT诞生一年多后的今天,人们逐渐理解了大模型的运行逻辑,并在积极探索其落地场景。我们始终坚信大模型是一个以数据为中心的领域(data-centric),而不是以模型为中心(model-centric)。因此,在大模型时代的探索中,我们积累了大量关于数据的经验和思考,并将这些经验汇集成系列文章《从数据到AGI:开启大模型智能的秘密》。基于这些经验,我们还开发了产品DataTager,会在随后上线。
数据在大模型中的作用已经不言而喻。合理地收集数据以及选择收集哪些数据是一个非常重要的话题。接下来,我们将详细探讨几种主要的数据收集方法,分析其优缺点和实际应用情况。
一、爬虫
当我们在某个网站看到很不错的合适的数据的时候,第一想法就是把他们全部下载到本地,以供模型训练,所以便有了爬虫
概念和原理
- 爬虫是一种自动化程序,用于在互联网上系统地浏览和提取数据。它们通过模拟用户行为,访问网页并提取所需的信息。
优点
- 大规模数据获取:网络爬虫能够从大量网站上获取海量数据,为模型训练提供丰富的语料。
- 高频率更新:爬虫可以定期抓取最新的数据,确保数据的时效性和新鲜度。
传统工具
- Scrapy:一个强大的Python爬虫框架,适合大规模爬取项目。
- 特点:模块化设计、支持多线程、强大的抓取和处理能力。
- 使用场景:适用于需要处理大量数据的网站爬取,例如电商、新闻门户。
pip install scrapy
cat > myspider.py <<EOF
import scrapy
class BlogSpider(scrapy.Spider):
name = 'blogspider'
start_urls = ['https://www.zyte.com/blog/']
def parse(self, response):
for title in response.css('.oxy-post-title'):
yield {'title': title.css('::text').get()}
for next_page in response.css('a.next'):
yield response.follow(next_page, self.parse)
EOF
scrapy runspider myspider.py
- Beautiful Soup:一个用于解析HTML和XML文档的Python库,适合小规模数据抓取。
- 特点:易于学习和使用、能够快速解析和处理HTML内容。
- 使用场景:适用于结构简单、数据量较小的网站。
- Selenium:一个用于自动化Web浏览的工具,能够处理动态加载的网页内容。
- 特点:支持JavaScript渲染、能够模拟用户操作。
- 使用场景:适用于需要处理动态内容的网站,如实时数据更新的页面。
新型AI爬虫
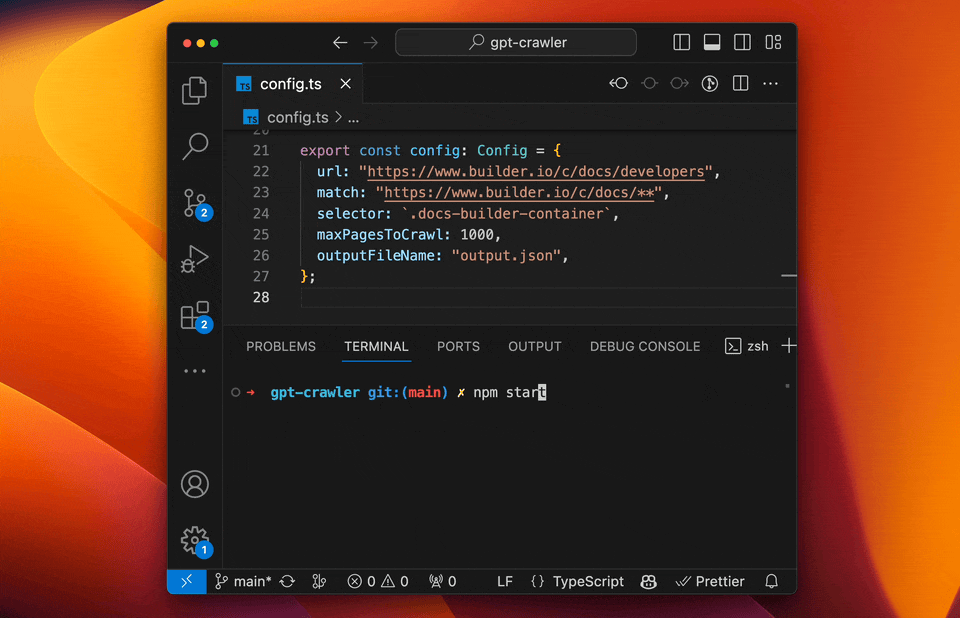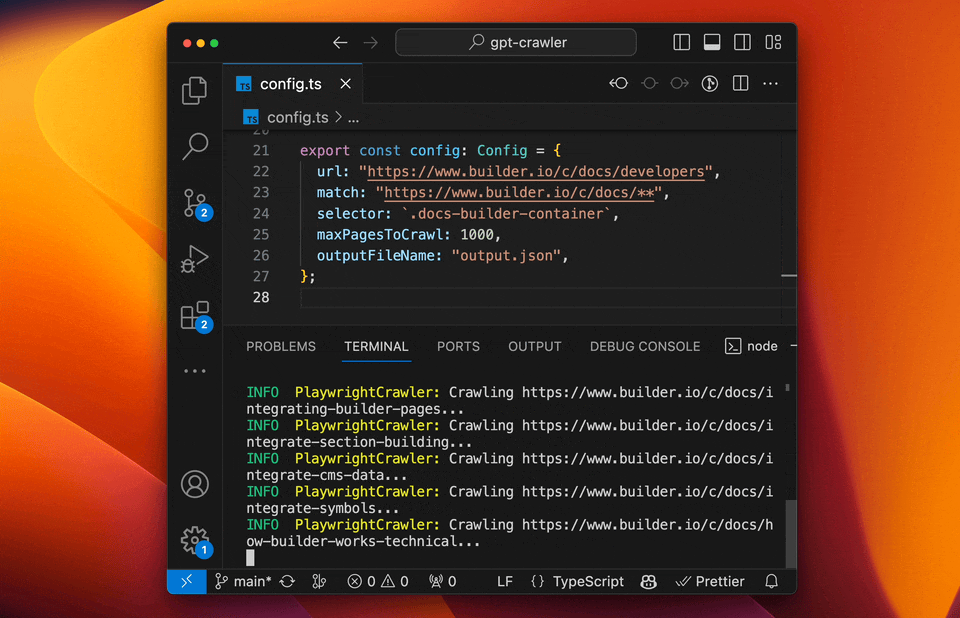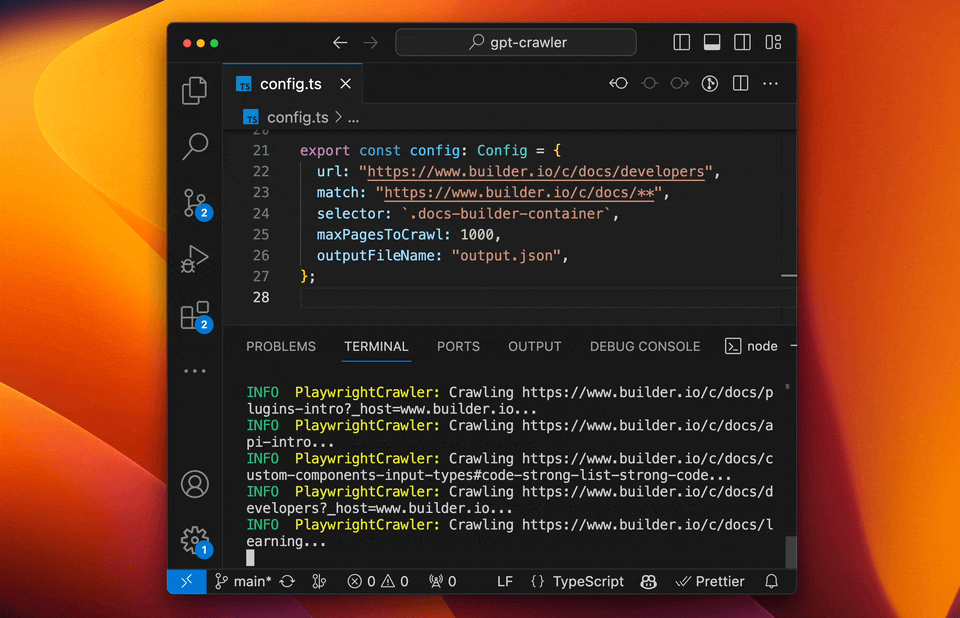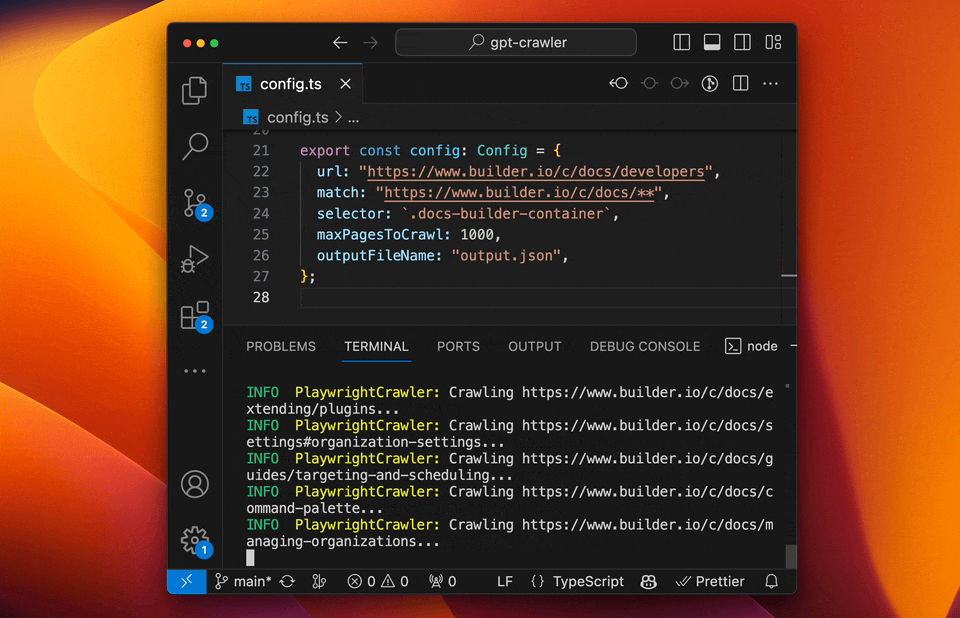
- GPT-Crawler (BuilderIO):结合GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。
- 特点:自然语言处理能力强、自动化程度高、能够理解上下文。
- 使用场景:适用于复杂结构和需要深度理解的网站。
- 实例:使用GPT-Crawler抓取技术博客,自动分类和总结内容。
- Scrapegraph-AI (VinciGit00):利用图神经网络进行数据提取,适用于结构复杂的数据集成。
- 特点:处理复杂关系型数据、能够高效整合多源数据。
- 使用场景:适用于需要从多源数据中提取关系信息的网站。
- 实例:利用Scrapegraph-AI抓取社交网络数据,分析用户关系和互动。

- MarkdownDown:专注于从网页内容生成结构化Markdown文件,便于数据整理和使用。

- 特点:生成结构化文档、易于编辑和分享。
- 使用场景:适用于需要将网页内容转化为可读文档的网站。
- 实例:用MarkdownDown抓取技术文档网站,将内容转化为Markdown文件,便于内部使用。
- Jina Reader:利用AI技术从网页中提取和总结关键信息,提升数据收集的效率和准确性。

- 特点:自动化信息提取、智能摘要生成。
- 使用场景:适用于需要快速获取和总结信息的网站。
- 实例:使用Jina Reader抓取财经新闻网站,提取并总结市场动态。
| 类别 | Scrapy | Beautiful Soup | Selenium | GPT-Crawler | Scrapegraph-AI | MarkdownDown | Jina Reader |
|---|---|---|---|---|---|---|---|
| 概念和原理 | 一个强大的Python爬虫框架,适合大规模爬取项目。 | 一个用于解析HTML和XML文档的Python库,适合小规模数据抓取。 | 一个用于自动化Web浏览的工具,能够处理动态加载的网页内容。 | 结合GPT-3能力的爬虫工具,能够理解和处理复杂的网页结构。 | 利用图神经网络进行数据提取,适用于结构复杂的数据集成。 | 专注于从网页内容生成结构化Markdown文件,便于数据整理和使用。 | 利用AI技术从网页中提取和总结关键信息,提升数据收集的效率和准确性。 |
| 优点 | 模块化设计、支持多线程、强大的抓取和处理能力。 | 易于学习和使用,快速解析和处理HTML内容。 | 支持JavaScript渲染,能够模拟用户操作。 | 自然语言处理能力强、自动化程度高、能够理解上下文。 | 处理复杂关系型数据、能够高效整合多源数据。 | 生成结构化文档、易于编辑和分享。 | 自动化信息提取、智能摘要生成。 |
| 缺点 | 需要编写大量代码,对初学者不友好。 | 处理大规模数据效率低,不支持异步操作。 | 速度慢,资源消耗大。 | 可能需要更多计算资源和前期配置。 | 技术复杂,前期学习成本高。 | 仅适用于特定格式的数据提取。 | 依赖于AI模型的准确性和性能。 |
| 适用场景 | 大规模数据抓取,如电商、新闻门户。 | 结构简单、数据量较小的网站。 | 动态内容网站,如实时数据更新的页面。 | 复杂结构和需要深度理解的网站。 | 多源数据提取和整合。 | 需要将网页内容转化为可读文档的网站。 | 快速获取和总结信息的网站。 |
| 实际案例 | 利用Scrapy抓取亚马逊商品数据,分析市场趋势。 | 使用Beautiful Soup抓取博客文章内容,用于文本分析。 | 用Selenium抓取动态加载的新闻网站,获取最新的新闻文章。 | 使用GPT-Crawler抓取技术博客,自动分类和总结内容。 | 利用Scrapegraph-AI抓取社交网络数据,分析用户关系和互动。 | 用MarkdownDown抓取技术文档网站,将内容转化为Markdown文件,便于内部使用。 | 使用Jina Reader抓取财经新闻网站,提取并总结市场动态。 |
传统爬虫工具 vs. 新型AI爬虫工具
| 类别 | 传统爬虫工具 | 新型AI爬虫工具 |
|---|---|---|
| 理解能力 | 依赖预定义规则和结构,处理复杂网页可能困难。 优势:高效处理结构简单的网页。 劣势:处理复杂或动态内容能力有限,需要手动配置。 |
利用NLP和图神经网络等技术,更好理解复杂网页结构。 优势:理解能力强,能自动调整抓取策略。 劣势:可能需更多计算资源和前期配置。 |
| 灵活性 | 需要手动编写代码处理不同类型网页,灵活性低。 优势:特定任务优化后执行效率高。 劣势:难适应新类型网站或结构变化。 |
高自适应能力,可根据网页内容自动调整抓取策略。 优势:灵活应对不同网站和内容结构。 劣势:初始设置和训练时间长。 |
| 效率 | 处理大规模数据效率高,但需大量前期配置。 优势:高效处理已知结构数据。 劣势:前期配置工作量大,难应对结构变化。 |
智能分析和自动化流程,提高数据抓取效率和准确性。 优势:自动化程度高,减少人工干预。 劣势:运行时需更多资源。 |
| 易用性 | 需编写和维护大量代码,学习曲线陡峭。 优势:技术文档和社区支持丰富。 劣势:对新手不友好,需前期配置和持续维护。 |
提供用户友好界面和自动化功能,降低使用门槛。 优势:易上手,减少编码需求。 劣势:需理解复杂AI模型和配置。 |
| 成本 | 开源工具通常免费,但需大量开发和维护资源。 优势:使用成本低。 劣势:隐性成本高(如开发时间和维护)。 |
可能需支付使用费或订阅服务,特别是商业解决方案。 优势:降低开发和维护成本。 劣势:初始投资高。 |
| 适用性 | 适用于已知结构和规则网站,特别是静态网页。 优势:高效抓取结构稳定网站。 劣势:对动态或频繁变化网站适应性差。 |
适用复杂结构和动态内容网站,自动适应和调整抓取策略。 优势:适用各种类型网站。 劣势:对简单结构网站可能过于复杂。 |
| 法律和道德 | 需手动确保遵守数据隐私法规和网站爬取规则。 优势:明确的法律边界。 劣势:需大量手动检查和调整。 |
内置合规检查和隐私保护功能,自动遵守法律和道德规范。 优势:减少法律风险和道德问题。 劣势:依赖工具合规性。 |
法律和道德考虑
1、数据隐私问题
在进行数据抓取时,数据隐私是必须要考虑的重要因素。随着全球范围内对数据隐私的重视,各国纷纷出台了相关法律法规,如欧盟的《通用数据保护条例》(GDPR)和加州的《消费者隐私法案》(CCPA)。这些法规旨在保护用户的隐私权,防止未经授权的个人数据收集和使用。
- 遵守隐私法规:在抓取数据时,必须确保遵守所在国家和地区的隐私法规。例如,避免抓取包含个人身份信息(PII)的数据,或在必要时获取用户的明确同意。
- 数据匿名化和去标识化:对抓取到的数据进行匿名化和去标识化处理,以保护用户隐私。在数据处理和存储过程中,确保任何个人信息都无法追溯到具体个人。
2、遵守robots.txt协议
robots.txt协议是一种用于告诉搜索引擎和其他爬虫哪些页面可以被抓取、哪些页面不可以被抓取的文本文件。网站管理员通过在网站根目录下放置robots.txt文件来定义爬虫访问规则。
- 读取和遵守robots.txt文件:在抓取数据之前,爬虫应首先读取目标网站的robots.txt文件,遵守其中定义的抓取规则。这不仅有助于避免给目标网站带来负担,也体现了对网站管理员意愿的尊重。
- 负载管理:合理设置爬虫的抓取频率,避免对目标网站服务器造成过大的负载。可以使用爬虫框架中的延迟设置功能,控制抓取速度,减少对网站的影响。
3、如何规避其他AI公司的爬虫
https://darkvisitors.com/这个网站收录了各大 AI 公司的爬虫使用的User Agent,并且告诉了你如何在 robots.txt 里面屏蔽这些爬虫的访问
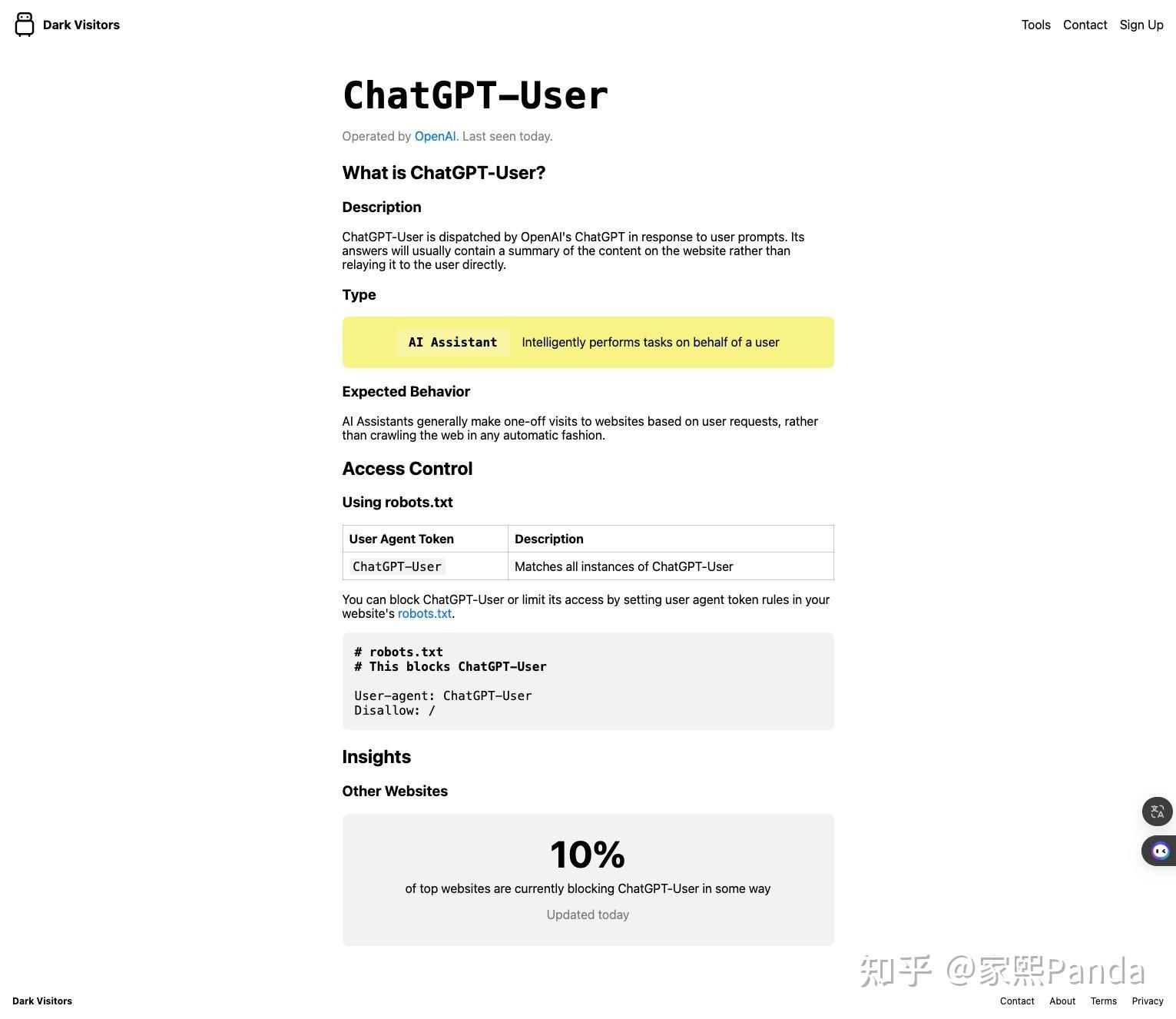
实践使用
我五年前在新浪、搜狐的时候,我们内部有一个庞大的分布式爬虫系统的部门,技术上基本包含所有爬虫会遇到的问题,所以也算有丰富的经验,在此抛砖引玉。
爬虫的核心是模拟人为的全部操作,随后将其自动化掉。
1、如何构建通用AI爬虫
(这部分代码可以在这里查看 https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py)
代码工程里有一个原则:抽象。
为什么提到抽象?
构建一个通用的AI爬虫,听起来是很宏大、技术含量很高的一件事情,容易让人觉得很难完成。所以我们可以先抛弃掉脑子里对这个概念的难度认知,而按照以下我们解决问题的逻辑去考虑:
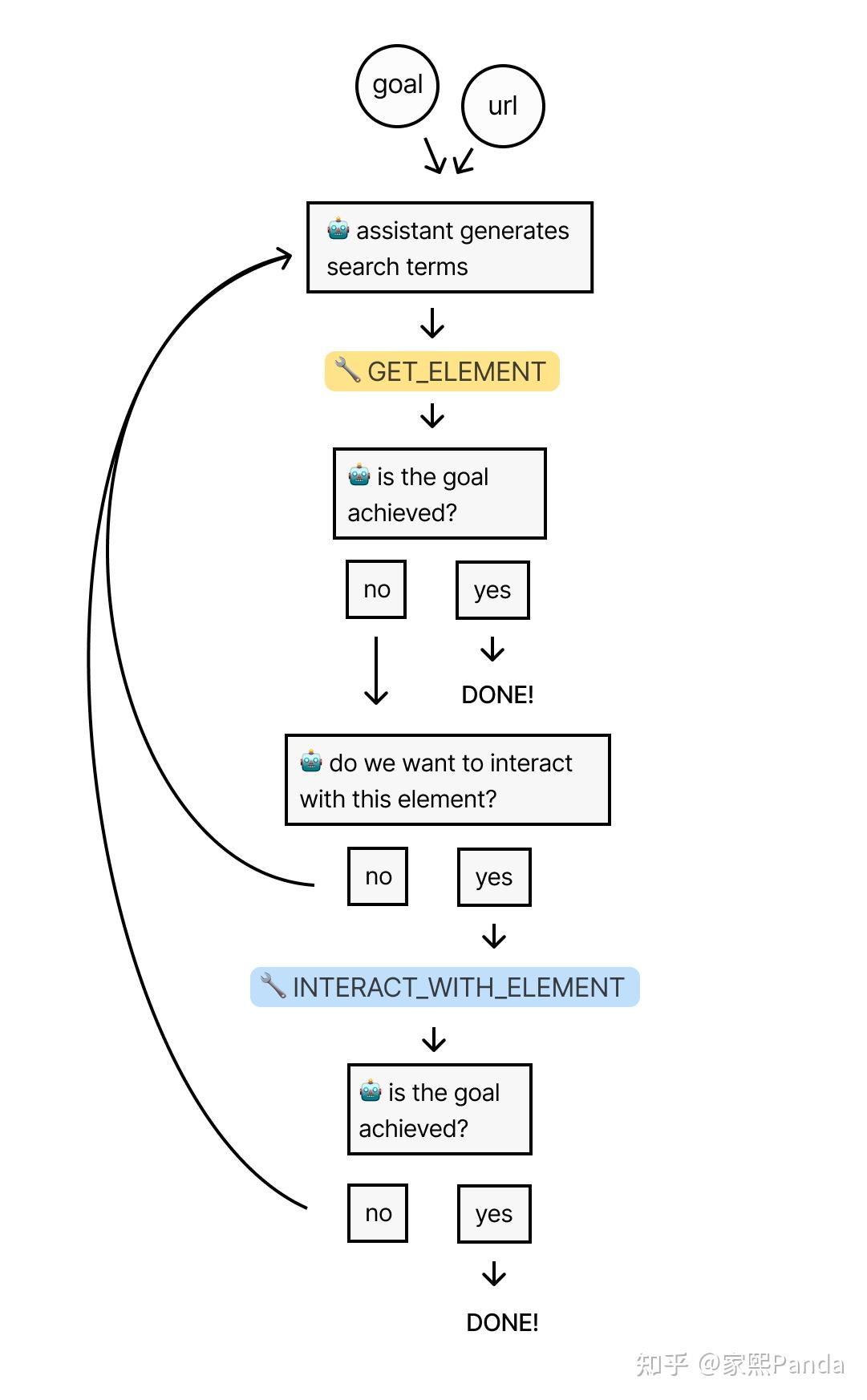
一、这个问题的输入和输出应该是什么?
经过简单的思考,易得:
input: 目标网站URL、要爬的内容
output:爬好的内容整理成的文件
从而这个问题被我们初步定义了下来,再去思考:
二、能否从当前的input直接得到output?
听起来有点困难,因为没有一个方式可以让我们直接从这个input得到output,中间似乎都有一系列其他麻烦的逻辑还未解决,那么下一个问题便是:
三、中间的麻烦的逻辑到底有几步?每一步的input和output是什么?
至此,我们便可以梳理出一条清晰的逻辑链路:
step1: fetch_html.py
input: 目标网站URL
output: 目标网站的HTML内容
step2: parse_content.py
input: 目标网站的HTML内容+要爬的内容
output: 解析出的具体数据(如文本、图片等)
step3: process_data.py
input: 解析出的具体数据(如文本、图片等)
output: 对数据进行进一步的处理,如文本清洗、格式标准化等。
step4: save_data.py
input: 处理后的数据
output: 保存好的文件
以爬https://datatager.com/blog为例,从前step1-4是怎么做的?
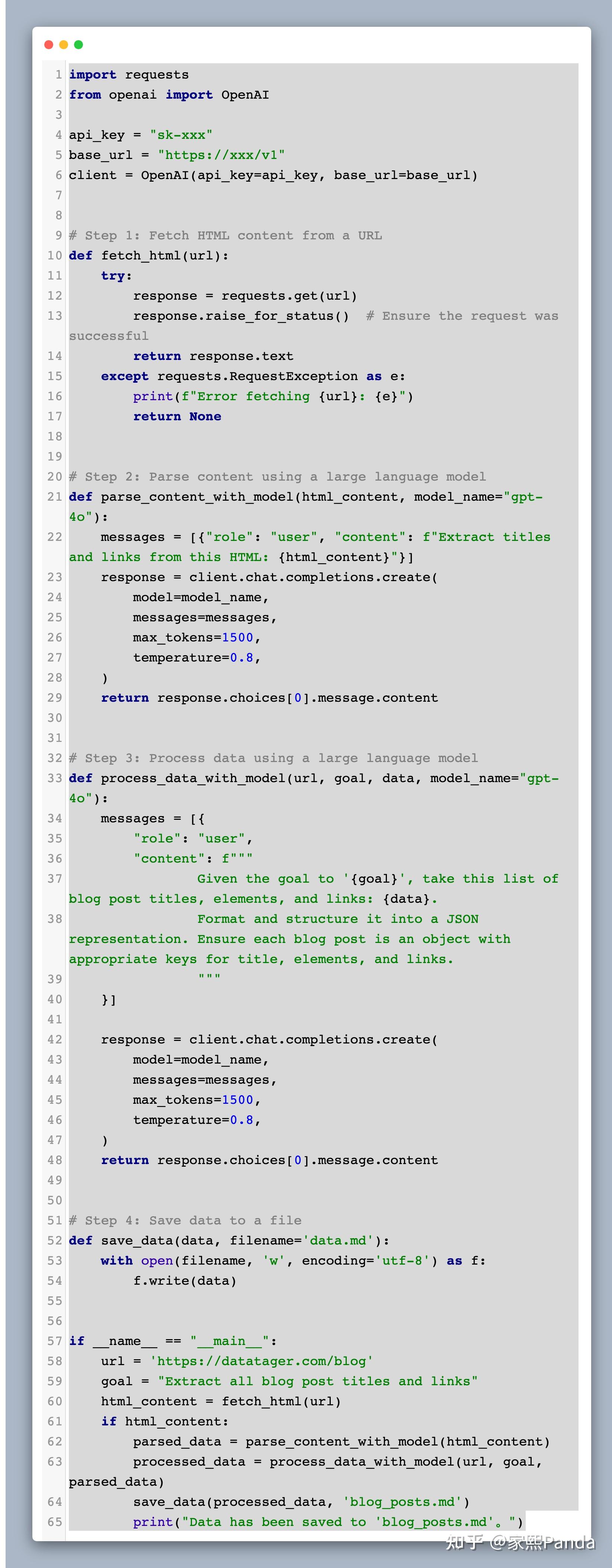
Step 1: fetch_html.py
首先,我们需要一个可以从给定URL获取HTML内容的函数。
import requests
def fetch_html(url):
try:
response = requests.get(url)
response.raise_for_status()
return response.text
except requests.RequestException as e:
print(f"Error fetching {url}: {e}")
return None
Step 2: parse_content.py
接下来,解析HTML内容以找到所有博客文章的标题和链接。
from bs4 import BeautifulSoup
def parse_content(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
articles = soup.find_all('h2', class_='entry-title') 假设标题在<h2 class="entry-title">标签中
data = []for article in articles:
title = article.find('a').get_text() 提取标题文本
link = article.find('a')['href'] 提取链接
data.append({'title': title, 'link': link})return data
Step 3: process_data.py
这一步可以用于进一步处理数据,例如简化或格式化。在这个例子中,我们可能不需要复杂的处理。
def clean_text(text):
# 简单的文本清洗逻辑
cleaned_text = text.replace('\n', ' ').strip()
return cleaned_text
def process_data(data):
return [clean_text(text) for text in data]
Step 4: save_data.py
最后,我们需要一个函数来将数据保存到文件中。
import json
def save_data(data, filename='data.json'):with open(filename, 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4, ensure_ascii=False)
主函数
最后,我们可以组合这些步骤来运行完整的爬虫。
if name == "__main__":
url = 'https://datatager.com/blog'
html_content = fetch_html(url)
if html_content:
parsed_data = parse_content(html_content)
processed_data = process_data(parsed_data)
save_data(processed_data, 'blog_posts.json')
print("数据已保存到 'blog_posts.json'。")
AI加持可以解决什么?
所以我们去爬https://datatager.com/blog这个网站,本质是把网站的html存下来,然后去解析得到我们想要的内容,
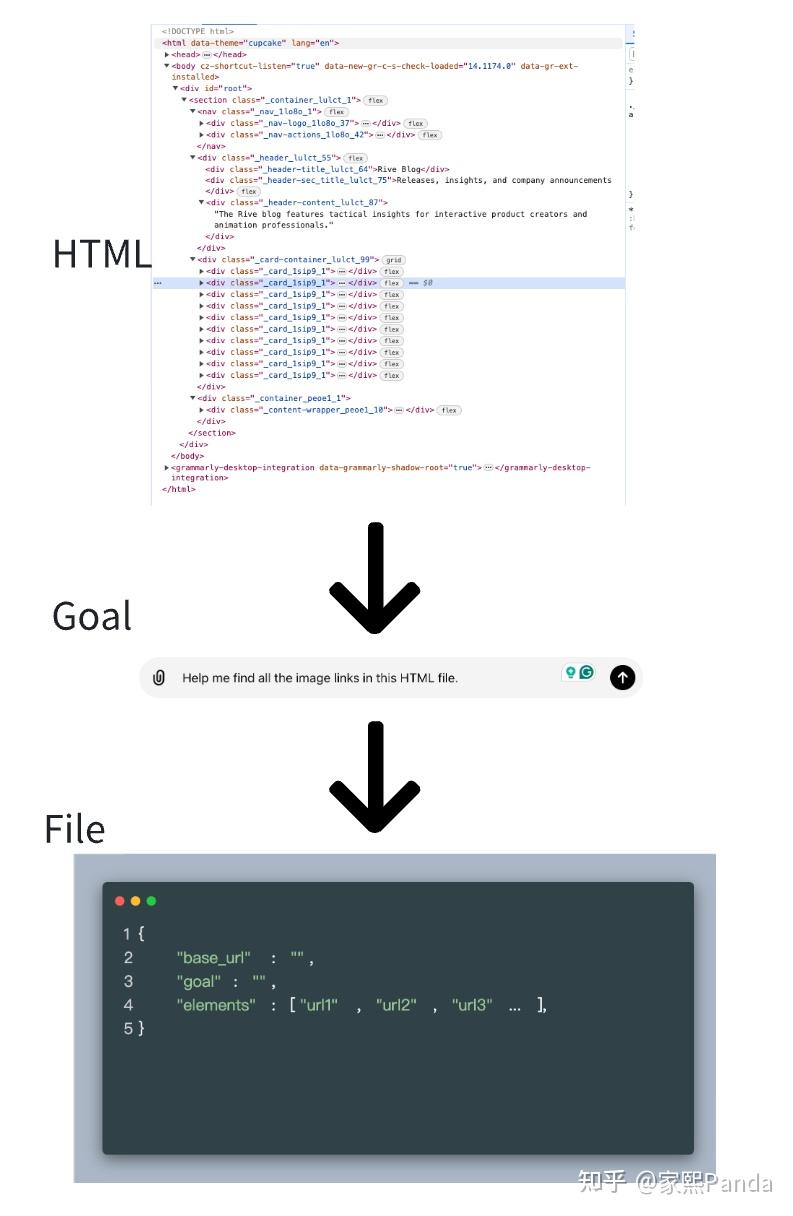
而以上的step2步骤,从前我们是使用xpath、css选择器、正则等方式从html元素中抽取我们想要的元素
step3的数据处理,从前我们是通过简单的replace、正则等规则,或是简单的BERT、word2vec等模型来实现的
而这两步本质都是语言理解类型的任务,现在我们可以借助LLM的天然强大的语言理解能力来完成这两件事情。
当然我这里缺失了很多小细节,一个实际可运行的工程项目需要做的更多。但以上通过三步抽象的方法,可以很好的解决复杂逻辑工程问题。同时这也是通用AI爬虫的雏形
这是本部分的简单代码,但已经可以运行并取到不错的效果了,大家感兴趣的可以基于这个代码雏形进行扩增 https://github.com/PandaVT/DataTager/blob/main/blog_code/ai_crawler.py
2、传统爬虫和Scrapy的用法(以某院校库为例)
PS: 因为第一部分已经详细介绍了爬虫的流程,所以以下几部分只会简单介绍
具体代码请挪步:https://github.com/JessyTsu1/Primary_students
代码结构
code文件夹,是初步简单分析的代码
data文件夹,是最后的数据和处理
Multi_stu文件夹,是使用scrapy爬取
先简单写个爬虫捋一下需求和思路
- 详情页的url:https://school.wjszx.com.cn/senior/list.html
- 每一页的url:https://school.wjszx.com.cn/senior/introduce-2.html
- 目录页的代码,可以看到没对每个标签打title,后续应该会出错,所以不用目录抓
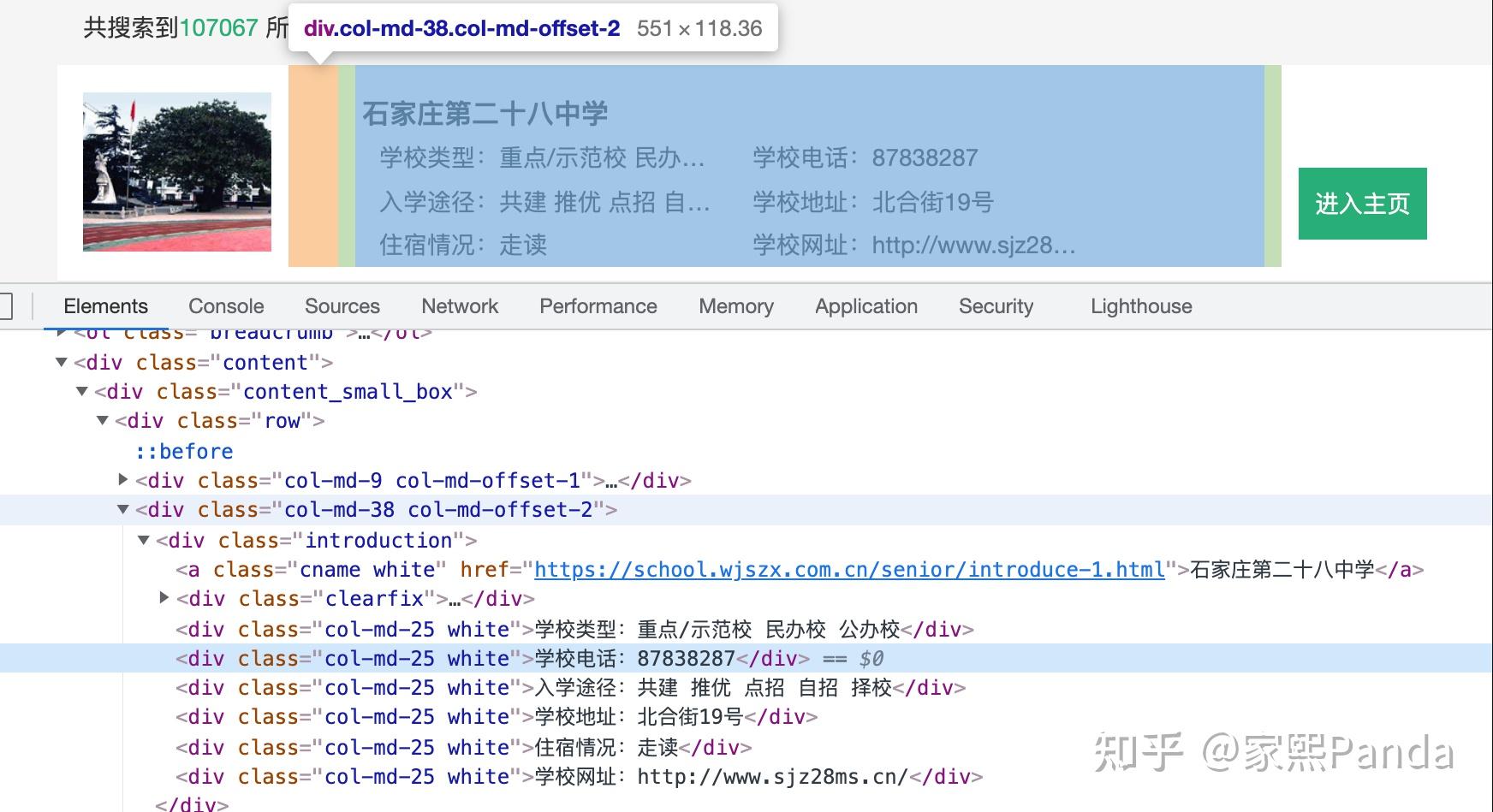
- 详情页的架构,可以看到设计的很粗糙...每个字段的title直接被赋成了变量,所以直接抓title名就行,也不用对字段就是处理了
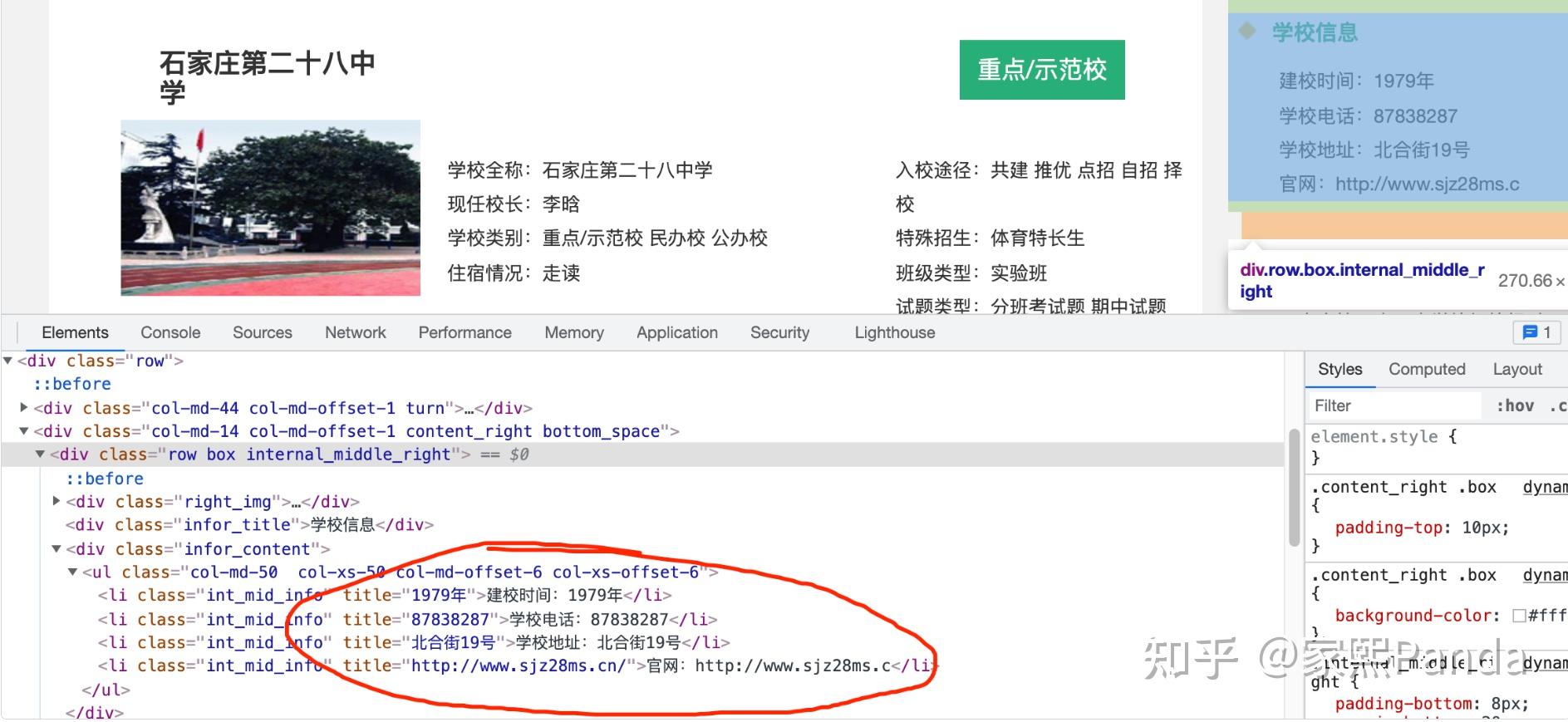
根据以上代码分析,我们会发现可能会有以下几个问题要注意:
- 编码格式问题 可能导致url取不到
- 直接抓下来数据的应该是dic类型,要去掉[]变为字段
- 没有信息的字段可能会有bug
先尝试简单抓取并计时,目的是为了观察直接暴力抓取是否可行:
for i in range(10000)
url = “https://school.wjszx.com.cn/senior/introduce-{}.html”.format(i)
spider(url)
class spider(url):
## 抓
return name, phone, address, url(或者return info)
class saving(info):
#打开已有的Excel
#打开sheet
#固定列 for循环一个字段存入行
#关闭Excel
分析与改进
- 因为抓到每页信息之后都要打开Excel存入再关闭,是I/O密集型操作,所以可以使用多线程提升速度。
- 因为python有GIIL锁,多线程有点麻烦。同时,此案例中I/O不容易发生阻塞,多协程应该会更快。
- 访问头headers要记得隐藏,数据大的时候要多写几个然后取随机。IP同理要使用IP池
- 因对方网站比较简陋,猜测没有太多反爬机制,隐藏了header再加上晚上开爬的话应该就没啥问题了
想要更快?使用scrapy爬虫框架
这里只介绍简单使用方法:
pip安装之后,在同级目录下
scrapy startproject stu
就会有一个scrapy的工程目录,spiders文件夹里是写爬虫的地方
yield大概相当于return
settings.py里有几个设置:
FEED_EXPORT_ENCODING = 'utf-8' ##改为utf-8
ROBOTSTXT_OBEY = True
CONCURRENT_REQUESTS = 100
CONCURRENT_REQUESTS_PER_DOMAIN = 100
CONCURRENT_REQUESTS_PER_IP = 100
#DOWNLOAD_DELAY = 3 ##高级点的网站的话要设置下载延迟,反爬
COOKIES_ENABLED = False
开始爬取:
scrapy crawl stu
开始爬取并把结果保存为stu.json:
scrapy crawl stu -o stu.json
3、 谷歌学术爬虫和某视频爬虫的demo版本:
https://github.com/JessyTsu1/google_scholar_spider
https://github.com/JessyTsu1/DouYinSpider
4、电商平台的数据收集
电商平台的数据收集是一个典型的应用场景,通过抓取商品信息和用户评论,可以进行市场分析和用户行为研究。
- 工具选择:利用Scrapy或GPT-Crawler抓取商品信息。
- 抓取内容:包括商品名称、价格、描述、用户评论等。
- 数据用途:分析市场趋势,了解竞争对手的定价策略,研究用户购买行为和偏好,为商家提供决策支持。
- 可能的案例:电商公司使用Scrapy抓取多个竞争对手网站的商品信息,结合内部销售数据进行市场分析,调整自身的产品定价策略,提升市场竞争力。
5、新闻网站的数据抓取
新闻网站的数据抓取主要用于获取最新新闻内容,训练新闻分类模型或生成模型。
- 工具选择:使用Selenium或Jina Reader获取最新新闻。
- 抓取内容:新闻标题、正文、发布时间、作者等。
- 数据用途:训练新闻分类模型,自动生成新闻摘要,进行舆情分析。
- 可能的案例:媒体公司使用Jina Reader抓取多个新闻网站的实时新闻,自动生成每日新闻摘要,发布到自家网站上,提高用户粘性和访问量。
6、社交网络的数据分析
社交网络的数据分析是通过抓取和分析用户关系和互动,提供社交行为洞察。
- 工具选择:通过Scrapegraph-AI抓取社交网络数据。
- 抓取内容:用户关系、互动频率、帖子内容、点赞和评论数据等。
- 数据用途:分析社交网络中的关键意见领袖(KOL),研究用户互动模式,进行社交营销策略制定。
- 可能的案例:市场研究公司使用Scrapegraph-AI抓取社交平台上的用户互动数据,分析关键意见领袖的影响力和粉丝互动情况,为客户制定精确的社交营销策略,提升品牌曝光和用户参与度。
这些实际案例展示了不同爬虫工具在不同应用场景中的实际操作和效果,帮助更好地理解如何选择和使用爬虫工具进行有效的数据收集。
二、公开数据集
在科研工作中,研究人员往往因为各种原因无法通过爬虫直接获取数据,同时科研领域通常有固定的基准测试数据集(benchmark),以便研究者针对特定目标进行优化。在这种情况下,开源数据集成为了重要的资源,供研究者使用和打榜。
公开数据集是大语言模型训练中的重要数据来源之一,来自各种科研机构、政府机构和开源社区。选择和评估公开数据集时,需要考虑数据集的质量、规模和多样性,以确保训练模型的效果。
来源和类型
公开数据集可以从以下几类来源获取:
- 科研机构:许多大学和研究所发布了大量高质量的研究数据集,这些数据集通常用于学术研究和实验。例如,斯坦福大学、麻省理工学院等机构经常发布机器学习和人工智能领域的公开数据集。
- 政府机构:政府部门提供的大量公开数据集涵盖了经济、社会、环境等多个领域,这些数据集可以用于各种分析和研究。例如,美国政府的数据门户网站Data.gov就提供了丰富的公开数据资源。
- 开源社区:开源社区和项目贡献了大量的数据集,这些数据集通常是由开发者和研究人员共同维护和更新的。例如GitHub、ModelScope、HuggingFace
评估和选择标准
在选择公开数据集时,以下标准是关键考虑因素:
- 数据集质量:数据的准确性和完整性是评估数据集质量的主要指标。高质量的数据集应当经过严格的数据清洗和验证,以确保数据的可靠性。
- 数据集规模:数据集的规模影响模型的训练效果。规模越大的数据集,通常可以为模型提供更多的训练样本,从而提高模型的泛化能力。
- 数据集多样性:多样性是确保模型能够处理不同场景和任务的重要因素。一个多样化的数据集应包含不同类型的数据样本,涵盖各种可能的输入情况。
常用平台和资源
以下是一些常用的公开数据集平台和资源:
- Kaggle:Kaggle是一个数据科学竞赛平台,提供了大量高质量的公开数据集。用户可以在Kaggle上找到各种机器学习和数据科学项目中常用的数据集,并参与社区讨论和竞赛。
- UCI Machine Learning Repository:UCI机器学习数据集库是一个历史悠久的数据集资源,包含了多种多样的机器学习数据集,适用于各类算法和模型的训练和测试。
- Google Dataset Search:Google Dataset Search是一个专门用于搜索公开数据集的工具,用户可以通过该工具轻松查找和获取各类公开数据集,覆盖了广泛的领域和应用场景。
实际使用案例
公开数据集在特定项目中的应用可以显著提升数据收集和模型训练的效率和效果。以下是一些实际使用案例:
- 自然语言处理任务:在自然语言处理(NLP)任务中,可以使用Kaggle上的文本数据集来训练语言模型。例如,使用Quora Question Pairs数据集来训练一个问答系统,通过识别和分类相似的问题,提高系统的回答准确性。
- 计算机视觉任务:在计算机视觉领域,可以利用UCI机器学习数据集库中的图像数据集来训练图像分类或物体检测模型。例如,使用CIFAR-10数据集训练一个图像分类模型,用于识别和分类日常生活中的物体。
- 社会经济分析:政府机构提供的公开数据集可以用于社会经济分析和研究。例如,使用Data.gov上的人口普查数据进行社会经济状况的分析和预测,帮助政府和企业制定决策和政策。
通过这些实际案例,可以看到公开数据集在不同项目中的广泛应用和重要性。合理选择和使用公开数据集,能够有效提升模型的训练效果和应用价值。
大语言模型预训练数据集
在预训练阶段,LLM从大量未标记的文本数据中学习广泛的知识,然后将这些知识存储在其模型参数中。这使得LLM具备一定水平的语言理解和生成能力。
网页、学术材料、书籍,各个领域的相关文本,如法律文件、年度财务报告、医学教材等都是预训练的语料集
我们通常将预训练数据集分为两类:通用数据集和领域数据集。
通用预训练数据集,通常包括来自互联网的文本内容,如新闻、社交媒体、百科全书等。其目标是为NLP任务提供通用的语言知识和数据资源。
领域预训练数据集,其目的是为LLM提供专业知识。比如裁判文书、各学科书籍等。
值得一提的是,通过在预训练数据里加入math和code数据可以大幅增强模型的推理能力。
书籍数据
书籍是优质的未经标注的预训练数据,要考虑使用书籍作为预训练数据的话,不可避免地需要去研究图书分类,这让我们可以在需要加强模型特定领域能力时轻松选择相关书籍数据
参考阮一峰老师的文章 https://www.ruanyifeng.com/blog/2007/01/classification.html
书籍可以这样分类:
一、中图分类法(第四版)(CLC,Chinese Library Classification)
A马克思主义、列宁主义、毛泽东思想、邓小平理论 B哲学、宗教 C 社会科学总论 D 政治、法律 F 经济 G 文化、科学、教育、体育 H 语言、文字 I 文学 J 艺术 K 历史、地理 N 自然科学总论 O 数理科学和化学 Q 生物科学 R 医药、卫生 S 农业科学 T 工业技术 U 交通运输 V 航空、航天 X 环境科学、安全科学 Z 综合性图书 二、美国国会图书馆分类法(LCC,Library of Congress Classification)
A - GENERAL WORKS
B - PHILOSOPHY. PSYCHOLOGY. RELIGION
C - AUXILIARY SCIENCES OF HISTORY
D - HISTORY (GENERAL) AND HISTORY OF EUROPE
E - HISTORY: AMERICA
F - HISTORY: AMERICA
G - GEOGRAPHY. ANTHROPOLOGY. RECREATION
H - SOCIAL SCIENCES
J - POLITICAL SCIENCE
K - LAW
L - EDUCATION
M - MUSIC AND BOOKS ON MUSIC
N - FINE ARTS
P - LANGUAGE AND LITERATURE
Q - SCIENCE
R - MEDICINE
S - AGRICULTURE
T - TECHNOLOGY
U - MILITARY SCIENCE
V - NAVAL SCIENCE
Z - BIBLIOGRAPHY. LIBRARY SCIENCE. INFORMATION RESOURCES (GENERAL)
三、杜威十进制分类法(DDC,Dewey Decimal Classification)
000 Generalities
100 Philosophy & psychology
200 Religion
300 Social sciences
400 Language
500 Natural sciences & mathematics
600 Technology (Applied sciences)
700 The arts
800 Literature & rhetoric
900 Geography & history
学术、互联网资料
- arXiv10,收集了物理、数学、计算机科学、生物学和定量经济学等领域的论文预印本。这不仅提供了高质量的学术知识,还使模型能够掌握论文的LATEX格式。
- S2ORC(Lo等,2020年)涵盖了各学科的英文学术论文。它具有广泛的元数据、摘要、参考文献列表和结构化的全文内容。
- WikiText这是一个基于维基百科的数据集,专为语言建模任务设计。WikiText数据集具有高质量的文章文本,用于测试语言建模算法。
- Common Crawl这是一个庞大的网页数据集,每月抓取超过20亿个网页。它被用于训练一些最大的语言模型,如OpenAI的GPT系列和其他多种NLP任务。
- BookCorpus包含从未出版书籍中收集的文本,广泛用于自然语言处理研究。它帮助模型理解更长的文本依赖关系。
- Pushshift.io Reddit Dataset由Pushshift提供的Reddit数据,用于多种NLP研究,包括语言模型的预训练。这个数据集包含了Reddit上的大量帖子和评论。
- PubMed Central11在近500万生物医学出版物的开放获取中发挥了作用。
- The Pile由EleutherAI开发的一个大型语言模型训练数据集,包含多种数据源,例如GitHub、PubMed、ArXiv等。这个数据集旨在提供多样化且广泛的文本,用于训练语言模型。
- MNBVC 里屋社区大规模中文语料集。对标chatGPT训练的40T数据,目前已有33065GB (截止2024年5月30日)
大语言模型微调数据集
指令微调数据集用于进一步微调预训练的大型语言模型(LLMs),使模型能更好地理解和遵循人类指令。这一过程有助于弥合LLMs的next token的预测目标与让LLMs遵循人类指令的目标之间的差距,从而增强LLMs的能力和可控性。
SFT数据集按照instruction的类型可以分为两类:QA咨询数据集和agent子任务数据集
QA咨询数据集:
没有特定的instruction,只需要让模型按照咨询的方式去回复,被定义为QA咨询数据集,如:
{
"instruction": "",
"input": "我今天出门被车撞了怎么办",
"output": """非常抱歉听到这个消息,希望你没有受到严重的伤害。这里有一些步骤你可能需要考虑:
寻求医疗帮助:即使你觉得伤势不重,有时候一些内伤可能不会立即显现。最好去医院或诊所进行全面检查。
报警:如果还没有报警,你应该立即联系当地警方,让他们来现场做记录。这对于以后可能的索赔或法律程序非常重要。
记录证据:如果可能的话,拍照记录事故现场、车辆、伤势等。如果有目击者,尽量获取他们的联系信息。
联系保险公司:尽快通知你的保险公司发生的事故,根据他们的指引进行下一步。
法律咨询:考虑咨询律师了解你的权利和可能的赔偿。
希望你能尽快恢复,如果需要进一步的帮助或信息,随时告诉我!"""
}
这种数据集不需要模型完成特定的任务,只需要模型学到output的逻辑和样式即可。值得一提的是,如果使用大量领域咨询数据集进行训练,比如医疗咨询,则会让模型的回复带有医疗模型的特征
agent子任务数据集
通过特定的instruction,提前定义若干种任务类型,从而让模型学到相应任务的表达方式的数据集,被定义为agent子任务数据集。如:
{
"instruction":"你是一个经验丰富的多国语言翻译官,请将以下文字翻译成中国古诗词,要求信达雅",
"input":"Of course I still love you",
"output":"纵使万里云舒,吾心犹存"
},
//Tips: from Elon Musk, SpaceX
{
"instruction":"请对以下涉及法律领域的问题提出进一步追问,以获取更多相关信息:",
"input":"父亲娶了继母生了儿子。父亲生病,财产全部给了儿子。继母说我和这个儿子同样共同赡养老人怎么维护自己?",
"output":"1. 请问您是否与父亲和继母有过任何的书面或口头协议,关于财产分配和赡养老人的事宜?\n2. 您是否有证据证明您对于赡养老人做出了贡献?例如,支付了医疗费用、提供了日常生活上的帮助等。\n3. 您是否有其他证据证明父亲在分配财产时存在不公平的情况?例如,是否有遗嘱或财产转移记录等。\n4. 您是否已经与继母进行过沟通或协商,试图解决这个问题?\n5. 您是否已经咨询过律师或其他法律专业人士的意见,以了解您的权益和可能的维护方式?"
},
{
"instruction":"将下列信息中的法律关键词提出:",
"input":"因银行卡被盗刷造成的损失赔偿责任认定",
"output":"银行卡纠纷;伪卡交易;责任分配;民事诉讼;合同;"
},
InstructGPT-sft(Ouyang等人,2022)将这部分数据集分为10个类别,分别是生成、开放式问答、头脑风暴、聊天、重写、总结、分类、其他、封闭式问答和提取。
BELLE train 3.5M CN(BELLEGroup,2023)在此基础上增加了角色扮演、数学、翻译、编码和无害类别,同时移除了聊天和其他类别。
Firefly(Yang,2023)进一步细化了指令类别,涵盖了23个类别。例如故事生成和歌词生成等类别属于原始“生成”类别的子类别。考虑到当前的分类状态并仅关注单轮对话指令,将指令广泛分为15个类别:推理、数学、头脑风暴、封闭式问答、开放式问答、编码、提取、生成、重写、总结、翻译、角色扮演、社会规范和其他。
观察以上任务类别我们可以得出一个有趣的结论:训练领域大模型,关键在于尽可能多的细化agent子任务数据集,随后选用一个通用能力还不错的模型加上领域SFT数据集即可以得到一个看起来可以解决该领域所有问题的领域大模型。
而DataTager便是为了解决SFT数据集生成的问题的产品。
三、合作伙伴数据
在数据收集过程中,与合作伙伴合作是一种非常有效的方式,可以获取高质量、定制化的数据。这种合作能够为特定项目提供高度相关的样本,并保证数据的质量和可靠性。
合作的好处
与合作伙伴合作进行数据收集有以下几个主要好处:
- 定制化数据:合作伙伴能够根据具体需求提供量身定制的数据集。这些数据通常更贴合项目的实际需求,提高模型的训练效果和应用效果。
- 数据质量保证:合作伙伴通常具备专业的数据收集和处理能力,能够提供经过严格验证和清洗的高质量数据,减少数据噪音和错误,提高模型的准确性和可靠性。
选择合作伙伴的标准
在选择合作伙伴时,需要考虑以下几个标准,以确保合作能够顺利进行并取得预期效果:
- 信誉:选择信誉良好的合作伙伴,他们在数据质量和合作可靠性方面更有保障。
- 数据相关性:合作伙伴提供的数据应与项目需求高度相关。
- 技术能力:合作伙伴在数据收集、处理和管理方面的技术能力至关重要。
案例分析
以下是一些成功的合作伙伴数据收集实例,以及合作过程中遇到的挑战和解决方案:
- 成功合作的具体实例:
- 在医疗领域,研究机构与大型医院合作,获取患者数据用于训练疾病预测模型。通过合作,研究机构能够获取到真实的医疗数据,显著提高了模型的预测精度。
- 在电商领域,电商平台与供应商合作,分享产品销售数据和用户行为数据。通过合作,电商平台能够更好地了解市场需求和用户偏好,优化产品推荐和营销策略。
- 面临的挑战和解决方案:
- 数据隐私和安全:在合作过程中,数据隐私和安全是首要挑战。为了解决这一问题,可以采用数据去标识化和加密技术,确保敏感信息不被泄露。此外,双方需签署严格的保密协议,明确数据使用和保护的责任和义务。
- 数据格式和兼容性:不同合作伙伴的数据格式可能存在差异,导致数据整合困难。为此,可以采用标准化的数据格式和接口,确保数据在收集和处理过程中的兼容性和一致性。
- 沟通和协调:合作过程中,双方需要保持良好的沟通和协调,确保项目目标和数据需求的一致性。定期召开会议和交流,及时解决合作中的问题和挑战,是成功合作的重要保障。
“置信度”
之所以加引号,因为这是我自己起的名字,是我创业一年以来的感受。
在法律、医疗、教育、金融等领域,即使我们想要做对普通人有用的C端产品,模型的效果做得很好,但用户在咨询结束后可能会有一个担忧,那就是你给出的回复是否有知名组织和机构的背书。比如协和医院、红圈所、罗翔、幻方等知名机构的背书能显著提升用户的信任感。我把这个叫做“置信度”。
- 提高置信度的必要性:为了提高用户的信任度,我们需要与这些知名机构合作,获取他们的数据和认可。哪怕是做C端产品,因为行业的特点,我们需要为了“置信度”而努力。因此,我们不可避免地要与许多大型企业(大B)和政府机构(大G)打交道。
通过与合作伙伴的紧密合作,可以获取高质量、定制化的数据,显著提升模型的训练效果和实际应用价值。同时,与知名机构的合作可以提高用户对产品的信任度(置信度),为C端产品在市场上的成功奠定坚实基础。在选择合作伙伴和解决合作过程中遇到的挑战时,需要综合考虑信誉、数据相关性和技术能力等因素,确保合作顺利进行。
四、众包平台
众包平台是一种通过大众力量收集和处理数据的有效方法。在这种模式下,任务被分配给大量的在线工作者,他们完成任务并反馈数据。众包数据收集在大语言模型训练中具有重要的应用价值。
概念和工作原理
- 众包数据收集的基本模式:众包平台将大规模的数据收集任务分解为多个小任务,然后分配给众多在线工作者。这些工作者完成任务后提交数据,平台对数据进行汇总和验证。这种模式不仅能够快速收集大量数据,还可以涵盖多样性的数据来源。
优点和缺点
- 优点:
- 数据多样性:众包平台能够从全球范围内的工作者那里收集数据,确保数据的多样性和广泛覆盖。
- 快速收集:通过众包方式,能够在短时间内完成大量数据的收集任务,尤其适合需要快速获取大量数据的项目。
- 缺点:
- 数据质量控制:由于众包平台上的工作者背景和能力各异,数据质量可能参差不齐。需要有效的质量控制机制来确保数据的准确性和一致性。
- 管理和协调:管理和协调大量工作者的任务需要付出额外的努力,制定明确的任务标准和验证流程。
| 众包平台 | |
|---|---|
| 优点 | 数据多样性:能够从全球范围内的工作者收集数据,确保数据的多样性和广泛覆盖。 快速收集:能够在短时间内完成大量数据的收集任务。 |
| 缺点 | 数据质量控制:由于工作者背景和能力各异,数据质量可能参差不齐。 管理和协调:管理和协调大量工作者的任务需要付出额外的努力。 |
常用平台
以下是一些常用的众包平台,它们在数据收集和处理方面具有丰富的经验和广泛的应用:
- Amazon Mechanical Turk:MTurk是一个广泛使用的众包平台,提供了各种类型的数据收集和处理任务。用户可以通过MTurk发布任务,获取来自全球工作者的数据。

- Figure Eight(原CrowdFlower):Figure Eight是一个专业的众包平台,提供数据标注、清洗和验证等服务,广泛应用于机器学习和人工智能项目。
- Appen:Appen是一家知名的众包平台,专注于提供高质量的数据收集和标注服务,尤其在语言数据和图像数据的处理方面具有优势。
实际使用案例
众包平台在大语言模型训练中的应用非常广泛,以下是一些实际使用案例:
- 文本标注:在大语言模型的训练过程中,需要大量的标注文本数据。使用Amazon Mechanical Turk,研究人员可以发布文本分类、情感分析等任务,快速获取大量标注好的文本数据。这些数据可以用于训练和评估大语言模型。
- 对话数据收集:大语言模型需要丰富的对话数据来训练对话生成能力。通过Figure Eight,企业可以发布对话数据收集任务,获取多样化的对话数据,用于训练对话模型。
- 语言数据采集:为了提高大语言模型的多语言处理能力,需要收集不同语言的文本数据。Appen提供的多语言数据采集服务,可以帮助收集来自不同地域、不同语言的文本样本,支持多语言模型的训练和优化。
众包平台在大语言模型的数据收集和标注方面提供了强有力的支持。通过合理利用这些平台,可以高效地获取多样化、高质量的数据,为大语言模型的训练提供坚实的基础。同时,众包平台的快速响应和大规模数据处理能力,能够满足大语言模型训练对数据的高需求。
五、数据存储格式
在数据收集和处理过程中,选择合适的数据存储格式对于确保数据的可用性和处理效率至关重要。常见的数据存储格式包括JSON、JSONL、CSV和XML,此外还有其他一些格式,如Parquet、Avro和HDF5,每种格式都有其优缺点。
常见格式
- JSON:JavaScript Object Notation,一种轻量级的数据交换格式,易于阅读和编写。
- JSONL:JSON Lines,每行一个JSON对象,适用于大数据集的逐行处理。
- CSV:Comma-Separated Values,纯文本格式,用于存储表格数据。
- XML:eXtensible Markup Language,一种可扩展的标记语言,广泛用于数据交换和存储。
- Parquet:一种列式存储格式,适用于大数据处理,特别是Apache Hadoop生态系统。
- Avro:一种行式存储格式,支持数据序列化和模式演化,适用于数据流和大数据处理。
- HDF5:Hierarchical Data Format,一种用于存储和管理大规模数据的格式,广泛用于科学计算和机器学习。
优缺点对比
| 格式 | 可读性 | 解析效率 | 存储空间 | 其他特性 |
|---|---|---|---|---|
| JSON | 易读易写,结构清晰 | 解析速度适中 | 比CSV大,但比XML小 | 易于使用,广泛支持 |
| JSONL | 易于逐行处理 | 解析速度快 | 适中 | 适合大规模数据处理 |
| CSV | 简单易读,但结构信息少 | 解析速度快 | 最小 | 易于处理,广泛使用 |
| XML | 可读性好,但冗长 | 解析速度慢 | 最大,包含大量标签信息 | 自描述性强,支持复杂结构 |
| Parquet | 可读性较差 | 解析速度快,适用于列式读取 | 压缩效率高,占用空间小 | 列式存储,适合大数据分析 |
| Avro | 可读性一般 | 解析速度快 | 压缩效率高,占用空间小 | 支持数据模式演化,适合流处理 |
| HDF5 | 可读性较差 | 解析速度快 | 高效存储大规模数据 | 支持复杂数据结构和多维数组 |
实际使用建议
在选择数据存储格式时,需要根据具体的使用场景和需求进行权衡。以下是一些实际使用建议:
- JSON:适用于结构化数据,特别是需要嵌套和复杂数据结构的场景。常用于API数据交换和配置文件。
- 案例:用于存储用户配置和应用程序设置,数据结构清晰,便于解析和修改。
- JSONL:适合大规模数据处理,特别是逐行读取和处理的大数据集。常用于日志文件和数据流处理。
- 案例:用于存储大规模日志数据,每行一个JSON对象,便于快速解析和处理。
- CSV:适用于简单的表格数据,特别是需要高效存储和快速读取的场景。常用于数据分析和报表生成。
- 案例:用于存储和处理大型数据集,如销售记录和用户数据,解析速度快,占用空间小。
- XML:适用于需要高度可读性和自描述的数据,常用于文档格式和数据交换标准。
- 案例:用于文档存储和配置文件,数据结构清晰,但解析速度较慢,文件较大。
- Parquet:适用于大数据处理,特别是需要列式存储和高效压缩的场景。常用于数据仓库和大数据分析。
- 案例:在Hadoop和Spark环境中使用,进行高效的数据存储和分析。
- Avro:适用于需要数据序列化和模式演化的场景,常用于数据流和大数据处理。
- 案例:用于Kafka和Hadoop中的数据交换和存储,支持高效的数据流处理。
- HDF5:适用于科学计算和机器学习中的大规模数据存储和管理,支持复杂数据结构和多维数组。
- 案例:用于存储和处理科学数据,如天文观测数据和机器学习训练数据。
通过合理选择数据存储格式,可以有效提升数据处理效率,确保数据的可读性和可维护性。根据具体的应用场景和需求,选择最合适的数据格式,有助于提高数据管理和使用的整体效果。
六、数据收集注意事项
在数据收集过程中,需要特别注意数据隐私和合规性,同时要确保数据的质量和一致性。以下是一些关键的注意事项。
数据隐私和合规性
在数据收集和处理过程中,必须遵守相关的数据隐私法规,确保数据的合法性和用户隐私的保护。
- GDPR(General Data Protection Regulation):欧盟的通用数据保护条例,要求在处理欧盟居民的数据时,必须获得明确的用户同意,并确保数据的安全性和隐私性。
- CCPA(California Consumer Privacy Act):加州消费者隐私法案,保护加州居民的个人数据隐私,赋予消费者更多的控制权和知情权。
- 其他相关法规:各国和地区的隐私保护法规可能有所不同,需要根据具体情况进行遵守和适应。
数据清洗和预处理
数据清洗和预处理是确保数据质量的重要步骤,通过清洗和预处理,可以去除数据中的噪音和错误,提高数据的准确性和一致性。
- 数据清洗:包括去除重复数据、修正错误数据、填补缺失值等。可以使用各种数据清洗工具和技术,如Pandas、OpenRefine等。
- 案例:使用Pandas库对CSV文件中的数据进行清洗,去除重复行,修正格式错误,并填补缺失值,确保数据的完整性和准确性。
- 数据预处理:包括标准化、归一化、特征提取等步骤。预处理后的数据更适合用于模型训练和分析。
- 案例:在训练机器学习模型之前,对数据进行标准化处理,将所有特征缩放到相同的范围内,避免特征值差异过大影响模型效果。
去重和标准化
在数据收集中,去重和标准化是避免数据冗余和不一致的重要步骤。
- 去重:通过检查和去除重复数据,可以减少数据冗余,提高数据处理效率和模型的训练效果。
- 案例:在用户数据收集中,通过检查用户ID和其他唯一标识符,去除重复的用户记录,确保每个用户的数据都是唯一的。
- 标准化:将数据转换为统一的格式,确保数据的一致性和可比较性。标准化包括格式转换、单位转换等。
- 案例:在多源数据集成过程中,将所有日期格式统一为ISO 8601标准格式,确保不同数据源的日期信息一致。
通过遵守数据隐私法规、进行有效的数据清洗和预处理、以及执行去重和标准化操作,可以显著提高数据的质量和一致性,为后续的数据分析和模型训练打下坚实的基础。
七、数据存储与管理
云存储 vs 本地存储
- 云存储:通过第三方服务提供商(如AWS、Google Cloud、Microsoft Azure)提供的存储解决方案。云存储具有高可扩展性和灵活性,适用于大规模数据存储和处理。
- 优点:弹性扩展、高可用性、无需自行维护硬件设备。
- 缺点:成本随存储量和使用频率增加、安全性依赖于第三方服务提供商。
- 案例:使用Amazon S3存储大规模训练数据,通过其强大的数据管理和分发功能,支持大语言模型的训练。
- 本地存储:通过企业或个人自行搭建和维护的存储设备(如NAS、SAN)进行数据存储。
- 优点:完全控制数据和硬件、无需担心外部服务中断。
- 缺点:扩展性有限、需要自行维护和管理。
- 案例:某科研机构使用本地存储设备存储敏感研究数据,确保数据安全和隐私。
分布式数据库
- 分布式数据库:用于存储和管理大规模数据的数据库系统,通过多个节点分布式存储和处理数据,提供高性能和高可用性。
- 优点:高可扩展性、高可靠性、支持大规模并发访问。
- 缺点:部署和管理复杂、数据一致性和延迟需要优化。
- 案例:使用Apache Cassandra存储和管理分布式数据,支持大规模实时数据处理和分析。
最佳实践
数据标签和元数据管理
- 数据标签:对数据进行分类和标记,便于数据的检索和管理。
- 案例:对大语言模型训练数据进行标签管理,标记数据来源、类别和使用场景,便于后续的检索和使用。
- 元数据管理:管理描述数据的数据,包括数据来源、创建时间、格式等信息,确保数据的完整性和可追溯性。
- 案例:建立元数据管理系统,记录每个数据集的详细信息,确保数据在整个生命周期内的管理和使用。
数据版本控制
- 数据版本控制:对数据进行版本管理,记录数据的变化历史,确保数据的可追溯性和一致性。
- 案例:使用DVC(Data Version Control)工具对训练数据进行版本控制,记录每次数据更新和变化,确保模型训练过程中使用的数据一致。
参考资料:
https://x.com/vikingmute/status/1737296571354743268
https://timconnors.co/posts/ai-scraper
https://zhuanlan.zhihu.com/p/692683234
https://zhuanlan.zhihu.com/p/669816705
https://zhuanlan.zhihu.com/p/693096151
代理池,要使用redis启动起来 https://github.com/Python3WebSpider/ProxyPool
https://blog.csdn.net/gyt15663668337/article/details/86345690
scrapy的简单介绍 https://vip.fxxkpython.com/?p=5038






