diff --git a/.gitattributes b/.gitattributes
index a6344aac8c09253b3b630fb776ae94478aa0275b..ae8aad9cc91dc7860acf5c73587be10ccd047262 100644
--- a/.gitattributes
+++ b/.gitattributes
@@ -33,3 +33,13 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
*.zip filter=lfs diff=lfs merge=lfs -text
*.zst filter=lfs diff=lfs merge=lfs -text
*tfevents* filter=lfs diff=lfs merge=lfs -text
+assets/cat_2x.gif filter=lfs diff=lfs merge=lfs -text
+assets/clear2rainy_results.jpg filter=lfs diff=lfs merge=lfs -text
+assets/day2night_results.jpg filter=lfs diff=lfs merge=lfs -text
+assets/edge_to_image_results.jpg filter=lfs diff=lfs merge=lfs -text
+assets/examples/bird.png filter=lfs diff=lfs merge=lfs -text
+assets/fish_2x.gif filter=lfs diff=lfs merge=lfs -text
+assets/gen_variations.jpg filter=lfs diff=lfs merge=lfs -text
+assets/night2day_results.jpg filter=lfs diff=lfs merge=lfs -text
+assets/rainy2clear.jpg filter=lfs diff=lfs merge=lfs -text
+assets/teaser_results.jpg filter=lfs diff=lfs merge=lfs -text
diff --git a/LICENSE b/LICENSE
new file mode 100644
index 0000000000000000000000000000000000000000..a39b489fea3c97ac6fde21d42f196198c22607da
--- /dev/null
+++ b/LICENSE
@@ -0,0 +1,21 @@
+MIT License
+
+Copyright (c) 2024 img-to-img-turbo
+
+Permission is hereby granted, free of charge, to any person obtaining a copy
+of this software and associated documentation files (the "Software"), to deal
+in the Software without restriction, including without limitation the rights
+to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
+copies of the Software, and to permit persons to whom the Software is
+furnished to do so, subject to the following conditions:
+
+The above copyright notice and this permission notice shall be included in all
+copies or substantial portions of the Software.
+
+THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
+IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
+FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
+AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
+LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
+OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
+SOFTWARE.
diff --git a/README.md b/README.md
new file mode 100644
index 0000000000000000000000000000000000000000..bb9ecaa62cfac7924286f3a091d261de48c4caea
--- /dev/null
+++ b/README.md
@@ -0,0 +1,228 @@
+# img2img-turbo
+
+[**Paper**](https://arxiv.org/abs/2403.12036) | [**Sketch2Image Demo**](https://huggingface.co/spaces/gparmar/img2img-turbo-sketch)
+#### **Quick start:** [**Running Locally**](#getting-started) | [**Gradio (locally hosted)**](#gradio-demo) | [**Training**](#training-with-your-own-data)
+
+### Cat Sketching
+
+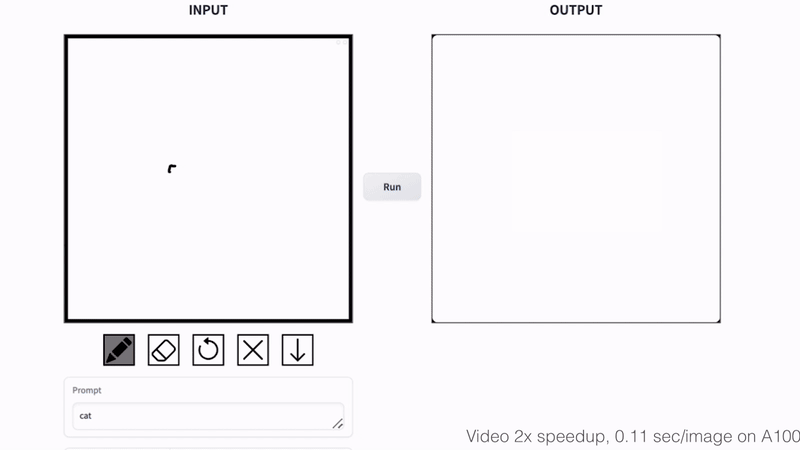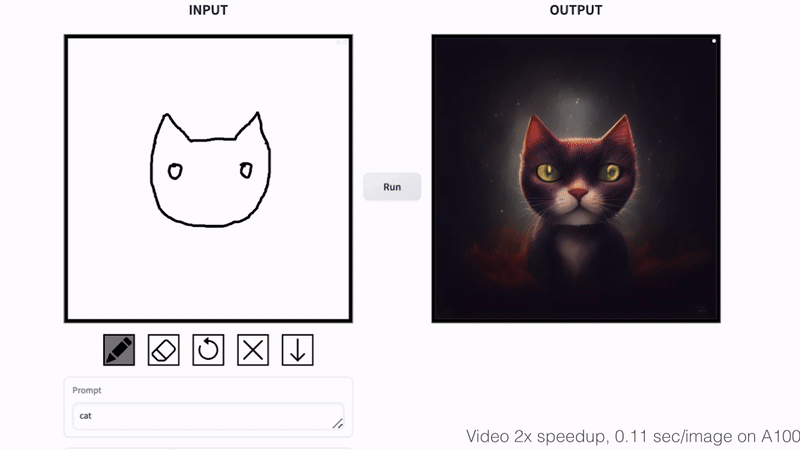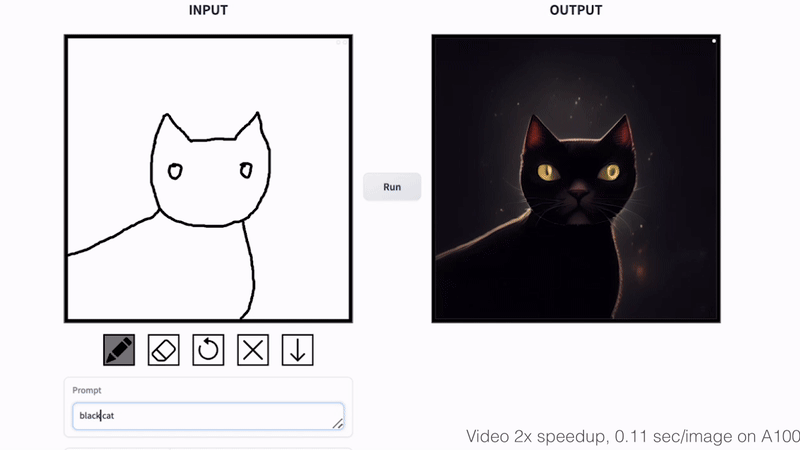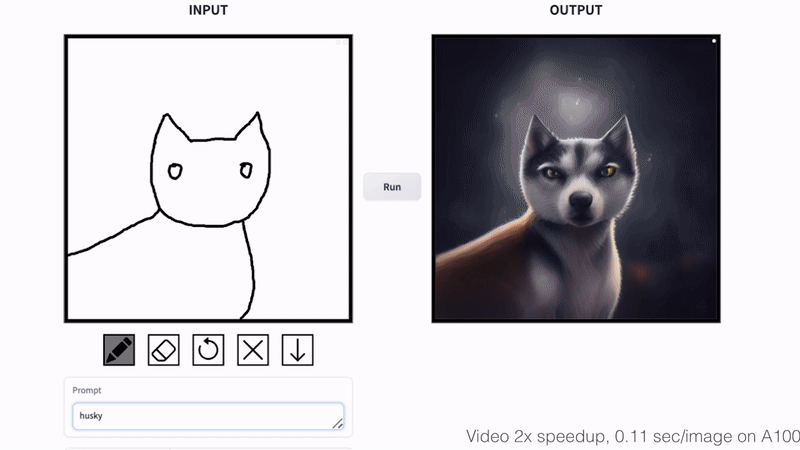 +
+
+
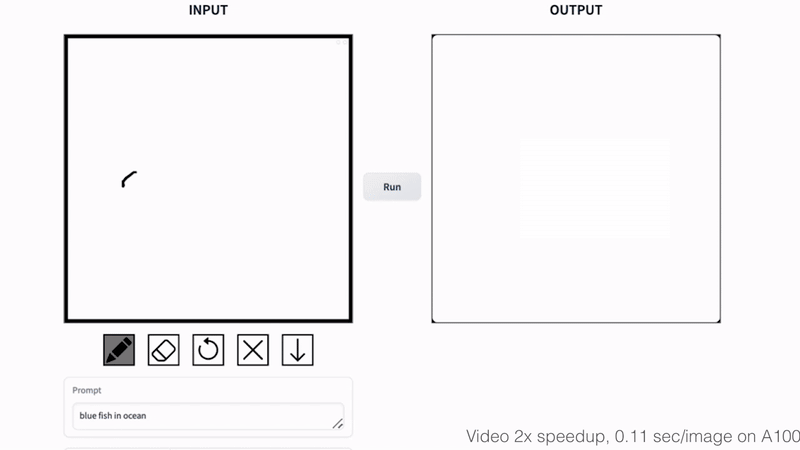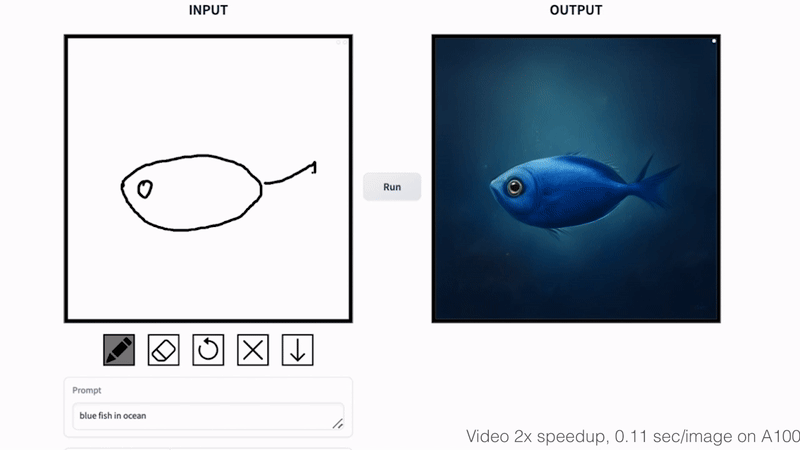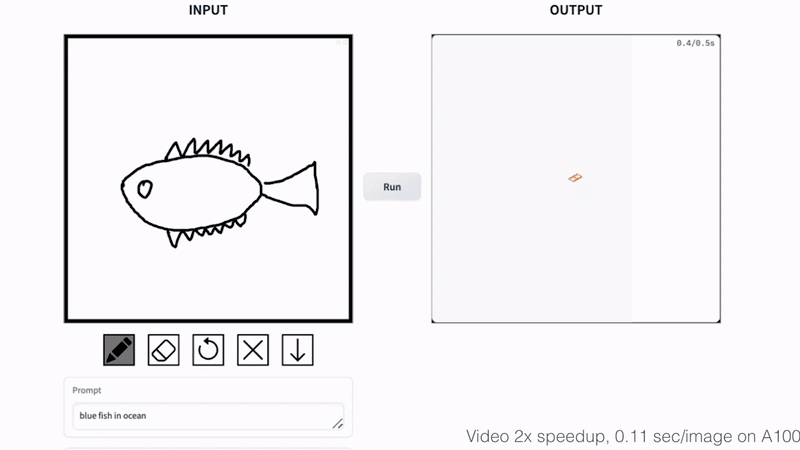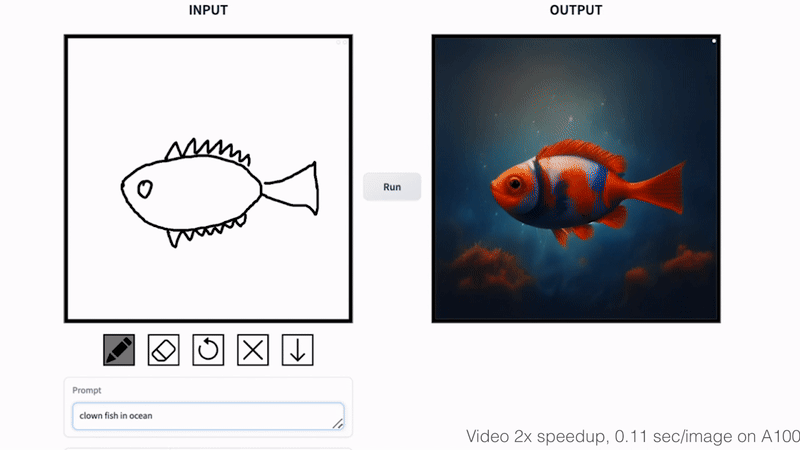
+### Fish Sketching
+
+ +
+
+
+
+We propose a general method for adapting a single-step diffusion model, such as SD-Turbo, to new tasks and domains through adversarial learning. This enables us to leverage the internal knowledge of pre-trained diffusion models while achieving efficient inference (e.g., for 512x512 images, 0.29 seconds on A6000 and 0.11 seconds on A100).
+
+Our one-step conditional models **CycleGAN-Turbo** and **pix2pix-turbo** can perform various image-to-image translation tasks for both unpaired and paired settings. CycleGAN-Turbo outperforms existing GAN-based and diffusion-based methods, while pix2pix-turbo is on par with recent works such as ControlNet for Sketch2Photo and Edge2Image, but with one-step inference.
+
+[One-Step Image Translation with Text-to-Image Models](https://arxiv.org/abs/2403.12036)
+[Gaurav Parmar](https://gauravparmar.com/), [Taesung Park](https://taesung.me/), [Srinivasa Narasimhan](https://www.cs.cmu.edu/~srinivas/), [Jun-Yan Zhu](https://github.com/junyanz/)
+CMU and Adobe, arXiv 2403.12036
+
+
+
+
+ +
+
+
+
+ +
+
+
+ +
+
+
+### Unpaired Translation with CycleGAN-Turbo
+
+**Day to Night**
+
+ +
+
+
+**Night to Day**
+
+ +
+
+
+ +
+
+
+
+ +
+
+
+
+
+## Method
+**Our Generator Architecture:**
+We tightly integrate three separate modules in the original latent diffusion models into a single end-to-end network with small trainable weights. This architecture allows us to translate the input image x to the output y, while retaining the input scene structure. We use LoRA adapters in each module, introduce skip connections and Zero-Convs between input and output, and retrain the first layer of the U-Net. Blue boxes indicate trainable layers. Semi-transparent layers are frozen. The same generator can be used for various GAN objectives.
+
+
+ +
+
+
+ | Input Image |
+ Canny Edges |
+ Model Output |
+
+
+  |
+  |
+  |
+
+
+
+
+- The following command takes a sketch and a prompt as inputs, and saves the results in the directory specified.
+ ```bash
+ python src/inference_paired.py --model_name "sketch_to_image_stochastic" \
+ --input_image "assets/examples/sketch_input.png" --gamma 0.4 \
+ --prompt "ethereal fantasy concept art of an asteroid. magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy" \
+ --output_dir "outputs"
+ ```
+
+ | Input |
+ Model Output |
+
+
+  |
+  |
+
+
+
+
+**Unpaired Image Translation (CycleGAN-Turbo)**
+- The following command takes a **day** image file as input, and saves the output **night** in the directory specified.
+ ```
+ python src/inference_unpaired.py --model_name "day_to_night" \
+ --input_image "assets/examples/day2night_input.png" --output_dir "outputs"
+ ```
+
+ | Input (day) |
+ Model Output (night) |
+
+
+  |
+  |
+
+
+
+- The following command takes a **night** image file as input, and saves the output **day** in the directory specified.
+ ```
+ python src/inference_unpaired.py --model_name "night_to_day" \
+ --input_image "assets/examples/night2day_input.png" --output_dir "outputs"
+ ```
+
+ | Input (night) |
+ Model Output (day) |
+
+
+  |
+  |
+
+
+
+- The following command takes a **clear** image file as input, and saves the output **rainy** in the directory specified.
+ ```
+ python src/inference_unpaired.py --model_name "clear_to_rainy" \
+ --input_image "assets/examples/clear2rainy_input.png" --output_dir "outputs"
+ ```
+
+ | Input (clear) |
+ Model Output (rainy) |
+
+
+  |
+  |
+
+
+
+- The following command takes a **rainy** image file as input, and saves the output **clear** in the directory specified.
+ ```
+ python src/inference_unpaired.py --model_name "rainy_to_clear" \
+ --input_image "assets/examples/rainy2clear_input.png" --output_dir "outputs"
+ ```
+
+ | Input (rainy) |
+ Model Output (clear) |
+
+
+  |
+  |
+
+
+
+
+
+## Gradio Demo
+- We provide a Gradio demo for the paired image translation tasks.
+- The following command will launch the sketch to image locally using gradio.
+ ```
+ gradio gradio_sketch2image.py
+ ```
+- The following command will launch the canny edge to image gradio demo locally.
+ ```
+ gradio gradio_canny2image.py
+ ```
+
+
+## Training with your own data
+- See the steps [here](docs/training_pix2pix_turbo.md) for training a pix2pix-turbo model on your paired data.
+- See the steps [here](docs/training_cyclegan_turbo.md) for training a CycleGAN-Turbo model on your unpaired data.
+
+
+## Acknowledgment
+Our work uses the Stable Diffusion-Turbo as the base model with the following [LICENSE](https://huggingface.co/stabilityai/sd-turbo/blob/main/LICENSE).
diff --git a/assets/cat_2x.gif b/assets/cat_2x.gif
new file mode 100644
index 0000000000000000000000000000000000000000..57324ece250ceb2581aa049053e968e9b6baa9d6
--- /dev/null
+++ b/assets/cat_2x.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:65a49403cf594d7b5300547edded6794e1306b61fb5f6837a96320a17954e826
+size 4633791
diff --git a/assets/clear2rainy_results.jpg b/assets/clear2rainy_results.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..42f4d28fe8cb2e06a0290efcef6ec5cb002d17da
--- /dev/null
+++ b/assets/clear2rainy_results.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f8b03789185cdb546080d0a3173e1e7054a4a013c2f3581d4d69fb4f99fe94d2
+size 2869340
diff --git a/assets/day2night_results.jpg b/assets/day2night_results.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..4cb53ff13648fd239ec4e83f41a4646ec79b1824
--- /dev/null
+++ b/assets/day2night_results.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:152448e2de3e09184f34e2d4bf8f41af02669fb6dafd77f4994a5da3b50410bf
+size 2912109
diff --git a/assets/edge_to_image_results.jpg b/assets/edge_to_image_results.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..72cfeff7f8df1df4322ef2502a2c2fedc2b78db0
--- /dev/null
+++ b/assets/edge_to_image_results.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:c0e900c2fe954443b87c8643980c287ff91066a5adb21fbec75595c00a4ab615
+size 2372401
diff --git a/assets/examples/bird.png b/assets/examples/bird.png
new file mode 100644
index 0000000000000000000000000000000000000000..544da68fdbdfda5befa0228d5fbc740d842bf766
--- /dev/null
+++ b/assets/examples/bird.png
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:cad49fc7d3071b2bcd078bc8dde365f8fa62eaa6d43705fd50c212794a3aac35
+size 1065314
diff --git a/assets/examples/bird_canny.png b/assets/examples/bird_canny.png
new file mode 100644
index 0000000000000000000000000000000000000000..8e05dda2e00e17b36b9778f748594d2e22f5606c
Binary files /dev/null and b/assets/examples/bird_canny.png differ
diff --git a/assets/examples/bird_canny_blue.png b/assets/examples/bird_canny_blue.png
new file mode 100644
index 0000000000000000000000000000000000000000..7f9f6aeaa7e4f6d0108e89d041479d04338c0bd6
Binary files /dev/null and b/assets/examples/bird_canny_blue.png differ
diff --git a/assets/examples/circles_inference_input.png b/assets/examples/circles_inference_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..6df950ff41a87d86883b8d840b0ee6bc5240b321
Binary files /dev/null and b/assets/examples/circles_inference_input.png differ
diff --git a/assets/examples/circles_inference_output.png b/assets/examples/circles_inference_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..7426448831e4aae4f0d70ef4bdaeff713d3db85c
Binary files /dev/null and b/assets/examples/circles_inference_output.png differ
diff --git a/assets/examples/clear2rainy_input.png b/assets/examples/clear2rainy_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..4a32e87ba97cc99981f4f3556c95dfc8af4a60ed
Binary files /dev/null and b/assets/examples/clear2rainy_input.png differ
diff --git a/assets/examples/clear2rainy_output.png b/assets/examples/clear2rainy_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..f8a80bb2b13d024742325cc8d3cbf873b9606a71
Binary files /dev/null and b/assets/examples/clear2rainy_output.png differ
diff --git a/assets/examples/day2night_input.png b/assets/examples/day2night_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..5c793124b3ac864c413e8043fbec5a6c024456e6
Binary files /dev/null and b/assets/examples/day2night_input.png differ
diff --git a/assets/examples/day2night_output.png b/assets/examples/day2night_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..cb5650d0b880a1da6fc08e7ea4667e2707d659d7
Binary files /dev/null and b/assets/examples/day2night_output.png differ
diff --git a/assets/examples/my_horse2zebra_input.jpg b/assets/examples/my_horse2zebra_input.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..89c8a06f4ce142c5ad5d4d7b41924fd49ec563c8
Binary files /dev/null and b/assets/examples/my_horse2zebra_input.jpg differ
diff --git a/assets/examples/my_horse2zebra_output.jpg b/assets/examples/my_horse2zebra_output.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d2cf32bb7cef0aaa1addbefc633748493fadff39
Binary files /dev/null and b/assets/examples/my_horse2zebra_output.jpg differ
diff --git a/assets/examples/night2day_input.png b/assets/examples/night2day_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..3881b0b4719bdd3fcc92af0c9d3add29f87e8849
Binary files /dev/null and b/assets/examples/night2day_input.png differ
diff --git a/assets/examples/night2day_output.png b/assets/examples/night2day_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..4501f0136af940c33f2804dcd14c2e6c544c7ef8
Binary files /dev/null and b/assets/examples/night2day_output.png differ
diff --git a/assets/examples/rainy2clear_input.png b/assets/examples/rainy2clear_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..3c0525b253a6f8f928e72596013241432a5eb20f
Binary files /dev/null and b/assets/examples/rainy2clear_input.png differ
diff --git a/assets/examples/rainy2clear_output.png b/assets/examples/rainy2clear_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..44d67bf2708e344367e36feaec4cca859f5e1a28
Binary files /dev/null and b/assets/examples/rainy2clear_output.png differ
diff --git a/assets/examples/sketch_input.png b/assets/examples/sketch_input.png
new file mode 100644
index 0000000000000000000000000000000000000000..bd285beaf0bf04a1794381bd761a6c48ffea76c4
Binary files /dev/null and b/assets/examples/sketch_input.png differ
diff --git a/assets/examples/sketch_output.png b/assets/examples/sketch_output.png
new file mode 100644
index 0000000000000000000000000000000000000000..1f22ab8a608a78d205b4e6165934ec5a90281310
Binary files /dev/null and b/assets/examples/sketch_output.png differ
diff --git a/assets/examples/training_evaluation.png b/assets/examples/training_evaluation.png
new file mode 100644
index 0000000000000000000000000000000000000000..d1e50aba30ab4930367e12a29c24e95b05a69782
Binary files /dev/null and b/assets/examples/training_evaluation.png differ
diff --git a/assets/examples/training_evaluation_unpaired.png b/assets/examples/training_evaluation_unpaired.png
new file mode 100644
index 0000000000000000000000000000000000000000..72464e8f13e9bfee7a5271d498042509c452f75c
Binary files /dev/null and b/assets/examples/training_evaluation_unpaired.png differ
diff --git a/assets/examples/training_step_0.png b/assets/examples/training_step_0.png
new file mode 100644
index 0000000000000000000000000000000000000000..5a11bbc75c258cc0265ccedd608911e84253a81d
Binary files /dev/null and b/assets/examples/training_step_0.png differ
diff --git a/assets/examples/training_step_500.png b/assets/examples/training_step_500.png
new file mode 100644
index 0000000000000000000000000000000000000000..870cf99bc71d32319eb429ab98dc4d7abb1d3499
Binary files /dev/null and b/assets/examples/training_step_500.png differ
diff --git a/assets/examples/training_step_6000.png b/assets/examples/training_step_6000.png
new file mode 100644
index 0000000000000000000000000000000000000000..97275418a2036283f13bd14d4358a2da81bb2d67
Binary files /dev/null and b/assets/examples/training_step_6000.png differ
diff --git a/assets/fish_2x.gif b/assets/fish_2x.gif
new file mode 100644
index 0000000000000000000000000000000000000000..66c362efb73e1f192cd6eab0158ccd81257a5953
--- /dev/null
+++ b/assets/fish_2x.gif
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:9668ef45316f92d7c36db1e6d1854d2d413a2d87b32d73027149aeb02cc94e9d
+size 2475778
diff --git a/assets/gen_variations.jpg b/assets/gen_variations.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..d0a415444e94061bfd10283bfe62725730735acb
--- /dev/null
+++ b/assets/gen_variations.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:f9443d34ae70cc7d6d5123f7517b7f6e601ba6a59fedd63935e8dcd2dbf507e7
+size 3332643
diff --git a/assets/method.jpg b/assets/method.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..386836b25f7ffaf9c4b46af2f647a81ca165a6bf
Binary files /dev/null and b/assets/method.jpg differ
diff --git a/assets/night2day_results.jpg b/assets/night2day_results.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..dfa02bd88b3e8007d294a41ad68164d8a732c00e
--- /dev/null
+++ b/assets/night2day_results.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:2c2e0c3e5673e803482d881ab4df66e4e3103803e52daf48da43fb398742a3e8
+size 2374196
diff --git a/assets/rainy2clear.jpg b/assets/rainy2clear.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..8ba2c49456b9e750d1e24ed23303eef8d91244ca
--- /dev/null
+++ b/assets/rainy2clear.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:ba435223d2c72430a9defeb7da94d43af9ddf67c32f11beb78c463f6a95347f5
+size 2487064
diff --git a/assets/teaser_results.jpg b/assets/teaser_results.jpg
new file mode 100644
index 0000000000000000000000000000000000000000..4765f618b998f61fb240cdb2bbe4581b192f354c
--- /dev/null
+++ b/assets/teaser_results.jpg
@@ -0,0 +1,3 @@
+version https://git-lfs.github.com/spec/v1
+oid sha256:55f14cff3825bf475ed7cf3847182a9689d4e7745204acbcd6ae8023d855e9ea
+size 2056800
diff --git a/docs/training_cyclegan_turbo.md b/docs/training_cyclegan_turbo.md
new file mode 100644
index 0000000000000000000000000000000000000000..15187b372ad465f49fd8ca683e41bbd739b0ee27
--- /dev/null
+++ b/docs/training_cyclegan_turbo.md
@@ -0,0 +1,98 @@
+## Training with Unpaired Data (CycleGAN-turbo)
+Here, we show how to train a CycleGAN-turbo model using unpaired data.
+We will use the [horse2zebra dataset](https://github.com/junyanz/pytorch-CycleGAN-and-pix2pix/blob/master/docs/datasets.md) introduced by [CycleGAN](https://junyanz.github.io/CycleGAN/) as an example dataset.
+
+
+### Step 1. Get the Dataset
+- First download the horse2zebra dataset from [here](https://www.cs.cmu.edu/~img2img-turbo/data/my_horse2zebra.zip) using the command below.
+ ```
+ bash scripts/download_horse2zebra.sh
+ ```
+
+- Our training scripts expect the dataset to be in the following format:
+ ```
+ data
+ ├── dataset_name
+ │ ├── train_A
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ ├── train_B
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ └── fixed_prompt_a.txt
+ | └── fixed_prompt_b.txt
+ |
+ | ├── test_A
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ ├── test_B
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ ```
+- The `fixed_prompt_a.txt` and `fixed_prompt_b.txt` files contain the **fixed caption** used for the source and target domains respectively.
+
+
+### Step 2. Train the Model
+- Initialize the `accelerate` environment with the following command:
+ ```
+ accelerate config
+ ```
+
+- Run the following command to train the model.
+ ```
+ export NCCL_P2P_DISABLE=1
+ accelerate launch --main_process_port 29501 src/train_cyclegan_turbo.py \
+ --pretrained_model_name_or_path="stabilityai/sd-turbo" \
+ --output_dir="output/cyclegan_turbo/my_horse2zebra" \
+ --dataset_folder "data/my_horse2zebra" \
+ --train_img_prep "resize_286_randomcrop_256x256_hflip" --val_img_prep "no_resize" \
+ --learning_rate="1e-5" --max_train_steps=25000 \
+ --train_batch_size=1 --gradient_accumulation_steps=1 \
+ --report_to "wandb" --tracker_project_name "gparmar_unpaired_h2z_cycle_debug_v2" \
+ --enable_xformers_memory_efficient_attention --validation_steps 250 \
+ --lambda_gan 0.5 --lambda_idt 1 --lambda_cycle 1
+ ```
+
+- Additional optional flags:
+ - `--enable_xformers_memory_efficient_attention`: Enable memory-efficient attention in the model.
+
+### Step 3. Monitor the training progress
+- You can monitor the training progress using the [Weights & Biases](https://wandb.ai/site) dashboard.
+
+- The training script will visualizing the training batch, the training losses, and validation set L2, LPIPS, and FID scores (if specified).
+
+
+  +
+
+
+
+ | Model Input |
+ Model Output |
+
+
+  |
+  |
+
+
+
diff --git a/docs/training_pix2pix_turbo.md b/docs/training_pix2pix_turbo.md
new file mode 100644
index 0000000000000000000000000000000000000000..ef22d2e8dda41a139cd0aeac9856c3b96b40c6d9
--- /dev/null
+++ b/docs/training_pix2pix_turbo.md
@@ -0,0 +1,118 @@
+## Training with Paired Data (pix2pix-turbo)
+Here, we show how to train a pix2pix-turbo model using paired data.
+We will use the [Fill50k dataset](https://github.com/lllyasviel/ControlNet/blob/main/docs/train.md) used by [ControlNet](https://github.com/lllyasviel/ControlNet) as an example dataset.
+
+
+### Step 1. Get the Dataset
+- First download a modified Fill50k dataset from [here](https://www.cs.cmu.edu/~img2img-turbo/data/my_fill50k.zip) using the command below.
+ ```
+ bash scripts/download_fill50k.sh
+ ```
+
+- Our training scripts expect the dataset to be in the following format:
+ ```
+ data
+ ├── dataset_name
+ │ ├── train_A
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ ├── train_B
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ └── train_prompts.json
+ |
+ | ├── test_A
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ ├── test_B
+ │ │ ├── 000000.png
+ │ │ ├── 000001.png
+ │ │ └── ...
+ │ └── test_prompts.json
+ ```
+
+
+### Step 2. Train the Model
+- Initialize the `accelerate` environment with the following command:
+ ```
+ accelerate config
+ ```
+
+- Run the following command to train the model.
+ ```
+ accelerate launch src/train_pix2pix_turbo.py \
+ --pretrained_model_name_or_path="stabilityai/sd-turbo" \
+ --output_dir="output/pix2pix_turbo/fill50k" \
+ --dataset_folder="data/my_fill50k" \
+ --resolution=512 \
+ --train_batch_size=2 \
+ --enable_xformers_memory_efficient_attention --viz_freq 25 \
+ --track_val_fid \
+ --report_to "wandb" --tracker_project_name "pix2pix_turbo_fill50k"
+ ```
+
+- Additional optional flags:
+ - `--track_val_fid`: Track FID score on the validation set using the [Clean-FID](https://github.com/GaParmar/clean-fid) implementation.
+ - `--enable_xformers_memory_efficient_attention`: Enable memory-efficient attention in the model.
+ - `--viz_freq`: Frequency of visualizing the results during training.
+
+### Step 3. Monitor the training progress
+- You can monitor the training progress using the [Weights & Biases](https://wandb.ai/site) dashboard.
+
+- The training script will visualizing the training batch, the training losses, and validation set L2, LPIPS, and FID scores (if specified).
+
+
+  +
+
+
+
+  +
+
+
+
+  +
+
+
+
+  +
+
+
+
+ | Model Input |
+ Model Output |
+
+
+  |
+  |
+
+
diff --git a/environment.yaml b/environment.yaml
new file mode 100644
index 0000000000000000000000000000000000000000..197675a5b518b26dca71b60b5ccaa5d89e3256f0
--- /dev/null
+++ b/environment.yaml
@@ -0,0 +1,34 @@
+name: img2img-turbo
+channels:
+ - pytorch
+ - defaults
+dependencies:
+ - python=3.10
+ - pip:
+ - clip @ git+https://github.com/openai/CLIP.git
+ - einops>=0.6.1
+ - numpy>=1.24.4
+ - open-clip-torch>=2.20.0
+ - opencv-python==4.6.0.66
+ - pillow>=9.5.0
+ - scipy==1.11.1
+ - timm>=0.9.2
+ - tokenizers
+ - torch>=2.0.1
+
+ - torchaudio>=2.0.2
+ - torchdata==0.6.1
+ - torchmetrics>=1.0.1
+ - torchvision>=0.15.2
+
+ - tqdm>=4.65.0
+ - transformers==4.35.2
+ - urllib3<1.27,>=1.25.4
+ - xformers>=0.0.20
+ - streamlit-keyup==0.2.0
+ - lpips
+ - clean-fid
+ - peft
+ - dominate
+ - diffusers==0.25.1
+ - gradio==3.43.1
diff --git a/gradio_canny2image.py b/gradio_canny2image.py
new file mode 100644
index 0000000000000000000000000000000000000000..de1bc8c55c9f85ef70a3527a0edbe7d0af02f2b4
--- /dev/null
+++ b/gradio_canny2image.py
@@ -0,0 +1,78 @@
+import numpy as np
+from PIL import Image
+import torch
+from torchvision import transforms
+import gradio as gr
+from src.image_prep import canny_from_pil
+from src.pix2pix_turbo import Pix2Pix_Turbo
+
+model = Pix2Pix_Turbo("edge_to_image")
+
+
+def process(input_image, prompt, low_threshold, high_threshold):
+ # resize to be a multiple of 8
+ new_width = input_image.width - input_image.width % 8
+ new_height = input_image.height - input_image.height % 8
+ input_image = input_image.resize((new_width, new_height))
+ canny = canny_from_pil(input_image, low_threshold, high_threshold)
+ with torch.no_grad():
+ c_t = transforms.ToTensor()(canny).unsqueeze(0).cuda()
+ output_image = model(c_t, prompt)
+ output_pil = transforms.ToPILImage()(output_image[0].cpu() * 0.5 + 0.5)
+ # flippy canny values, map all 0s to 1s and 1s to 0s
+ canny_viz = 1 - (np.array(canny) / 255)
+ canny_viz = Image.fromarray((canny_viz * 255).astype(np.uint8))
+ return canny_viz, output_pil
+
+
+if __name__ == "__main__":
+ # load the model
+ with gr.Blocks() as demo:
+ gr.Markdown("# Pix2pix-Turbo: **Canny Edge -> Image**")
+ with gr.Row():
+ with gr.Column():
+ input_image = gr.Image(sources="upload", type="pil")
+ prompt = gr.Textbox(label="Prompt")
+ low_threshold = gr.Slider(
+ label="Canny low threshold",
+ minimum=1,
+ maximum=255,
+ value=100,
+ step=10,
+ )
+ high_threshold = gr.Slider(
+ label="Canny high threshold",
+ minimum=1,
+ maximum=255,
+ value=200,
+ step=10,
+ )
+ run_button = gr.Button(value="Run")
+ with gr.Column():
+ result_canny = gr.Image(type="pil")
+ with gr.Column():
+ result_output = gr.Image(type="pil")
+
+ prompt.submit(
+ fn=process,
+ inputs=[input_image, prompt, low_threshold, high_threshold],
+ outputs=[result_canny, result_output],
+ )
+ low_threshold.change(
+ fn=process,
+ inputs=[input_image, prompt, low_threshold, high_threshold],
+ outputs=[result_canny, result_output],
+ )
+ high_threshold.change(
+ fn=process,
+ inputs=[input_image, prompt, low_threshold, high_threshold],
+ outputs=[result_canny, result_output],
+ )
+ run_button.click(
+ fn=process,
+ inputs=[input_image, prompt, low_threshold, high_threshold],
+ outputs=[result_canny, result_output],
+ )
+
+ demo.queue()
+ demo.launch(debug=True, share=False)
diff --git a/gradio_sketch2image.py b/gradio_sketch2image.py
new file mode 100644
index 0000000000000000000000000000000000000000..8fb326b49336a9fe946b6373c9f46cd564ae48e6
--- /dev/null
+++ b/gradio_sketch2image.py
@@ -0,0 +1,382 @@
+import random
+import numpy as np
+from PIL import Image
+import base64
+from io import BytesIO
+
+import torch
+import torchvision.transforms.functional as F
+import gradio as gr
+
+from src.pix2pix_turbo import Pix2Pix_Turbo
+
+model = Pix2Pix_Turbo("sketch_to_image_stochastic")
+
+style_list = [
+ {
+ "name": "Cinematic",
+ "prompt": "cinematic still {prompt} . emotional, harmonious, vignette, highly detailed, high budget, bokeh, cinemascope, moody, epic, gorgeous, film grain, grainy",
+ },
+ {
+ "name": "3D Model",
+ "prompt": "professional 3d model {prompt} . octane render, highly detailed, volumetric, dramatic lighting",
+ },
+ {
+ "name": "Anime",
+ "prompt": "anime artwork {prompt} . anime style, key visual, vibrant, studio anime, highly detailed",
+ },
+ {
+ "name": "Digital Art",
+ "prompt": "concept art {prompt} . digital artwork, illustrative, painterly, matte painting, highly detailed",
+ },
+ {
+ "name": "Photographic",
+ "prompt": "cinematic photo {prompt} . 35mm photograph, film, bokeh, professional, 4k, highly detailed",
+ },
+ {
+ "name": "Pixel art",
+ "prompt": "pixel-art {prompt} . low-res, blocky, pixel art style, 8-bit graphics",
+ },
+ {
+ "name": "Fantasy art",
+ "prompt": "ethereal fantasy concept art of {prompt} . magnificent, celestial, ethereal, painterly, epic, majestic, magical, fantasy art, cover art, dreamy",
+ },
+ {
+ "name": "Neonpunk",
+ "prompt": "neonpunk style {prompt} . cyberpunk, vaporwave, neon, vibes, vibrant, stunningly beautiful, crisp, detailed, sleek, ultramodern, magenta highlights, dark purple shadows, high contrast, cinematic, ultra detailed, intricate, professional",
+ },
+ {
+ "name": "Manga",
+ "prompt": "manga style {prompt} . vibrant, high-energy, detailed, iconic, Japanese comic style",
+ },
+]
+
+styles = {k["name"]: k["prompt"] for k in style_list}
+STYLE_NAMES = list(styles.keys())
+DEFAULT_STYLE_NAME = "Fantasy art"
+MAX_SEED = np.iinfo(np.int32).max
+
+
+def pil_image_to_data_uri(img, format="PNG"):
+ buffered = BytesIO()
+ img.save(buffered, format=format)
+ img_str = base64.b64encode(buffered.getvalue()).decode()
+ return f"data:image/{format.lower()};base64,{img_str}"
+
+
+def run(image, prompt, prompt_template, style_name, seed, val_r):
+ print(f"prompt: {prompt}")
+ print("sketch updated")
+ if image is None:
+ ones = Image.new("L", (512, 512), 255)
+ temp_uri = pil_image_to_data_uri(ones)
+ return ones, gr.update(link=temp_uri), gr.update(link=temp_uri)
+ prompt = prompt_template.replace("{prompt}", prompt)
+ image = image.convert("RGB")
+ image_t = F.to_tensor(image) > 0.5
+ print(f"r_val={val_r}, seed={seed}")
+ with torch.no_grad():
+ c_t = image_t.unsqueeze(0).cuda().float()
+ torch.manual_seed(seed)
+ B, C, H, W = c_t.shape
+ noise = torch.randn((1, 4, H // 8, W // 8), device=c_t.device)
+ output_image = model(c_t, prompt, deterministic=False, r=val_r, noise_map=noise)
+ output_pil = F.to_pil_image(output_image[0].cpu() * 0.5 + 0.5)
+ input_sketch_uri = pil_image_to_data_uri(Image.fromarray(255 - np.array(image)))
+ output_image_uri = pil_image_to_data_uri(output_pil)
+ return (
+ output_pil,
+ gr.update(link=input_sketch_uri),
+ gr.update(link=output_image_uri),
+ )
+
+
+def update_canvas(use_line, use_eraser):
+ if use_eraser:
+ _color = "#ffffff"
+ brush_size = 20
+ if use_line:
+ _color = "#000000"
+ brush_size = 4
+ return gr.update(brush_radius=brush_size, brush_color=_color, interactive=True)
+
+
+def upload_sketch(file):
+ _img = Image.open(file.name)
+ _img = _img.convert("L")
+ return gr.update(value=_img, source="upload", interactive=True)
+
+
+scripts = """
+async () => {
+ globalThis.theSketchDownloadFunction = () => {
+ console.log("test")
+ var link = document.createElement("a");
+ dataUri = document.getElementById('download_sketch').href
+ link.setAttribute("href", dataUri)
+ link.setAttribute("download", "sketch.png")
+ document.body.appendChild(link); // Required for Firefox
+ link.click();
+ document.body.removeChild(link); // Clean up
+
+ // also call the output download function
+ theOutputDownloadFunction();
+ return false
+ }
+
+ globalThis.theOutputDownloadFunction = () => {
+ console.log("test output download function")
+ var link = document.createElement("a");
+ dataUri = document.getElementById('download_output').href
+ link.setAttribute("href", dataUri);
+ link.setAttribute("download", "output.png");
+ document.body.appendChild(link); // Required for Firefox
+ link.click();
+ document.body.removeChild(link); // Clean up
+ return false
+ }
+
+ globalThis.UNDO_SKETCH_FUNCTION = () => {
+ console.log("undo sketch function")
+ var button_undo = document.querySelector('#input_image > div.image-container.svelte-p3y7hu > div.svelte-s6ybro > button:nth-child(1)');
+ // Create a new 'click' event
+ var event = new MouseEvent('click', {
+ 'view': window,
+ 'bubbles': true,
+ 'cancelable': true
+ });
+ button_undo.dispatchEvent(event);
+ }
+
+ globalThis.DELETE_SKETCH_FUNCTION = () => {
+ console.log("delete sketch function")
+ var button_del = document.querySelector('#input_image > div.image-container.svelte-p3y7hu > div.svelte-s6ybro > button:nth-child(2)');
+ // Create a new 'click' event
+ var event = new MouseEvent('click', {
+ 'view': window,
+ 'bubbles': true,
+ 'cancelable': true
+ });
+ button_del.dispatchEvent(event);
+ }
+
+ globalThis.togglePencil = () => {
+ el_pencil = document.getElementById('my-toggle-pencil');
+ el_pencil.classList.toggle('clicked');
+ // simulate a click on the gradio button
+ btn_gradio = document.querySelector("#cb-line > label > input");
+ var event = new MouseEvent('click', {
+ 'view': window,
+ 'bubbles': true,
+ 'cancelable': true
+ });
+ btn_gradio.dispatchEvent(event);
+ if (el_pencil.classList.contains('clicked')) {
+ document.getElementById('my-toggle-eraser').classList.remove('clicked');
+ document.getElementById('my-div-pencil').style.backgroundColor = "gray";
+ document.getElementById('my-div-eraser').style.backgroundColor = "white";
+ }
+ else {
+ document.getElementById('my-toggle-eraser').classList.add('clicked');
+ document.getElementById('my-div-pencil').style.backgroundColor = "white";
+ document.getElementById('my-div-eraser').style.backgroundColor = "gray";
+ }
+ }
+
+ globalThis.toggleEraser = () => {
+ element = document.getElementById('my-toggle-eraser');
+ element.classList.toggle('clicked');
+ // simulate a click on the gradio button
+ btn_gradio = document.querySelector("#cb-eraser > label > input");
+ var event = new MouseEvent('click', {
+ 'view': window,
+ 'bubbles': true,
+ 'cancelable': true
+ });
+ btn_gradio.dispatchEvent(event);
+ if (element.classList.contains('clicked')) {
+ document.getElementById('my-toggle-pencil').classList.remove('clicked');
+ document.getElementById('my-div-pencil').style.backgroundColor = "white";
+ document.getElementById('my-div-eraser').style.backgroundColor = "gray";
+ }
+ else {
+ document.getElementById('my-toggle-pencil').classList.add('clicked');
+ document.getElementById('my-div-pencil').style.backgroundColor = "gray";
+ document.getElementById('my-div-eraser').style.backgroundColor = "white";
+ }
+ }
+}
+"""
+
+with gr.Blocks(css="style.css") as demo:
+
+ gr.HTML(
+ """
+
+
+
+
+ """
+ )
+
+ # these are hidden buttons that are used to trigger the canvas changes
+ line = gr.Checkbox(label="line", value=False, elem_id="cb-line")
+ eraser = gr.Checkbox(label="eraser", value=False, elem_id="cb-eraser")
+ with gr.Row(elem_id="main_row"):
+ with gr.Column(elem_id="column_input"):
+ gr.Markdown("## INPUT", elem_id="input_header")
+ image = gr.Image(
+ source="canvas",
+ tool="color-sketch",
+ type="pil",
+ image_mode="L",
+ invert_colors=True,
+ shape=(512, 512),
+ brush_radius=4,
+ height=440,
+ width=440,
+ brush_color="#000000",
+ interactive=True,
+ show_download_button=True,
+ elem_id="input_image",
+ show_label=False,
+ )
+ download_sketch = gr.Button(
+ "Download sketch", scale=1, elem_id="download_sketch"
+ )
+
+ gr.HTML(
+ """
+
+ """
+ )
+ # gr.Markdown("## Prompt", elem_id="tools_header")
+ prompt = gr.Textbox(label="Prompt", value="", show_label=True)
+ with gr.Row():
+ style = gr.Dropdown(
+ label="Style",
+ choices=STYLE_NAMES,
+ value=DEFAULT_STYLE_NAME,
+ scale=1,
+ )
+ prompt_temp = gr.Textbox(
+ label="Prompt Style Template",
+ value=styles[DEFAULT_STYLE_NAME],
+ scale=2,
+ max_lines=1,
+ )
+
+ with gr.Row():
+ val_r = gr.Slider(
+ label="Sketch guidance: ",
+ show_label=True,
+ minimum=0,
+ maximum=1,
+ value=0.4,
+ step=0.01,
+ scale=3,
+ )
+ seed = gr.Textbox(label="Seed", value=42, scale=1, min_width=50)
+ randomize_seed = gr.Button("Random", scale=1, min_width=50)
+
+ with gr.Column(elem_id="column_process", min_width=50, scale=0.4):
+ gr.Markdown("## pix2pix-turbo", elem_id="description")
+ run_button = gr.Button("Run", min_width=50)
+
+ with gr.Column(elem_id="column_output"):
+ gr.Markdown("## OUTPUT", elem_id="output_header")
+ result = gr.Image(
+ label="Result",
+ height=440,
+ width=440,
+ elem_id="output_image",
+ show_label=False,
+ show_download_button=True,
+ )
+ download_output = gr.Button("Download output", elem_id="download_output")
+ gr.Markdown("### Instructions")
+ gr.Markdown("**1**. Enter a text prompt (e.g. cat)")
+ gr.Markdown("**2**. Start sketching")
+ gr.Markdown("**3**. Change the image style using a style template")
+ gr.Markdown("**4**. Adjust the effect of sketch guidance using the slider")
+ gr.Markdown("**5**. Try different seeds to generate different results")
+
+ eraser.change(
+ fn=lambda x: gr.update(value=not x),
+ inputs=[eraser],
+ outputs=[line],
+ queue=False,
+ api_name=False,
+ ).then(update_canvas, [line, eraser], [image])
+ line.change(
+ fn=lambda x: gr.update(value=not x),
+ inputs=[line],
+ outputs=[eraser],
+ queue=False,
+ api_name=False,
+ ).then(update_canvas, [line, eraser], [image])
+
+ demo.load(None, None, None, _js=scripts)
+ randomize_seed.click(
+ lambda x: random.randint(0, MAX_SEED),
+ inputs=[],
+ outputs=seed,
+ queue=False,
+ api_name=False,
+ )
+ inputs = [image, prompt, prompt_temp, style, seed, val_r]
+ outputs = [result, download_sketch, download_output]
+ prompt.submit(fn=run, inputs=inputs, outputs=outputs, api_name=False)
+ style.change(
+ lambda x: styles[x],
+ inputs=[style],
+ outputs=[prompt_temp],
+ queue=False,
+ api_name=False,
+ ).then(
+ fn=run,
+ inputs=inputs,
+ outputs=outputs,
+ api_name=False,
+ )
+ val_r.change(run, inputs=inputs, outputs=outputs, queue=False, api_name=False)
+ run_button.click(fn=run, inputs=inputs, outputs=outputs, api_name=False)
+ image.change(run, inputs=inputs, outputs=outputs, queue=False, api_name=False)
+
+if __name__ == "__main__":
+ demo.queue().launch(debug=True, share=True)
diff --git a/requirements.txt b/requirements.txt
new file mode 100644
index 0000000000000000000000000000000000000000..27ea4389a4b5211f4f65c550ecc6dff285a119f5
--- /dev/null
+++ b/requirements.txt
@@ -0,0 +1,29 @@
+clip @ git+https://github.com/openai/CLIP.git
+einops>=0.6.1
+numpy>=1.24.4
+open-clip-torch>=2.20.0
+opencv-python==4.6.0.66
+pillow>=9.5.0
+scipy==1.11.1
+timm>=0.9.2
+tokenizers
+torch>=2.0.1
+
+torchaudio>=2.0.2
+torchdata==0.6.1
+torchmetrics>=1.0.1
+torchvision>=0.15.2
+
+tqdm>=4.65.0
+transformers==4.35.2
+urllib3<1.27,>=1.25.4
+xformers>=0.0.20
+streamlit-keyup==0.2.0
+lpips
+clean-fid
+peft
+dominate
+diffusers==0.25.1
+gradio==3.43.1
+
+vision_aided_loss
diff --git a/scripts/download_fill50k.sh b/scripts/download_fill50k.sh
new file mode 100644
index 0000000000000000000000000000000000000000..5ceeccdad9393c22030d9445e1e9684cefbee7d8
--- /dev/null
+++ b/scripts/download_fill50k.sh
@@ -0,0 +1,5 @@
+mkdir -p data
+wget https://www.cs.cmu.edu/~img2img-turbo/data/my_fill50k.zip -O data/my_fill50k.zip
+cd data
+unzip my_fill50k.zip
+rm my_fill50k.zip
\ No newline at end of file
diff --git a/scripts/download_horse2zebra.sh b/scripts/download_horse2zebra.sh
new file mode 100644
index 0000000000000000000000000000000000000000..31b40fe7a7176592f1f124560164bfd19c7a5079
--- /dev/null
+++ b/scripts/download_horse2zebra.sh
@@ -0,0 +1,5 @@
+mkdir -p data
+wget https://www.cs.cmu.edu/~img2img-turbo/data/my_horse2zebra.zip -O data/my_horse2zebra.zip
+cd data
+unzip my_horse2zebra.zip
+rm my_horse2zebra.zip
\ No newline at end of file
diff --git a/src/cyclegan_turbo.py b/src/cyclegan_turbo.py
new file mode 100644
index 0000000000000000000000000000000000000000..9a074c883e440816665f1d45d54cfe3f4f59d1ae
--- /dev/null
+++ b/src/cyclegan_turbo.py
@@ -0,0 +1,254 @@
+import os
+import sys
+import copy
+import torch
+import torch.nn as nn
+from transformers import AutoTokenizer, CLIPTextModel
+from diffusers import AutoencoderKL, UNet2DConditionModel
+from peft import LoraConfig
+from peft.utils import get_peft_model_state_dict
+p = "src/"
+sys.path.append(p)
+from model import make_1step_sched, my_vae_encoder_fwd, my_vae_decoder_fwd, download_url
+
+
+class VAE_encode(nn.Module):
+ def __init__(self, vae, vae_b2a=None):
+ super(VAE_encode, self).__init__()
+ self.vae = vae
+ self.vae_b2a = vae_b2a
+
+ def forward(self, x, direction):
+ assert direction in ["a2b", "b2a"]
+ if direction == "a2b":
+ _vae = self.vae
+ else:
+ _vae = self.vae_b2a
+ return _vae.encode(x).latent_dist.sample() * _vae.config.scaling_factor
+
+
+class VAE_decode(nn.Module):
+ def __init__(self, vae, vae_b2a=None):
+ super(VAE_decode, self).__init__()
+ self.vae = vae
+ self.vae_b2a = vae_b2a
+
+ def forward(self, x, direction):
+ assert direction in ["a2b", "b2a"]
+ if direction == "a2b":
+ _vae = self.vae
+ else:
+ _vae = self.vae_b2a
+ assert _vae.encoder.current_down_blocks is not None
+ _vae.decoder.incoming_skip_acts = _vae.encoder.current_down_blocks
+ x_decoded = (_vae.decode(x / _vae.config.scaling_factor).sample).clamp(-1, 1)
+ return x_decoded
+
+
+def initialize_unet(rank, return_lora_module_names=False):
+ unet = UNet2DConditionModel.from_pretrained("stabilityai/sd-turbo", subfolder="unet")
+ unet.requires_grad_(False)
+ unet.train()
+ l_target_modules_encoder, l_target_modules_decoder, l_modules_others = [], [], []
+ l_grep = ["to_k", "to_q", "to_v", "to_out.0", "conv", "conv1", "conv2", "conv_in", "conv_shortcut", "conv_out", "proj_out", "proj_in", "ff.net.2", "ff.net.0.proj"]
+ for n, p in unet.named_parameters():
+ if "bias" in n or "norm" in n: continue
+ for pattern in l_grep:
+ if pattern in n and ("down_blocks" in n or "conv_in" in n):
+ l_target_modules_encoder.append(n.replace(".weight",""))
+ break
+ elif pattern in n and "up_blocks" in n:
+ l_target_modules_decoder.append(n.replace(".weight",""))
+ break
+ elif pattern in n:
+ l_modules_others.append(n.replace(".weight",""))
+ break
+ lora_conf_encoder = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_target_modules_encoder, lora_alpha=rank)
+ lora_conf_decoder = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_target_modules_decoder, lora_alpha=rank)
+ lora_conf_others = LoraConfig(r=rank, init_lora_weights="gaussian",target_modules=l_modules_others, lora_alpha=rank)
+ unet.add_adapter(lora_conf_encoder, adapter_name="default_encoder")
+ unet.add_adapter(lora_conf_decoder, adapter_name="default_decoder")
+ unet.add_adapter(lora_conf_others, adapter_name="default_others")
+ unet.set_adapters(["default_encoder", "default_decoder", "default_others"])
+ if return_lora_module_names:
+ return unet, l_target_modules_encoder, l_target_modules_decoder, l_modules_others
+ else:
+ return unet
+
+
+def initialize_vae(rank=4, return_lora_module_names=False):
+ vae = AutoencoderKL.from_pretrained("stabilityai/sd-turbo", subfolder="vae")
+ vae.requires_grad_(False)
+ vae.encoder.forward = my_vae_encoder_fwd.__get__(vae.encoder, vae.encoder.__class__)
+ vae.decoder.forward = my_vae_decoder_fwd.__get__(vae.decoder, vae.decoder.__class__)
+ vae.requires_grad_(True)
+ vae.train()
+ # add the skip connection convs
+ vae.decoder.skip_conv_1 = torch.nn.Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True)
+ vae.decoder.skip_conv_2 = torch.nn.Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True)
+ vae.decoder.skip_conv_3 = torch.nn.Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True)
+ vae.decoder.skip_conv_4 = torch.nn.Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda().requires_grad_(True)
+ torch.nn.init.constant_(vae.decoder.skip_conv_1.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_2.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_3.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_4.weight, 1e-5)
+ vae.decoder.ignore_skip = False
+ vae.decoder.gamma = 1
+ l_vae_target_modules = ["conv1","conv2","conv_in", "conv_shortcut",
+ "conv", "conv_out", "skip_conv_1", "skip_conv_2", "skip_conv_3",
+ "skip_conv_4", "to_k", "to_q", "to_v", "to_out.0",
+ ]
+ vae_lora_config = LoraConfig(r=rank, init_lora_weights="gaussian", target_modules=l_vae_target_modules)
+ vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ if return_lora_module_names:
+ return vae, l_vae_target_modules
+ else:
+ return vae
+
+
+class CycleGAN_Turbo(torch.nn.Module):
+ def __init__(self, pretrained_name=None, pretrained_path=None, ckpt_folder="checkpoints", lora_rank_unet=8, lora_rank_vae=4):
+ super().__init__()
+ self.tokenizer = AutoTokenizer.from_pretrained("stabilityai/sd-turbo", subfolder="tokenizer")
+ self.text_encoder = CLIPTextModel.from_pretrained("stabilityai/sd-turbo", subfolder="text_encoder").cuda()
+ self.sched = make_1step_sched()
+ vae = AutoencoderKL.from_pretrained("stabilityai/sd-turbo", subfolder="vae")
+ unet = UNet2DConditionModel.from_pretrained("stabilityai/sd-turbo", subfolder="unet")
+ vae.encoder.forward = my_vae_encoder_fwd.__get__(vae.encoder, vae.encoder.__class__)
+ vae.decoder.forward = my_vae_decoder_fwd.__get__(vae.decoder, vae.decoder.__class__)
+ # add the skip connection convs
+ vae.decoder.skip_conv_1 = torch.nn.Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_2 = torch.nn.Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_3 = torch.nn.Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_4 = torch.nn.Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.ignore_skip = False
+ self.unet, self.vae = unet, vae
+ if pretrained_name == "day_to_night":
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/day2night.pkl"
+ self.load_ckpt_from_url(url, ckpt_folder)
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.caption = "driving in the night"
+ self.direction = "a2b"
+ elif pretrained_name == "night_to_day":
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/night2day.pkl"
+ self.load_ckpt_from_url(url, ckpt_folder)
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.caption = "driving in the day"
+ self.direction = "b2a"
+ elif pretrained_name == "clear_to_rainy":
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/clear2rainy.pkl"
+ self.load_ckpt_from_url(url, ckpt_folder)
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.caption = "driving in heavy rain"
+ self.direction = "a2b"
+ elif pretrained_name == "rainy_to_clear":
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/rainy2clear.pkl"
+ self.load_ckpt_from_url(url, ckpt_folder)
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.caption = "driving in the day"
+ self.direction = "b2a"
+
+ elif pretrained_path is not None:
+ sd = torch.load(pretrained_path)
+ self.load_ckpt_from_state_dict(sd)
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.caption = None
+ self.direction = None
+
+ self.vae_enc.cuda()
+ self.vae_dec.cuda()
+ self.unet.cuda()
+
+ def load_ckpt_from_state_dict(self, sd):
+ lora_conf_encoder = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["l_target_modules_encoder"], lora_alpha=sd["rank_unet"])
+ lora_conf_decoder = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["l_target_modules_decoder"], lora_alpha=sd["rank_unet"])
+ lora_conf_others = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["l_modules_others"], lora_alpha=sd["rank_unet"])
+ self.unet.add_adapter(lora_conf_encoder, adapter_name="default_encoder")
+ self.unet.add_adapter(lora_conf_decoder, adapter_name="default_decoder")
+ self.unet.add_adapter(lora_conf_others, adapter_name="default_others")
+ for n, p in self.unet.named_parameters():
+ name_sd = n.replace(".default_encoder.weight", ".weight")
+ if "lora" in n and "default_encoder" in n:
+ p.data.copy_(sd["sd_encoder"][name_sd])
+ for n, p in self.unet.named_parameters():
+ name_sd = n.replace(".default_decoder.weight", ".weight")
+ if "lora" in n and "default_decoder" in n:
+ p.data.copy_(sd["sd_decoder"][name_sd])
+ for n, p in self.unet.named_parameters():
+ name_sd = n.replace(".default_others.weight", ".weight")
+ if "lora" in n and "default_others" in n:
+ p.data.copy_(sd["sd_other"][name_sd])
+ self.unet.set_adapter(["default_encoder", "default_decoder", "default_others"])
+
+ vae_lora_config = LoraConfig(r=sd["rank_vae"], init_lora_weights="gaussian", target_modules=sd["vae_lora_target_modules"])
+ self.vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ self.vae.decoder.gamma = 1
+ self.vae_b2a = copy.deepcopy(self.vae)
+ self.vae_enc = VAE_encode(self.vae, vae_b2a=self.vae_b2a)
+ self.vae_enc.load_state_dict(sd["sd_vae_enc"])
+ self.vae_dec = VAE_decode(self.vae, vae_b2a=self.vae_b2a)
+ self.vae_dec.load_state_dict(sd["sd_vae_dec"])
+
+ def load_ckpt_from_url(self, url, ckpt_folder):
+ os.makedirs(ckpt_folder, exist_ok=True)
+ outf = os.path.join(ckpt_folder, os.path.basename(url))
+ download_url(url, outf)
+ sd = torch.load(outf)
+ self.load_ckpt_from_state_dict(sd)
+
+ @staticmethod
+ def forward_with_networks(x, direction, vae_enc, unet, vae_dec, sched, timesteps, text_emb):
+ B = x.shape[0]
+ assert direction in ["a2b", "b2a"]
+ x_enc = vae_enc(x, direction=direction).to(x.dtype)
+ model_pred = unet(x_enc, timesteps, encoder_hidden_states=text_emb,).sample
+ x_out = torch.stack([sched.step(model_pred[i], timesteps[i], x_enc[i], return_dict=True).prev_sample for i in range(B)])
+ x_out_decoded = vae_dec(x_out, direction=direction)
+ return x_out_decoded
+
+ @staticmethod
+ def get_traininable_params(unet, vae_a2b, vae_b2a):
+ # add all unet parameters
+ params_gen = list(unet.conv_in.parameters())
+ unet.conv_in.requires_grad_(True)
+ unet.set_adapters(["default_encoder", "default_decoder", "default_others"])
+ for n,p in unet.named_parameters():
+ if "lora" in n and "default" in n:
+ assert p.requires_grad
+ params_gen.append(p)
+
+ # add all vae_a2b parameters
+ for n,p in vae_a2b.named_parameters():
+ if "lora" in n and "vae_skip" in n:
+ assert p.requires_grad
+ params_gen.append(p)
+ params_gen = params_gen + list(vae_a2b.decoder.skip_conv_1.parameters())
+ params_gen = params_gen + list(vae_a2b.decoder.skip_conv_2.parameters())
+ params_gen = params_gen + list(vae_a2b.decoder.skip_conv_3.parameters())
+ params_gen = params_gen + list(vae_a2b.decoder.skip_conv_4.parameters())
+
+ # add all vae_b2a parameters
+ for n,p in vae_b2a.named_parameters():
+ if "lora" in n and "vae_skip" in n:
+ assert p.requires_grad
+ params_gen.append(p)
+ params_gen = params_gen + list(vae_b2a.decoder.skip_conv_1.parameters())
+ params_gen = params_gen + list(vae_b2a.decoder.skip_conv_2.parameters())
+ params_gen = params_gen + list(vae_b2a.decoder.skip_conv_3.parameters())
+ params_gen = params_gen + list(vae_b2a.decoder.skip_conv_4.parameters())
+ return params_gen
+
+ def forward(self, x_t, direction=None, caption=None, caption_emb=None):
+ if direction is None:
+ assert self.direction is not None
+ direction = self.direction
+ if caption is None and caption_emb is None:
+ assert self.caption is not None
+ caption = self.caption
+ if caption_emb is not None:
+ caption_enc = caption_emb
+ else:
+ caption_tokens = self.tokenizer(caption, max_length=self.tokenizer.model_max_length,
+ padding="max_length", truncation=True, return_tensors="pt").input_ids.to(x_t.device)
+ caption_enc = self.text_encoder(caption_tokens)[0].detach().clone()
+ return self.forward_with_networks(x_t, direction, self.vae_enc, self.unet, self.vae_dec, self.sched, self.timesteps, caption_enc)
diff --git a/src/image_prep.py b/src/image_prep.py
new file mode 100644
index 0000000000000000000000000000000000000000..2065734fca443c96912c820226f7ce216b3e02fd
--- /dev/null
+++ b/src/image_prep.py
@@ -0,0 +1,12 @@
+import numpy as np
+from PIL import Image
+import cv2
+
+
+def canny_from_pil(image, low_threshold=100, high_threshold=200):
+ image = np.array(image)
+ image = cv2.Canny(image, low_threshold, high_threshold)
+ image = image[:, :, None]
+ image = np.concatenate([image, image, image], axis=2)
+ control_image = Image.fromarray(image)
+ return control_image
diff --git a/src/inference_paired.py b/src/inference_paired.py
new file mode 100644
index 0000000000000000000000000000000000000000..a51990b48c3a73075c334f0cf48b2594f7bc4205
--- /dev/null
+++ b/src/inference_paired.py
@@ -0,0 +1,75 @@
+import os
+import argparse
+import numpy as np
+from PIL import Image
+import torch
+from torchvision import transforms
+import torchvision.transforms.functional as F
+from pix2pix_turbo import Pix2Pix_Turbo
+from image_prep import canny_from_pil
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--input_image', type=str, required=True, help='path to the input image')
+ parser.add_argument('--prompt', type=str, required=True, help='the prompt to be used')
+ parser.add_argument('--model_name', type=str, default='', help='name of the pretrained model to be used')
+ parser.add_argument('--model_path', type=str, default='', help='path to a model state dict to be used')
+ parser.add_argument('--output_dir', type=str, default='output', help='the directory to save the output')
+ parser.add_argument('--low_threshold', type=int, default=100, help='Canny low threshold')
+ parser.add_argument('--high_threshold', type=int, default=200, help='Canny high threshold')
+ parser.add_argument('--gamma', type=float, default=0.4, help='The sketch interpolation guidance amount')
+ parser.add_argument('--seed', type=int, default=42, help='Random seed to be used')
+ parser.add_argument('--use_fp16', action='store_true', help='Use Float16 precision for faster inference')
+ args = parser.parse_args()
+
+ # only one of model_name and model_path should be provided
+ if args.model_name == '' != args.model_path == '':
+ raise ValueError('Either model_name or model_path should be provided')
+
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # initialize the model
+ model = Pix2Pix_Turbo(pretrained_name=args.model_name, pretrained_path=args.model_path)
+ model.set_eval()
+ if args.use_fp16:
+ model.half()
+
+ # make sure that the input image is a multiple of 8
+ input_image = Image.open(args.input_image).convert('RGB')
+ new_width = input_image.width - input_image.width % 8
+ new_height = input_image.height - input_image.height % 8
+ input_image = input_image.resize((new_width, new_height), Image.LANCZOS)
+ bname = os.path.basename(args.input_image)
+
+ # translate the image
+ with torch.no_grad():
+ if args.model_name == 'edge_to_image':
+ canny = canny_from_pil(input_image, args.low_threshold, args.high_threshold)
+ canny_viz_inv = Image.fromarray(255 - np.array(canny))
+ canny_viz_inv.save(os.path.join(args.output_dir, bname.replace('.png', '_canny.png')))
+ c_t = F.to_tensor(canny).unsqueeze(0).cuda()
+ if args.use_fp16:
+ c_t = c_t.half()
+ output_image = model(c_t, args.prompt)
+
+ elif args.model_name == 'sketch_to_image_stochastic':
+ image_t = F.to_tensor(input_image) < 0.5
+ c_t = image_t.unsqueeze(0).cuda().float()
+ torch.manual_seed(args.seed)
+ B, C, H, W = c_t.shape
+ noise = torch.randn((1, 4, H // 8, W // 8), device=c_t.device)
+ if args.use_fp16:
+ c_t = c_t.half()
+ noise = noise.half()
+ output_image = model(c_t, args.prompt, deterministic=False, r=args.gamma, noise_map=noise)
+
+ else:
+ c_t = F.to_tensor(input_image).unsqueeze(0).cuda()
+ if args.use_fp16:
+ c_t = c_t.half()
+ output_image = model(c_t, args.prompt)
+
+ output_pil = transforms.ToPILImage()(output_image[0].cpu() * 0.5 + 0.5)
+
+ # save the output image
+ output_pil.save(os.path.join(args.output_dir, bname))
diff --git a/src/inference_unpaired.py b/src/inference_unpaired.py
new file mode 100644
index 0000000000000000000000000000000000000000..abb720d0a7e6d1ece34d2bbe0169adc560be05fb
--- /dev/null
+++ b/src/inference_unpaired.py
@@ -0,0 +1,58 @@
+import os
+import argparse
+from PIL import Image
+import torch
+from torchvision import transforms
+from cyclegan_turbo import CycleGAN_Turbo
+from my_utils.training_utils import build_transform
+
+
+if __name__ == "__main__":
+ parser = argparse.ArgumentParser()
+ parser.add_argument('--input_image', type=str, required=True, help='path to the input image')
+ parser.add_argument('--prompt', type=str, required=False, help='the prompt to be used. It is required when loading a custom model_path.')
+ parser.add_argument('--model_name', type=str, default=None, help='name of the pretrained model to be used')
+ parser.add_argument('--model_path', type=str, default=None, help='path to a local model state dict to be used')
+ parser.add_argument('--output_dir', type=str, default='output', help='the directory to save the output')
+ parser.add_argument('--image_prep', type=str, default='resize_512x512', help='the image preparation method')
+ parser.add_argument('--direction', type=str, default=None, help='the direction of translation. None for pretrained models, a2b or b2a for custom paths.')
+ parser.add_argument('--use_fp16', action='store_true', help='Use Float16 precision for faster inference')
+ args = parser.parse_args()
+
+ # only one of model_name and model_path should be provided
+ if args.model_name is None != args.model_path is None:
+ raise ValueError('Either model_name or model_path should be provided')
+
+ if args.model_path is not None and args.prompt is None:
+ raise ValueError('prompt is required when loading a custom model_path.')
+
+ if args.model_name is not None:
+ assert args.prompt is None, 'prompt is not required when loading a pretrained model.'
+ assert args.direction is None, 'direction is not required when loading a pretrained model.'
+
+ # initialize the model
+ model = CycleGAN_Turbo(pretrained_name=args.model_name, pretrained_path=args.model_path)
+ model.eval()
+ model.unet.enable_xformers_memory_efficient_attention()
+ if args.use_fp16:
+ model.half()
+
+ T_val = build_transform(args.image_prep)
+
+ input_image = Image.open(args.input_image).convert('RGB')
+ # translate the image
+ with torch.no_grad():
+ input_img = T_val(input_image)
+ x_t = transforms.ToTensor()(input_img)
+ x_t = transforms.Normalize([0.5], [0.5])(x_t).unsqueeze(0).cuda()
+ if args.use_fp16:
+ x_t = x_t.half()
+ output = model(x_t, direction=args.direction, caption=args.prompt)
+
+ output_pil = transforms.ToPILImage()(output[0].cpu() * 0.5 + 0.5)
+ output_pil = output_pil.resize((input_image.width, input_image.height), Image.LANCZOS)
+
+ # save the output image
+ bname = os.path.basename(args.input_image)
+ os.makedirs(args.output_dir, exist_ok=True)
+ output_pil.save(os.path.join(args.output_dir, bname))
diff --git a/src/model.py b/src/model.py
new file mode 100644
index 0000000000000000000000000000000000000000..5dc311e2bc88e281114ce9d04fb4bc7bc21bbf01
--- /dev/null
+++ b/src/model.py
@@ -0,0 +1,73 @@
+import os
+import requests
+from tqdm import tqdm
+from diffusers import DDPMScheduler
+
+
+def make_1step_sched():
+ noise_scheduler_1step = DDPMScheduler.from_pretrained("stabilityai/sd-turbo", subfolder="scheduler")
+ noise_scheduler_1step.set_timesteps(1, device="cuda")
+ noise_scheduler_1step.alphas_cumprod = noise_scheduler_1step.alphas_cumprod.cuda()
+ return noise_scheduler_1step
+
+
+def my_vae_encoder_fwd(self, sample):
+ sample = self.conv_in(sample)
+ l_blocks = []
+ # down
+ for down_block in self.down_blocks:
+ l_blocks.append(sample)
+ sample = down_block(sample)
+ # middle
+ sample = self.mid_block(sample)
+ sample = self.conv_norm_out(sample)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+ self.current_down_blocks = l_blocks
+ return sample
+
+
+def my_vae_decoder_fwd(self, sample, latent_embeds=None):
+ sample = self.conv_in(sample)
+ upscale_dtype = next(iter(self.up_blocks.parameters())).dtype
+ # middle
+ sample = self.mid_block(sample, latent_embeds)
+ sample = sample.to(upscale_dtype)
+ if not self.ignore_skip:
+ skip_convs = [self.skip_conv_1, self.skip_conv_2, self.skip_conv_3, self.skip_conv_4]
+ # up
+ for idx, up_block in enumerate(self.up_blocks):
+ skip_in = skip_convs[idx](self.incoming_skip_acts[::-1][idx] * self.gamma)
+ # add skip
+ sample = sample + skip_in
+ sample = up_block(sample, latent_embeds)
+ else:
+ for idx, up_block in enumerate(self.up_blocks):
+ sample = up_block(sample, latent_embeds)
+ # post-process
+ if latent_embeds is None:
+ sample = self.conv_norm_out(sample)
+ else:
+ sample = self.conv_norm_out(sample, latent_embeds)
+ sample = self.conv_act(sample)
+ sample = self.conv_out(sample)
+ return sample
+
+
+def download_url(url, outf):
+ if not os.path.exists(outf):
+ print(f"Downloading checkpoint to {outf}")
+ response = requests.get(url, stream=True)
+ total_size_in_bytes = int(response.headers.get('content-length', 0))
+ block_size = 1024 # 1 Kibibyte
+ progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True)
+ with open(outf, 'wb') as file:
+ for data in response.iter_content(block_size):
+ progress_bar.update(len(data))
+ file.write(data)
+ progress_bar.close()
+ if total_size_in_bytes != 0 and progress_bar.n != total_size_in_bytes:
+ print("ERROR, something went wrong")
+ print(f"Downloaded successfully to {outf}")
+ else:
+ print(f"Skipping download, {outf} already exists")
diff --git a/src/my_utils/dino_struct.py b/src/my_utils/dino_struct.py
new file mode 100644
index 0000000000000000000000000000000000000000..d2721c9b61b5fbef650e5c9e2133c93a6b6a4ea4
--- /dev/null
+++ b/src/my_utils/dino_struct.py
@@ -0,0 +1,185 @@
+import torch
+import torchvision
+import torch.nn.functional as F
+
+
+def attn_cosine_sim(x, eps=1e-08):
+ x = x[0] # TEMP: getting rid of redundant dimension, TBF
+ norm1 = x.norm(dim=2, keepdim=True)
+ factor = torch.clamp(norm1 @ norm1.permute(0, 2, 1), min=eps)
+ sim_matrix = (x @ x.permute(0, 2, 1)) / factor
+ return sim_matrix
+
+
+class VitExtractor:
+ BLOCK_KEY = 'block'
+ ATTN_KEY = 'attn'
+ PATCH_IMD_KEY = 'patch_imd'
+ QKV_KEY = 'qkv'
+ KEY_LIST = [BLOCK_KEY, ATTN_KEY, PATCH_IMD_KEY, QKV_KEY]
+
+ def __init__(self, model_name, device):
+ # pdb.set_trace()
+ self.model = torch.hub.load('facebookresearch/dino:main', model_name).to(device)
+ self.model.eval()
+ self.model_name = model_name
+ self.hook_handlers = []
+ self.layers_dict = {}
+ self.outputs_dict = {}
+ for key in VitExtractor.KEY_LIST:
+ self.layers_dict[key] = []
+ self.outputs_dict[key] = []
+ self._init_hooks_data()
+
+ def _init_hooks_data(self):
+ self.layers_dict[VitExtractor.BLOCK_KEY] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
+ self.layers_dict[VitExtractor.ATTN_KEY] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
+ self.layers_dict[VitExtractor.QKV_KEY] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
+ self.layers_dict[VitExtractor.PATCH_IMD_KEY] = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
+ for key in VitExtractor.KEY_LIST:
+ # self.layers_dict[key] = kwargs[key] if key in kwargs.keys() else []
+ self.outputs_dict[key] = []
+
+ def _register_hooks(self, **kwargs):
+ for block_idx, block in enumerate(self.model.blocks):
+ if block_idx in self.layers_dict[VitExtractor.BLOCK_KEY]:
+ self.hook_handlers.append(block.register_forward_hook(self._get_block_hook()))
+ if block_idx in self.layers_dict[VitExtractor.ATTN_KEY]:
+ self.hook_handlers.append(block.attn.attn_drop.register_forward_hook(self._get_attn_hook()))
+ if block_idx in self.layers_dict[VitExtractor.QKV_KEY]:
+ self.hook_handlers.append(block.attn.qkv.register_forward_hook(self._get_qkv_hook()))
+ if block_idx in self.layers_dict[VitExtractor.PATCH_IMD_KEY]:
+ self.hook_handlers.append(block.attn.register_forward_hook(self._get_patch_imd_hook()))
+
+ def _clear_hooks(self):
+ for handler in self.hook_handlers:
+ handler.remove()
+ self.hook_handlers = []
+
+ def _get_block_hook(self):
+ def _get_block_output(model, input, output):
+ self.outputs_dict[VitExtractor.BLOCK_KEY].append(output)
+
+ return _get_block_output
+
+ def _get_attn_hook(self):
+ def _get_attn_output(model, inp, output):
+ self.outputs_dict[VitExtractor.ATTN_KEY].append(output)
+
+ return _get_attn_output
+
+ def _get_qkv_hook(self):
+ def _get_qkv_output(model, inp, output):
+ self.outputs_dict[VitExtractor.QKV_KEY].append(output)
+
+ return _get_qkv_output
+
+ # TODO: CHECK ATTN OUTPUT TUPLE
+ def _get_patch_imd_hook(self):
+ def _get_attn_output(model, inp, output):
+ self.outputs_dict[VitExtractor.PATCH_IMD_KEY].append(output[0])
+
+ return _get_attn_output
+
+ def get_feature_from_input(self, input_img): # List([B, N, D])
+ self._register_hooks()
+ self.model(input_img)
+ feature = self.outputs_dict[VitExtractor.BLOCK_KEY]
+ self._clear_hooks()
+ self._init_hooks_data()
+ return feature
+
+ def get_qkv_feature_from_input(self, input_img):
+ self._register_hooks()
+ self.model(input_img)
+ feature = self.outputs_dict[VitExtractor.QKV_KEY]
+ self._clear_hooks()
+ self._init_hooks_data()
+ return feature
+
+ def get_attn_feature_from_input(self, input_img):
+ self._register_hooks()
+ self.model(input_img)
+ feature = self.outputs_dict[VitExtractor.ATTN_KEY]
+ self._clear_hooks()
+ self._init_hooks_data()
+ return feature
+
+ def get_patch_size(self):
+ return 8 if "8" in self.model_name else 16
+
+ def get_width_patch_num(self, input_img_shape):
+ b, c, h, w = input_img_shape
+ patch_size = self.get_patch_size()
+ return w // patch_size
+
+ def get_height_patch_num(self, input_img_shape):
+ b, c, h, w = input_img_shape
+ patch_size = self.get_patch_size()
+ return h // patch_size
+
+ def get_patch_num(self, input_img_shape):
+ patch_num = 1 + (self.get_height_patch_num(input_img_shape) * self.get_width_patch_num(input_img_shape))
+ return patch_num
+
+ def get_head_num(self):
+ if "dino" in self.model_name:
+ return 6 if "s" in self.model_name else 12
+ return 6 if "small" in self.model_name else 12
+
+ def get_embedding_dim(self):
+ if "dino" in self.model_name:
+ return 384 if "s" in self.model_name else 768
+ return 384 if "small" in self.model_name else 768
+
+ def get_queries_from_qkv(self, qkv, input_img_shape):
+ patch_num = self.get_patch_num(input_img_shape)
+ head_num = self.get_head_num()
+ embedding_dim = self.get_embedding_dim()
+ q = qkv.reshape(patch_num, 3, head_num, embedding_dim // head_num).permute(1, 2, 0, 3)[0]
+ return q
+
+ def get_keys_from_qkv(self, qkv, input_img_shape):
+ patch_num = self.get_patch_num(input_img_shape)
+ head_num = self.get_head_num()
+ embedding_dim = self.get_embedding_dim()
+ k = qkv.reshape(patch_num, 3, head_num, embedding_dim // head_num).permute(1, 2, 0, 3)[1]
+ return k
+
+ def get_values_from_qkv(self, qkv, input_img_shape):
+ patch_num = self.get_patch_num(input_img_shape)
+ head_num = self.get_head_num()
+ embedding_dim = self.get_embedding_dim()
+ v = qkv.reshape(patch_num, 3, head_num, embedding_dim // head_num).permute(1, 2, 0, 3)[2]
+ return v
+
+ def get_keys_from_input(self, input_img, layer_num):
+ qkv_features = self.get_qkv_feature_from_input(input_img)[layer_num]
+ keys = self.get_keys_from_qkv(qkv_features, input_img.shape)
+ return keys
+
+ def get_keys_self_sim_from_input(self, input_img, layer_num):
+ keys = self.get_keys_from_input(input_img, layer_num=layer_num)
+ h, t, d = keys.shape
+ concatenated_keys = keys.transpose(0, 1).reshape(t, h * d)
+ ssim_map = attn_cosine_sim(concatenated_keys[None, None, ...])
+ return ssim_map
+
+
+class DinoStructureLoss:
+ def __init__(self, ):
+ self.extractor = VitExtractor(model_name="dino_vitb8", device="cuda")
+ self.preprocess = torchvision.transforms.Compose([
+ torchvision.transforms.Resize(224),
+ torchvision.transforms.ToTensor(),
+ torchvision.transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
+ ])
+
+ def calculate_global_ssim_loss(self, outputs, inputs):
+ loss = 0.0
+ for a, b in zip(inputs, outputs): # avoid memory limitations
+ with torch.no_grad():
+ target_keys_self_sim = self.extractor.get_keys_self_sim_from_input(a.unsqueeze(0), layer_num=11)
+ keys_ssim = self.extractor.get_keys_self_sim_from_input(b.unsqueeze(0), layer_num=11)
+ loss += F.mse_loss(keys_ssim, target_keys_self_sim)
+ return loss
diff --git a/src/my_utils/training_utils.py b/src/my_utils/training_utils.py
new file mode 100644
index 0000000000000000000000000000000000000000..f0819b71b02a6126b4b52a472223abfae1e7a72d
--- /dev/null
+++ b/src/my_utils/training_utils.py
@@ -0,0 +1,409 @@
+import os
+import random
+import argparse
+import json
+import torch
+from PIL import Image
+from torchvision import transforms
+import torchvision.transforms.functional as F
+from glob import glob
+
+
+def parse_args_paired_training(input_args=None):
+ """
+ Parses command-line arguments used for configuring an paired session (pix2pix-Turbo).
+ This function sets up an argument parser to handle various training options.
+
+ Returns:
+ argparse.Namespace: The parsed command-line arguments.
+ """
+ parser = argparse.ArgumentParser()
+ # args for the loss function
+ parser.add_argument("--gan_disc_type", default="vagan_clip")
+ parser.add_argument("--gan_loss_type", default="multilevel_sigmoid_s")
+ parser.add_argument("--lambda_gan", default=0.5, type=float)
+ parser.add_argument("--lambda_lpips", default=5, type=float)
+ parser.add_argument("--lambda_l2", default=1.0, type=float)
+ parser.add_argument("--lambda_clipsim", default=5.0, type=float)
+
+ # dataset options
+ parser.add_argument("--dataset_folder", required=True, type=str)
+ parser.add_argument("--train_image_prep", default="resized_crop_512", type=str)
+ parser.add_argument("--test_image_prep", default="resized_crop_512", type=str)
+
+ # validation eval args
+ parser.add_argument("--eval_freq", default=100, type=int)
+ parser.add_argument("--track_val_fid", default=False, action="store_true")
+ parser.add_argument("--num_samples_eval", type=int, default=100, help="Number of samples to use for all evaluation")
+
+ parser.add_argument("--viz_freq", type=int, default=100, help="Frequency of visualizing the outputs.")
+ parser.add_argument("--tracker_project_name", type=str, default="train_pix2pix_turbo", help="The name of the wandb project to log to.")
+
+ # details about the model architecture
+ parser.add_argument("--pretrained_model_name_or_path")
+ parser.add_argument("--revision", type=str, default=None,)
+ parser.add_argument("--variant", type=str, default=None,)
+ parser.add_argument("--tokenizer_name", type=str, default=None)
+ parser.add_argument("--lora_rank_unet", default=8, type=int)
+ parser.add_argument("--lora_rank_vae", default=4, type=int)
+
+ # training details
+ parser.add_argument("--output_dir", required=True)
+ parser.add_argument("--cache_dir", default=None,)
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument("--resolution", type=int, default=512,)
+ parser.add_argument("--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader.")
+ parser.add_argument("--num_training_epochs", type=int, default=10)
+ parser.add_argument("--max_train_steps", type=int, default=10_000,)
+ parser.add_argument("--checkpointing_steps", type=int, default=500,)
+ parser.add_argument("--gradient_accumulation_steps", type=int, default=1, help="Number of updates steps to accumulate before performing a backward/update pass.",)
+ parser.add_argument("--gradient_checkpointing", action="store_true",)
+ parser.add_argument("--learning_rate", type=float, default=5e-6)
+ parser.add_argument("--lr_scheduler", type=str, default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument("--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler.")
+ parser.add_argument("--lr_num_cycles", type=int, default=1,
+ help="Number of hard resets of the lr in cosine_with_restarts scheduler.",
+ )
+ parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
+
+ parser.add_argument("--dataloader_num_workers", type=int, default=0,)
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--allow_tf32", action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument("--report_to", type=str, default="wandb",
+ help=(
+ 'The integration to report the results and logs to. Supported platforms are `"tensorboard"`'
+ ' (default), `"wandb"` and `"comet_ml"`. Use `"all"` to report to all integrations.'
+ ),
+ )
+ parser.add_argument("--mixed_precision", type=str, default=None, choices=["no", "fp16", "bf16"],)
+ parser.add_argument("--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers.")
+ parser.add_argument("--set_grads_to_none", action="store_true",)
+
+ if input_args is not None:
+ args = parser.parse_args(input_args)
+ else:
+ args = parser.parse_args()
+
+ return args
+
+
+def parse_args_unpaired_training():
+ """
+ Parses command-line arguments used for configuring an unpaired session (CycleGAN-Turbo).
+ This function sets up an argument parser to handle various training options.
+
+ Returns:
+ argparse.Namespace: The parsed command-line arguments.
+ """
+
+ parser = argparse.ArgumentParser(description="Simple example of a ControlNet training script.")
+
+ # fixed random seed
+ parser.add_argument("--seed", type=int, default=42, help="A seed for reproducible training.")
+
+ # args for the loss function
+ parser.add_argument("--gan_disc_type", default="vagan_clip")
+ parser.add_argument("--gan_loss_type", default="multilevel_sigmoid")
+ parser.add_argument("--lambda_gan", default=0.5, type=float)
+ parser.add_argument("--lambda_idt", default=1, type=float)
+ parser.add_argument("--lambda_cycle", default=1, type=float)
+ parser.add_argument("--lambda_cycle_lpips", default=10.0, type=float)
+ parser.add_argument("--lambda_idt_lpips", default=1.0, type=float)
+
+ # args for dataset and dataloader options
+ parser.add_argument("--dataset_folder", required=True, type=str)
+ parser.add_argument("--train_img_prep", required=True)
+ parser.add_argument("--val_img_prep", required=True)
+ parser.add_argument("--dataloader_num_workers", type=int, default=0)
+ parser.add_argument("--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader.")
+ parser.add_argument("--max_train_epochs", type=int, default=100)
+ parser.add_argument("--max_train_steps", type=int, default=None)
+
+ # args for the model
+ parser.add_argument("--pretrained_model_name_or_path", default="stabilityai/sd-turbo")
+ parser.add_argument("--revision", default=None, type=str)
+ parser.add_argument("--variant", default=None, type=str)
+ parser.add_argument("--lora_rank_unet", default=128, type=int)
+ parser.add_argument("--lora_rank_vae", default=4, type=int)
+
+ # args for validation and logging
+ parser.add_argument("--viz_freq", type=int, default=20)
+ parser.add_argument("--output_dir", type=str, required=True)
+ parser.add_argument("--report_to", type=str, default="wandb")
+ parser.add_argument("--tracker_project_name", type=str, required=True)
+ parser.add_argument("--validation_steps", type=int, default=500,)
+ parser.add_argument("--validation_num_images", type=int, default=-1, help="Number of images to use for validation. -1 to use all images.")
+ parser.add_argument("--checkpointing_steps", type=int, default=500)
+
+ # args for the optimization options
+ parser.add_argument("--learning_rate", type=float, default=5e-6,)
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=10.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--lr_scheduler", type=str, default="constant", help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument("--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler.")
+ parser.add_argument("--lr_num_cycles", type=int, default=1, help="Number of hard resets of the lr in cosine_with_restarts scheduler.",)
+ parser.add_argument("--lr_power", type=float, default=1.0, help="Power factor of the polynomial scheduler.")
+ parser.add_argument("--gradient_accumulation_steps", type=int, default=1)
+
+ # memory saving options
+ parser.add_argument("--allow_tf32", action="store_true",
+ help=(
+ "Whether or not to allow TF32 on Ampere GPUs. Can be used to speed up training. For more information, see"
+ " https://pytorch.org/docs/stable/notes/cuda.html#tensorfloat-32-tf32-on-ampere-devices"
+ ),
+ )
+ parser.add_argument("--gradient_checkpointing", action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.")
+ parser.add_argument("--enable_xformers_memory_efficient_attention", action="store_true", help="Whether or not to use xformers.")
+
+ args = parser.parse_args()
+ return args
+
+
+def build_transform(image_prep):
+ """
+ Constructs a transformation pipeline based on the specified image preparation method.
+
+ Parameters:
+ - image_prep (str): A string describing the desired image preparation
+
+ Returns:
+ - torchvision.transforms.Compose: A composable sequence of transformations to be applied to images.
+ """
+ if image_prep == "resized_crop_512":
+ T = transforms.Compose([
+ transforms.Resize(512, interpolation=transforms.InterpolationMode.LANCZOS),
+ transforms.CenterCrop(512),
+ ])
+ elif image_prep == "resize_286_randomcrop_256x256_hflip":
+ T = transforms.Compose([
+ transforms.Resize((286, 286), interpolation=Image.LANCZOS),
+ transforms.RandomCrop((256, 256)),
+ transforms.RandomHorizontalFlip(),
+ ])
+ elif image_prep in ["resize_256", "resize_256x256"]:
+ T = transforms.Compose([
+ transforms.Resize((256, 256), interpolation=Image.LANCZOS)
+ ])
+ elif image_prep in ["resize_512", "resize_512x512"]:
+ T = transforms.Compose([
+ transforms.Resize((512, 512), interpolation=Image.LANCZOS)
+ ])
+ elif image_prep == "no_resize":
+ T = transforms.Lambda(lambda x: x)
+ return T
+
+
+class PairedDataset(torch.utils.data.Dataset):
+ def __init__(self, dataset_folder, split, image_prep, tokenizer):
+ """
+ Itialize the paired dataset object for loading and transforming paired data samples
+ from specified dataset folders.
+
+ This constructor sets up the paths to input and output folders based on the specified 'split',
+ loads the captions (or prompts) for the input images, and prepares the transformations and
+ tokenizer to be applied on the data.
+
+ Parameters:
+ - dataset_folder (str): The root folder containing the dataset, expected to include
+ sub-folders for different splits (e.g., 'train_A', 'train_B').
+ - split (str): The dataset split to use ('train' or 'test'), used to select the appropriate
+ sub-folders and caption files within the dataset folder.
+ - image_prep (str): The image preprocessing transformation to apply to each image.
+ - tokenizer: The tokenizer used for tokenizing the captions (or prompts).
+ """
+ super().__init__()
+ if split == "train":
+ self.input_folder = os.path.join(dataset_folder, "train_A")
+ self.output_folder = os.path.join(dataset_folder, "train_B")
+ captions = os.path.join(dataset_folder, "train_prompts.json")
+ elif split == "test":
+ self.input_folder = os.path.join(dataset_folder, "test_A")
+ self.output_folder = os.path.join(dataset_folder, "test_B")
+ captions = os.path.join(dataset_folder, "test_prompts.json")
+ with open(captions, "r") as f:
+ self.captions = json.load(f)
+ self.img_names = list(self.captions.keys())
+ self.T = build_transform(image_prep)
+ self.tokenizer = tokenizer
+
+ def __len__(self):
+ """
+ Returns:
+ int: The total number of items in the dataset.
+ """
+ return len(self.captions)
+
+ def __getitem__(self, idx):
+ """
+ Retrieves a dataset item given its index. Each item consists of an input image,
+ its corresponding output image, the captions associated with the input image,
+ and the tokenized form of this caption.
+
+ This method performs the necessary preprocessing on both the input and output images,
+ including scaling and normalization, as well as tokenizing the caption using a provided tokenizer.
+
+ Parameters:
+ - idx (int): The index of the item to retrieve.
+
+ Returns:
+ dict: A dictionary containing the following key-value pairs:
+ - "output_pixel_values": a tensor of the preprocessed output image with pixel values
+ scaled to [-1, 1].
+ - "conditioning_pixel_values": a tensor of the preprocessed input image with pixel values
+ scaled to [0, 1].
+ - "caption": the text caption.
+ - "input_ids": a tensor of the tokenized caption.
+
+ Note:
+ The actual preprocessing steps (scaling and normalization) for images are defined externally
+ and passed to this class through the `image_prep` parameter during initialization. The
+ tokenization process relies on the `tokenizer` also provided at initialization, which
+ should be compatible with the models intended to be used with this dataset.
+ """
+ img_name = self.img_names[idx]
+ input_img = Image.open(os.path.join(self.input_folder, img_name))
+ output_img = Image.open(os.path.join(self.output_folder, img_name))
+ caption = self.captions[img_name]
+
+ # input images scaled to 0,1
+ img_t = self.T(input_img)
+ img_t = F.to_tensor(img_t)
+ # output images scaled to -1,1
+ output_t = self.T(output_img)
+ output_t = F.to_tensor(output_t)
+ output_t = F.normalize(output_t, mean=[0.5], std=[0.5])
+
+ input_ids = self.tokenizer(
+ caption, max_length=self.tokenizer.model_max_length,
+ padding="max_length", truncation=True, return_tensors="pt"
+ ).input_ids
+
+ return {
+ "output_pixel_values": output_t,
+ "conditioning_pixel_values": img_t,
+ "caption": caption,
+ "input_ids": input_ids,
+ }
+
+
+class UnpairedDataset(torch.utils.data.Dataset):
+ def __init__(self, dataset_folder, split, image_prep, tokenizer):
+ """
+ A dataset class for loading unpaired data samples from two distinct domains (source and target),
+ typically used in unsupervised learning tasks like image-to-image translation.
+
+ The class supports loading images from specified dataset folders, applying predefined image
+ preprocessing transformations, and utilizing fixed textual prompts (captions) for each domain,
+ tokenized using a provided tokenizer.
+
+ Parameters:
+ - dataset_folder (str): Base directory of the dataset containing subdirectories (train_A, train_B, test_A, test_B)
+ - split (str): Indicates the dataset split to use. Expected values are 'train' or 'test'.
+ - image_prep (str): he image preprocessing transformation to apply to each image.
+ - tokenizer: The tokenizer used for tokenizing the captions (or prompts).
+ """
+ super().__init__()
+ if split == "train":
+ self.source_folder = os.path.join(dataset_folder, "train_A")
+ self.target_folder = os.path.join(dataset_folder, "train_B")
+ elif split == "test":
+ self.source_folder = os.path.join(dataset_folder, "test_A")
+ self.target_folder = os.path.join(dataset_folder, "test_B")
+ self.tokenizer = tokenizer
+ with open(os.path.join(dataset_folder, "fixed_prompt_a.txt"), "r") as f:
+ self.fixed_caption_src = f.read().strip()
+ self.input_ids_src = self.tokenizer(
+ self.fixed_caption_src, max_length=self.tokenizer.model_max_length,
+ padding="max_length", truncation=True, return_tensors="pt"
+ ).input_ids
+
+ with open(os.path.join(dataset_folder, "fixed_prompt_b.txt"), "r") as f:
+ self.fixed_caption_tgt = f.read().strip()
+ self.input_ids_tgt = self.tokenizer(
+ self.fixed_caption_tgt, max_length=self.tokenizer.model_max_length,
+ padding="max_length", truncation=True, return_tensors="pt"
+ ).input_ids
+ # find all images in the source and target folders with all IMG extensions
+ self.l_imgs_src = []
+ for ext in ["*.jpg", "*.jpeg", "*.png", "*.bmp", "*.gif"]:
+ self.l_imgs_src.extend(glob(os.path.join(self.source_folder, ext)))
+ self.l_imgs_tgt = []
+ for ext in ["*.jpg", "*.jpeg", "*.png", "*.bmp", "*.gif"]:
+ self.l_imgs_tgt.extend(glob(os.path.join(self.target_folder, ext)))
+ self.T = build_transform(image_prep)
+
+ def __len__(self):
+ """
+ Returns:
+ int: The total number of items in the dataset.
+ """
+ return len(self.l_imgs_src) + len(self.l_imgs_tgt)
+
+ def __getitem__(self, index):
+ """
+ Fetches a pair of unaligned images from the source and target domains along with their
+ corresponding tokenized captions.
+
+ For the source domain, if the requested index is within the range of available images,
+ the specific image at that index is chosen. If the index exceeds the number of source
+ images, a random source image is selected. For the target domain,
+ an image is always randomly selected, irrespective of the index, to maintain the
+ unpaired nature of the dataset.
+
+ Both images are preprocessed according to the specified image transformation `T`, and normalized.
+ The fixed captions for both domains
+ are included along with their tokenized forms.
+
+ Parameters:
+ - index (int): The index of the source image to retrieve.
+
+ Returns:
+ dict: A dictionary containing processed data for a single training example, with the following keys:
+ - "pixel_values_src": The processed source image
+ - "pixel_values_tgt": The processed target image
+ - "caption_src": The fixed caption of the source domain.
+ - "caption_tgt": The fixed caption of the target domain.
+ - "input_ids_src": The source domain's fixed caption tokenized.
+ - "input_ids_tgt": The target domain's fixed caption tokenized.
+ """
+ if index < len(self.l_imgs_src):
+ img_path_src = self.l_imgs_src[index]
+ else:
+ img_path_src = random.choice(self.l_imgs_src)
+ img_path_tgt = random.choice(self.l_imgs_tgt)
+ img_pil_src = Image.open(img_path_src).convert("RGB")
+ img_pil_tgt = Image.open(img_path_tgt).convert("RGB")
+ img_t_src = F.to_tensor(self.T(img_pil_src))
+ img_t_tgt = F.to_tensor(self.T(img_pil_tgt))
+ img_t_src = F.normalize(img_t_src, mean=[0.5], std=[0.5])
+ img_t_tgt = F.normalize(img_t_tgt, mean=[0.5], std=[0.5])
+ return {
+ "pixel_values_src": img_t_src,
+ "pixel_values_tgt": img_t_tgt,
+ "caption_src": self.fixed_caption_src,
+ "caption_tgt": self.fixed_caption_tgt,
+ "input_ids_src": self.input_ids_src,
+ "input_ids_tgt": self.input_ids_tgt,
+ }
diff --git a/src/pix2pix_turbo.py b/src/pix2pix_turbo.py
new file mode 100644
index 0000000000000000000000000000000000000000..30ca81fdccde5cab66d39d823e09e27146e2c0fd
--- /dev/null
+++ b/src/pix2pix_turbo.py
@@ -0,0 +1,229 @@
+import os
+import requests
+import sys
+import copy
+from tqdm import tqdm
+import torch
+from transformers import AutoTokenizer, CLIPTextModel
+from diffusers import AutoencoderKL, UNet2DConditionModel
+from diffusers.utils.peft_utils import set_weights_and_activate_adapters
+from peft import LoraConfig
+p = "src/"
+sys.path.append(p)
+from model import make_1step_sched, my_vae_encoder_fwd, my_vae_decoder_fwd
+
+
+class TwinConv(torch.nn.Module):
+ def __init__(self, convin_pretrained, convin_curr):
+ super(TwinConv, self).__init__()
+ self.conv_in_pretrained = copy.deepcopy(convin_pretrained)
+ self.conv_in_curr = copy.deepcopy(convin_curr)
+ self.r = None
+
+ def forward(self, x):
+ x1 = self.conv_in_pretrained(x).detach()
+ x2 = self.conv_in_curr(x)
+ return x1 * (1 - self.r) + x2 * (self.r)
+
+
+class Pix2Pix_Turbo(torch.nn.Module):
+ def __init__(self, pretrained_name=None, pretrained_path=None, ckpt_folder="checkpoints", lora_rank_unet=8, lora_rank_vae=4):
+ super().__init__()
+ self.tokenizer = AutoTokenizer.from_pretrained("stabilityai/sd-turbo", subfolder="tokenizer")
+ self.text_encoder = CLIPTextModel.from_pretrained("stabilityai/sd-turbo", subfolder="text_encoder").cuda()
+ self.sched = make_1step_sched()
+
+ vae = AutoencoderKL.from_pretrained("stabilityai/sd-turbo", subfolder="vae")
+ vae.encoder.forward = my_vae_encoder_fwd.__get__(vae.encoder, vae.encoder.__class__)
+ vae.decoder.forward = my_vae_decoder_fwd.__get__(vae.decoder, vae.decoder.__class__)
+ # add the skip connection convs
+ vae.decoder.skip_conv_1 = torch.nn.Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_2 = torch.nn.Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_3 = torch.nn.Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.skip_conv_4 = torch.nn.Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False).cuda()
+ vae.decoder.ignore_skip = False
+ unet = UNet2DConditionModel.from_pretrained("stabilityai/sd-turbo", subfolder="unet")
+
+ if pretrained_name == "edge_to_image":
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/edge_to_image_loras.pkl"
+ os.makedirs(ckpt_folder, exist_ok=True)
+ outf = os.path.join(ckpt_folder, "edge_to_image_loras.pkl")
+ if not os.path.exists(outf):
+ print(f"Downloading checkpoint to {outf}")
+ response = requests.get(url, stream=True)
+ total_size_in_bytes = int(response.headers.get('content-length', 0))
+ block_size = 1024 # 1 Kibibyte
+ progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True)
+ with open(outf, 'wb') as file:
+ for data in response.iter_content(block_size):
+ progress_bar.update(len(data))
+ file.write(data)
+ progress_bar.close()
+ if total_size_in_bytes != 0 and progress_bar.n != total_size_in_bytes:
+ print("ERROR, something went wrong")
+ print(f"Downloaded successfully to {outf}")
+ p_ckpt = outf
+ sd = torch.load(p_ckpt, map_location="cpu")
+ unet_lora_config = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["unet_lora_target_modules"])
+ vae_lora_config = LoraConfig(r=sd["rank_vae"], init_lora_weights="gaussian", target_modules=sd["vae_lora_target_modules"])
+ vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ _sd_vae = vae.state_dict()
+ for k in sd["state_dict_vae"]:
+ _sd_vae[k] = sd["state_dict_vae"][k]
+ vae.load_state_dict(_sd_vae)
+ unet.add_adapter(unet_lora_config)
+ _sd_unet = unet.state_dict()
+ for k in sd["state_dict_unet"]:
+ _sd_unet[k] = sd["state_dict_unet"][k]
+ unet.load_state_dict(_sd_unet)
+
+ elif pretrained_name == "sketch_to_image_stochastic":
+ # download from url
+ url = "https://www.cs.cmu.edu/~img2img-turbo/models/sketch_to_image_stochastic_lora.pkl"
+ os.makedirs(ckpt_folder, exist_ok=True)
+ outf = os.path.join(ckpt_folder, "sketch_to_image_stochastic_lora.pkl")
+ if not os.path.exists(outf):
+ print(f"Downloading checkpoint to {outf}")
+ response = requests.get(url, stream=True)
+ total_size_in_bytes = int(response.headers.get('content-length', 0))
+ block_size = 1024 # 1 Kibibyte
+ progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True)
+ with open(outf, 'wb') as file:
+ for data in response.iter_content(block_size):
+ progress_bar.update(len(data))
+ file.write(data)
+ progress_bar.close()
+ if total_size_in_bytes != 0 and progress_bar.n != total_size_in_bytes:
+ print("ERROR, something went wrong")
+ print(f"Downloaded successfully to {outf}")
+ p_ckpt = outf
+ convin_pretrained = copy.deepcopy(unet.conv_in)
+ unet.conv_in = TwinConv(convin_pretrained, unet.conv_in)
+ sd = torch.load(p_ckpt, map_location="cpu")
+ unet_lora_config = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["unet_lora_target_modules"])
+ vae_lora_config = LoraConfig(r=sd["rank_vae"], init_lora_weights="gaussian", target_modules=sd["vae_lora_target_modules"])
+ vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ _sd_vae = vae.state_dict()
+ for k in sd["state_dict_vae"]:
+ _sd_vae[k] = sd["state_dict_vae"][k]
+ vae.load_state_dict(_sd_vae)
+ unet.add_adapter(unet_lora_config)
+ _sd_unet = unet.state_dict()
+ for k in sd["state_dict_unet"]:
+ _sd_unet[k] = sd["state_dict_unet"][k]
+ unet.load_state_dict(_sd_unet)
+
+ elif pretrained_path is not None:
+ sd = torch.load(pretrained_path, map_location="cpu")
+ unet_lora_config = LoraConfig(r=sd["rank_unet"], init_lora_weights="gaussian", target_modules=sd["unet_lora_target_modules"])
+ vae_lora_config = LoraConfig(r=sd["rank_vae"], init_lora_weights="gaussian", target_modules=sd["vae_lora_target_modules"])
+ vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ _sd_vae = vae.state_dict()
+ for k in sd["state_dict_vae"]:
+ _sd_vae[k] = sd["state_dict_vae"][k]
+ vae.load_state_dict(_sd_vae)
+ unet.add_adapter(unet_lora_config)
+ _sd_unet = unet.state_dict()
+ for k in sd["state_dict_unet"]:
+ _sd_unet[k] = sd["state_dict_unet"][k]
+ unet.load_state_dict(_sd_unet)
+
+ elif pretrained_name is None and pretrained_path is None:
+ print("Initializing model with random weights")
+ torch.nn.init.constant_(vae.decoder.skip_conv_1.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_2.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_3.weight, 1e-5)
+ torch.nn.init.constant_(vae.decoder.skip_conv_4.weight, 1e-5)
+ target_modules_vae = ["conv1", "conv2", "conv_in", "conv_shortcut", "conv", "conv_out",
+ "skip_conv_1", "skip_conv_2", "skip_conv_3", "skip_conv_4",
+ "to_k", "to_q", "to_v", "to_out.0",
+ ]
+ vae_lora_config = LoraConfig(r=lora_rank_vae, init_lora_weights="gaussian",
+ target_modules=target_modules_vae)
+ vae.add_adapter(vae_lora_config, adapter_name="vae_skip")
+ target_modules_unet = [
+ "to_k", "to_q", "to_v", "to_out.0", "conv", "conv1", "conv2", "conv_shortcut", "conv_out",
+ "proj_in", "proj_out", "ff.net.2", "ff.net.0.proj"
+ ]
+ unet_lora_config = LoraConfig(r=lora_rank_unet, init_lora_weights="gaussian",
+ target_modules=target_modules_unet
+ )
+ unet.add_adapter(unet_lora_config)
+ self.lora_rank_unet = lora_rank_unet
+ self.lora_rank_vae = lora_rank_vae
+ self.target_modules_vae = target_modules_vae
+ self.target_modules_unet = target_modules_unet
+
+ # unet.enable_xformers_memory_efficient_attention()
+ unet.to("cuda")
+ vae.to("cuda")
+ self.unet, self.vae = unet, vae
+ self.vae.decoder.gamma = 1
+ self.timesteps = torch.tensor([999], device="cuda").long()
+ self.text_encoder.requires_grad_(False)
+
+ def set_eval(self):
+ self.unet.eval()
+ self.vae.eval()
+ self.unet.requires_grad_(False)
+ self.vae.requires_grad_(False)
+
+ def set_train(self):
+ self.unet.train()
+ self.vae.train()
+ for n, _p in self.unet.named_parameters():
+ if "lora" in n:
+ _p.requires_grad = True
+ self.unet.conv_in.requires_grad_(True)
+ for n, _p in self.vae.named_parameters():
+ if "lora" in n:
+ _p.requires_grad = True
+ self.vae.decoder.skip_conv_1.requires_grad_(True)
+ self.vae.decoder.skip_conv_2.requires_grad_(True)
+ self.vae.decoder.skip_conv_3.requires_grad_(True)
+ self.vae.decoder.skip_conv_4.requires_grad_(True)
+
+ def forward(self, c_t, prompt=None, prompt_tokens=None, deterministic=True, r=1.0, noise_map=None):
+ # either the prompt or the prompt_tokens should be provided
+ assert (prompt is None) != (prompt_tokens is None), "Either prompt or prompt_tokens should be provided"
+
+ if prompt is not None:
+ # encode the text prompt
+ caption_tokens = self.tokenizer(prompt, max_length=self.tokenizer.model_max_length,
+ padding="max_length", truncation=True, return_tensors="pt").input_ids.cuda()
+ caption_enc = self.text_encoder(caption_tokens)[0]
+ else:
+ caption_enc = self.text_encoder(prompt_tokens)[0]
+ if deterministic:
+ encoded_control = self.vae.encode(c_t).latent_dist.sample() * self.vae.config.scaling_factor
+ model_pred = self.unet(encoded_control, self.timesteps, encoder_hidden_states=caption_enc,).sample
+ x_denoised = self.sched.step(model_pred, self.timesteps, encoded_control, return_dict=True).prev_sample
+ x_denoised = x_denoised.to(model_pred.dtype)
+ self.vae.decoder.incoming_skip_acts = self.vae.encoder.current_down_blocks
+ output_image = (self.vae.decode(x_denoised / self.vae.config.scaling_factor).sample).clamp(-1, 1)
+ else:
+ # scale the lora weights based on the r value
+ self.unet.set_adapters(["default"], weights=[r])
+ set_weights_and_activate_adapters(self.vae, ["vae_skip"], [r])
+ encoded_control = self.vae.encode(c_t).latent_dist.sample() * self.vae.config.scaling_factor
+ # combine the input and noise
+ unet_input = encoded_control * r + noise_map * (1 - r)
+ self.unet.conv_in.r = r
+ unet_output = self.unet(unet_input, self.timesteps, encoder_hidden_states=caption_enc,).sample
+ self.unet.conv_in.r = None
+ x_denoised = self.sched.step(unet_output, self.timesteps, unet_input, return_dict=True).prev_sample
+ x_denoised = x_denoised.to(unet_output.dtype)
+ self.vae.decoder.incoming_skip_acts = self.vae.encoder.current_down_blocks
+ self.vae.decoder.gamma = r
+ output_image = (self.vae.decode(x_denoised / self.vae.config.scaling_factor).sample).clamp(-1, 1)
+ return output_image
+
+ def save_model(self, outf):
+ sd = {}
+ sd["unet_lora_target_modules"] = self.target_modules_unet
+ sd["vae_lora_target_modules"] = self.target_modules_vae
+ sd["rank_unet"] = self.lora_rank_unet
+ sd["rank_vae"] = self.lora_rank_vae
+ sd["state_dict_unet"] = {k: v for k, v in self.unet.state_dict().items() if "lora" in k or "conv_in" in k}
+ sd["state_dict_vae"] = {k: v for k, v in self.vae.state_dict().items() if "lora" in k or "skip" in k}
+ torch.save(sd, outf)
diff --git a/src/train_cyclegan_turbo.py b/src/train_cyclegan_turbo.py
new file mode 100644
index 0000000000000000000000000000000000000000..a51bfc9e8cc4d86383c6ac0df0e22af8bdc7aba2
--- /dev/null
+++ b/src/train_cyclegan_turbo.py
@@ -0,0 +1,390 @@
+import os
+import gc
+import copy
+import lpips
+import torch
+import wandb
+from glob import glob
+import numpy as np
+from accelerate import Accelerator
+from accelerate.utils import set_seed
+from PIL import Image
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import AutoTokenizer, CLIPTextModel
+from diffusers.optimization import get_scheduler
+from peft.utils import get_peft_model_state_dict
+from cleanfid.fid import get_folder_features, build_feature_extractor, frechet_distance
+import vision_aided_loss
+from model import make_1step_sched
+from cyclegan_turbo import CycleGAN_Turbo, VAE_encode, VAE_decode, initialize_unet, initialize_vae
+from my_utils.training_utils import UnpairedDataset, build_transform, parse_args_unpaired_training
+from my_utils.dino_struct import DinoStructureLoss
+
+
+def main(args):
+ accelerator = Accelerator(gradient_accumulation_steps=args.gradient_accumulation_steps, log_with=args.report_to)
+ set_seed(args.seed)
+
+ if accelerator.is_main_process:
+ os.makedirs(os.path.join(args.output_dir, "checkpoints"), exist_ok=True)
+
+ tokenizer = AutoTokenizer.from_pretrained("stabilityai/sd-turbo", subfolder="tokenizer", revision=args.revision, use_fast=False,)
+ noise_scheduler_1step = make_1step_sched()
+ text_encoder = CLIPTextModel.from_pretrained("stabilityai/sd-turbo", subfolder="text_encoder").cuda()
+
+ unet, l_modules_unet_encoder, l_modules_unet_decoder, l_modules_unet_others = initialize_unet(args.lora_rank_unet, return_lora_module_names=True)
+ vae_a2b, vae_lora_target_modules = initialize_vae(args.lora_rank_vae, return_lora_module_names=True)
+
+ weight_dtype = torch.float32
+ vae_a2b.to(accelerator.device, dtype=weight_dtype)
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+ unet.to(accelerator.device, dtype=weight_dtype)
+ text_encoder.requires_grad_(False)
+
+ if args.gan_disc_type == "vagan_clip":
+ net_disc_a = vision_aided_loss.Discriminator(cv_type='clip', loss_type=args.gan_loss_type, device="cuda")
+ net_disc_a.cv_ensemble.requires_grad_(False) # Freeze feature extractor
+ net_disc_b = vision_aided_loss.Discriminator(cv_type='clip', loss_type=args.gan_loss_type, device="cuda")
+ net_disc_b.cv_ensemble.requires_grad_(False) # Freeze feature extractor
+
+ crit_cycle, crit_idt = torch.nn.L1Loss(), torch.nn.L1Loss()
+
+ if args.enable_xformers_memory_efficient_attention:
+ unet.enable_xformers_memory_efficient_attention()
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ unet.conv_in.requires_grad_(True)
+ vae_b2a = copy.deepcopy(vae_a2b)
+ params_gen = CycleGAN_Turbo.get_traininable_params(unet, vae_a2b, vae_b2a)
+
+ vae_enc = VAE_encode(vae_a2b, vae_b2a=vae_b2a)
+ vae_dec = VAE_decode(vae_a2b, vae_b2a=vae_b2a)
+
+ optimizer_gen = torch.optim.AdamW(params_gen, lr=args.learning_rate, betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay, eps=args.adam_epsilon,)
+
+ params_disc = list(net_disc_a.parameters()) + list(net_disc_b.parameters())
+ optimizer_disc = torch.optim.AdamW(params_disc, lr=args.learning_rate, betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay, eps=args.adam_epsilon,)
+
+ dataset_train = UnpairedDataset(dataset_folder=args.dataset_folder, image_prep=args.train_img_prep, split="train", tokenizer=tokenizer)
+ train_dataloader = torch.utils.data.DataLoader(dataset_train, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers)
+ T_val = build_transform(args.val_img_prep)
+ fixed_caption_src = dataset_train.fixed_caption_src
+ fixed_caption_tgt = dataset_train.fixed_caption_tgt
+ l_images_src_test = []
+ for ext in ["*.jpg", "*.jpeg", "*.png", "*.bmp"]:
+ l_images_src_test.extend(glob(os.path.join(args.dataset_folder, "test_A", ext)))
+ l_images_tgt_test = []
+ for ext in ["*.jpg", "*.jpeg", "*.png", "*.bmp"]:
+ l_images_tgt_test.extend(glob(os.path.join(args.dataset_folder, "test_B", ext)))
+ l_images_src_test, l_images_tgt_test = sorted(l_images_src_test), sorted(l_images_tgt_test)
+
+ # make the reference FID statistics
+ if accelerator.is_main_process:
+ feat_model = build_feature_extractor("clean", "cuda", use_dataparallel=False)
+ """
+ FID reference statistics for A -> B translation
+ """
+ output_dir_ref = os.path.join(args.output_dir, "fid_reference_a2b")
+ os.makedirs(output_dir_ref, exist_ok=True)
+ # transform all images according to the validation transform and save them
+ for _path in tqdm(l_images_tgt_test):
+ _img = T_val(Image.open(_path).convert("RGB"))
+ outf = os.path.join(output_dir_ref, os.path.basename(_path)).replace(".jpg", ".png")
+ if not os.path.exists(outf):
+ _img.save(outf)
+ # compute the features for the reference images
+ ref_features = get_folder_features(output_dir_ref, model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_fn_resize=None, description="", verbose=True,
+ custom_image_tranform=None)
+ a2b_ref_mu, a2b_ref_sigma = np.mean(ref_features, axis=0), np.cov(ref_features, rowvar=False)
+ """
+ FID reference statistics for B -> A translation
+ """
+ # transform all images according to the validation transform and save them
+ output_dir_ref = os.path.join(args.output_dir, "fid_reference_b2a")
+ os.makedirs(output_dir_ref, exist_ok=True)
+ for _path in tqdm(l_images_src_test):
+ _img = T_val(Image.open(_path).convert("RGB"))
+ outf = os.path.join(output_dir_ref, os.path.basename(_path)).replace(".jpg", ".png")
+ if not os.path.exists(outf):
+ _img.save(outf)
+ # compute the features for the reference images
+ ref_features = get_folder_features(output_dir_ref, model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_fn_resize=None, description="", verbose=True,
+ custom_image_tranform=None)
+ b2a_ref_mu, b2a_ref_sigma = np.mean(ref_features, axis=0), np.cov(ref_features, rowvar=False)
+
+ lr_scheduler_gen = get_scheduler(args.lr_scheduler, optimizer=optimizer_gen,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_cycles=args.lr_num_cycles, power=args.lr_power)
+ lr_scheduler_disc = get_scheduler(args.lr_scheduler, optimizer=optimizer_disc,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_cycles=args.lr_num_cycles, power=args.lr_power)
+
+ net_lpips = lpips.LPIPS(net='vgg')
+ net_lpips.cuda()
+ net_lpips.requires_grad_(False)
+
+ fixed_a2b_tokens = tokenizer(fixed_caption_tgt, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt").input_ids[0]
+ fixed_a2b_emb_base = text_encoder(fixed_a2b_tokens.cuda().unsqueeze(0))[0].detach()
+ fixed_b2a_tokens = tokenizer(fixed_caption_src, max_length=tokenizer.model_max_length, padding="max_length", truncation=True, return_tensors="pt").input_ids[0]
+ fixed_b2a_emb_base = text_encoder(fixed_b2a_tokens.cuda().unsqueeze(0))[0].detach()
+ del text_encoder, tokenizer # free up some memory
+
+ unet, vae_enc, vae_dec, net_disc_a, net_disc_b = accelerator.prepare(unet, vae_enc, vae_dec, net_disc_a, net_disc_b)
+ net_lpips, optimizer_gen, optimizer_disc, train_dataloader, lr_scheduler_gen, lr_scheduler_disc = accelerator.prepare(
+ net_lpips, optimizer_gen, optimizer_disc, train_dataloader, lr_scheduler_gen, lr_scheduler_disc
+ )
+ if accelerator.is_main_process:
+ accelerator.init_trackers(args.tracker_project_name, config=dict(vars(args)))
+
+ first_epoch = 0
+ global_step = 0
+ progress_bar = tqdm(range(0, args.max_train_steps), initial=global_step, desc="Steps",
+ disable=not accelerator.is_local_main_process,)
+ # turn off eff. attn for the disc
+ for name, module in net_disc_a.named_modules():
+ if "attn" in name:
+ module.fused_attn = False
+ for name, module in net_disc_b.named_modules():
+ if "attn" in name:
+ module.fused_attn = False
+
+ for epoch in range(first_epoch, args.max_train_epochs):
+ for step, batch in enumerate(train_dataloader):
+ l_acc = [unet, net_disc_a, net_disc_b, vae_enc, vae_dec]
+ with accelerator.accumulate(*l_acc):
+ img_a = batch["pixel_values_src"].to(dtype=weight_dtype)
+ img_b = batch["pixel_values_tgt"].to(dtype=weight_dtype)
+
+ bsz = img_a.shape[0]
+ fixed_a2b_emb = fixed_a2b_emb_base.repeat(bsz, 1, 1).to(dtype=weight_dtype)
+ fixed_b2a_emb = fixed_b2a_emb_base.repeat(bsz, 1, 1).to(dtype=weight_dtype)
+ timesteps = torch.tensor([noise_scheduler_1step.config.num_train_timesteps - 1] * bsz, device=img_a.device).long()
+
+ """
+ Cycle Objective
+ """
+ # A -> fake B -> rec A
+ cyc_fake_b = CycleGAN_Turbo.forward_with_networks(img_a, "a2b", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_a2b_emb)
+ cyc_rec_a = CycleGAN_Turbo.forward_with_networks(cyc_fake_b, "b2a", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_b2a_emb)
+ loss_cycle_a = crit_cycle(cyc_rec_a, img_a) * args.lambda_cycle
+ loss_cycle_a += net_lpips(cyc_rec_a, img_a).mean() * args.lambda_cycle_lpips
+ # B -> fake A -> rec B
+ cyc_fake_a = CycleGAN_Turbo.forward_with_networks(img_b, "b2a", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_b2a_emb)
+ cyc_rec_b = CycleGAN_Turbo.forward_with_networks(cyc_fake_a, "a2b", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_a2b_emb)
+ loss_cycle_b = crit_cycle(cyc_rec_b, img_b) * args.lambda_cycle
+ loss_cycle_b += net_lpips(cyc_rec_b, img_b).mean() * args.lambda_cycle_lpips
+ accelerator.backward(loss_cycle_a + loss_cycle_b, retain_graph=False)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(params_gen, args.max_grad_norm)
+
+ optimizer_gen.step()
+ lr_scheduler_gen.step()
+ optimizer_gen.zero_grad()
+
+ """
+ Generator Objective (GAN) for task a->b and b->a (fake inputs)
+ """
+ fake_a = CycleGAN_Turbo.forward_with_networks(img_b, "b2a", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_b2a_emb)
+ fake_b = CycleGAN_Turbo.forward_with_networks(img_a, "a2b", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_a2b_emb)
+ loss_gan_a = net_disc_a(fake_b, for_G=True).mean() * args.lambda_gan
+ loss_gan_b = net_disc_b(fake_a, for_G=True).mean() * args.lambda_gan
+ accelerator.backward(loss_gan_a + loss_gan_b, retain_graph=False)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(params_gen, args.max_grad_norm)
+ optimizer_gen.step()
+ lr_scheduler_gen.step()
+ optimizer_gen.zero_grad()
+ optimizer_disc.zero_grad()
+
+ """
+ Identity Objective
+ """
+ idt_a = CycleGAN_Turbo.forward_with_networks(img_b, "a2b", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_a2b_emb)
+ loss_idt_a = crit_idt(idt_a, img_b) * args.lambda_idt
+ loss_idt_a += net_lpips(idt_a, img_b).mean() * args.lambda_idt_lpips
+ idt_b = CycleGAN_Turbo.forward_with_networks(img_a, "b2a", vae_enc, unet, vae_dec, noise_scheduler_1step, timesteps, fixed_b2a_emb)
+ loss_idt_b = crit_idt(idt_b, img_a) * args.lambda_idt
+ loss_idt_b += net_lpips(idt_b, img_a).mean() * args.lambda_idt_lpips
+ loss_g_idt = loss_idt_a + loss_idt_b
+ accelerator.backward(loss_g_idt, retain_graph=False)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(params_gen, args.max_grad_norm)
+ optimizer_gen.step()
+ lr_scheduler_gen.step()
+ optimizer_gen.zero_grad()
+
+ """
+ Discriminator for task a->b and b->a (fake inputs)
+ """
+ loss_D_A_fake = net_disc_a(fake_b.detach(), for_real=False).mean() * args.lambda_gan
+ loss_D_B_fake = net_disc_b(fake_a.detach(), for_real=False).mean() * args.lambda_gan
+ loss_D_fake = (loss_D_A_fake + loss_D_B_fake) * 0.5
+ accelerator.backward(loss_D_fake, retain_graph=False)
+ if accelerator.sync_gradients:
+ params_to_clip = list(net_disc_a.parameters()) + list(net_disc_b.parameters())
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer_disc.step()
+ lr_scheduler_disc.step()
+ optimizer_disc.zero_grad()
+
+ """
+ Discriminator for task a->b and b->a (real inputs)
+ """
+ loss_D_A_real = net_disc_a(img_b, for_real=True).mean() * args.lambda_gan
+ loss_D_B_real = net_disc_b(img_a, for_real=True).mean() * args.lambda_gan
+ loss_D_real = (loss_D_A_real + loss_D_B_real) * 0.5
+ accelerator.backward(loss_D_real, retain_graph=False)
+ if accelerator.sync_gradients:
+ params_to_clip = list(net_disc_a.parameters()) + list(net_disc_b.parameters())
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer_disc.step()
+ lr_scheduler_disc.step()
+ optimizer_disc.zero_grad()
+
+ logs = {}
+ logs["cycle_a"] = loss_cycle_a.detach().item()
+ logs["cycle_b"] = loss_cycle_b.detach().item()
+ logs["gan_a"] = loss_gan_a.detach().item()
+ logs["gan_b"] = loss_gan_b.detach().item()
+ logs["disc_a"] = loss_D_A_fake.detach().item() + loss_D_A_real.detach().item()
+ logs["disc_b"] = loss_D_B_fake.detach().item() + loss_D_B_real.detach().item()
+ logs["idt_a"] = loss_idt_a.detach().item()
+ logs["idt_b"] = loss_idt_b.detach().item()
+
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if accelerator.is_main_process:
+ eval_unet = accelerator.unwrap_model(unet)
+ eval_vae_enc = accelerator.unwrap_model(vae_enc)
+ eval_vae_dec = accelerator.unwrap_model(vae_dec)
+ if global_step % args.viz_freq == 1:
+ for tracker in accelerator.trackers:
+ if tracker.name == "wandb":
+ viz_img_a = batch["pixel_values_src"].to(dtype=weight_dtype)
+ viz_img_b = batch["pixel_values_tgt"].to(dtype=weight_dtype)
+ log_dict = {
+ "train/real_a": [wandb.Image(viz_img_a[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)],
+ "train/real_b": [wandb.Image(viz_img_b[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)],
+ }
+ log_dict["train/rec_a"] = [wandb.Image(cyc_rec_a[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)]
+ log_dict["train/rec_b"] = [wandb.Image(cyc_rec_b[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)]
+ log_dict["train/fake_b"] = [wandb.Image(fake_b[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)]
+ log_dict["train/fake_a"] = [wandb.Image(fake_a[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(bsz)]
+ tracker.log(log_dict)
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ if global_step % args.checkpointing_steps == 1:
+ outf = os.path.join(args.output_dir, "checkpoints", f"model_{global_step}.pkl")
+ sd = {}
+ sd["l_target_modules_encoder"] = l_modules_unet_encoder
+ sd["l_target_modules_decoder"] = l_modules_unet_decoder
+ sd["l_modules_others"] = l_modules_unet_others
+ sd["rank_unet"] = args.lora_rank_unet
+ sd["sd_encoder"] = get_peft_model_state_dict(eval_unet, adapter_name="default_encoder")
+ sd["sd_decoder"] = get_peft_model_state_dict(eval_unet, adapter_name="default_decoder")
+ sd["sd_other"] = get_peft_model_state_dict(eval_unet, adapter_name="default_others")
+ sd["rank_vae"] = args.lora_rank_vae
+ sd["vae_lora_target_modules"] = vae_lora_target_modules
+ sd["sd_vae_enc"] = eval_vae_enc.state_dict()
+ sd["sd_vae_dec"] = eval_vae_dec.state_dict()
+ torch.save(sd, outf)
+ gc.collect()
+ torch.cuda.empty_cache()
+
+ # compute val FID and DINO-Struct scores
+ if global_step % args.validation_steps == 1:
+ _timesteps = torch.tensor([noise_scheduler_1step.config.num_train_timesteps - 1] * 1, device="cuda").long()
+ net_dino = DinoStructureLoss()
+ """
+ Evaluate "A->B"
+ """
+ fid_output_dir = os.path.join(args.output_dir, f"fid-{global_step}/samples_a2b")
+ os.makedirs(fid_output_dir, exist_ok=True)
+ l_dino_scores_a2b = []
+ # get val input images from domain a
+ for idx, input_img_path in enumerate(tqdm(l_images_src_test)):
+ if idx > args.validation_num_images and args.validation_num_images > 0:
+ break
+ outf = os.path.join(fid_output_dir, f"{idx}.png")
+ with torch.no_grad():
+ input_img = T_val(Image.open(input_img_path).convert("RGB"))
+ img_a = transforms.ToTensor()(input_img)
+ img_a = transforms.Normalize([0.5], [0.5])(img_a).unsqueeze(0).cuda()
+ eval_fake_b = CycleGAN_Turbo.forward_with_networks(img_a, "a2b", eval_vae_enc, eval_unet,
+ eval_vae_dec, noise_scheduler_1step, _timesteps, fixed_a2b_emb[0:1])
+ eval_fake_b_pil = transforms.ToPILImage()(eval_fake_b[0] * 0.5 + 0.5)
+ eval_fake_b_pil.save(outf)
+ a = net_dino.preprocess(input_img).unsqueeze(0).cuda()
+ b = net_dino.preprocess(eval_fake_b_pil).unsqueeze(0).cuda()
+ dino_ssim = net_dino.calculate_global_ssim_loss(a, b).item()
+ l_dino_scores_a2b.append(dino_ssim)
+ dino_score_a2b = np.mean(l_dino_scores_a2b)
+ gen_features = get_folder_features(fid_output_dir, model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_fn_resize=None, description="", verbose=True,
+ custom_image_tranform=None)
+ ed_mu, ed_sigma = np.mean(gen_features, axis=0), np.cov(gen_features, rowvar=False)
+ score_fid_a2b = frechet_distance(a2b_ref_mu, a2b_ref_sigma, ed_mu, ed_sigma)
+ print(f"step={global_step}, fid(a2b)={score_fid_a2b:.2f}, dino(a2b)={dino_score_a2b:.3f}")
+
+ """
+ compute FID for "B->A"
+ """
+ fid_output_dir = os.path.join(args.output_dir, f"fid-{global_step}/samples_b2a")
+ os.makedirs(fid_output_dir, exist_ok=True)
+ l_dino_scores_b2a = []
+ # get val input images from domain b
+ for idx, input_img_path in enumerate(tqdm(l_images_tgt_test)):
+ if idx > args.validation_num_images and args.validation_num_images > 0:
+ break
+ outf = os.path.join(fid_output_dir, f"{idx}.png")
+ with torch.no_grad():
+ input_img = T_val(Image.open(input_img_path).convert("RGB"))
+ img_b = transforms.ToTensor()(input_img)
+ img_b = transforms.Normalize([0.5], [0.5])(img_b).unsqueeze(0).cuda()
+ eval_fake_a = CycleGAN_Turbo.forward_with_networks(img_b, "b2a", eval_vae_enc, eval_unet,
+ eval_vae_dec, noise_scheduler_1step, _timesteps, fixed_b2a_emb[0:1])
+ eval_fake_a_pil = transforms.ToPILImage()(eval_fake_a[0] * 0.5 + 0.5)
+ eval_fake_a_pil.save(outf)
+ a = net_dino.preprocess(input_img).unsqueeze(0).cuda()
+ b = net_dino.preprocess(eval_fake_a_pil).unsqueeze(0).cuda()
+ dino_ssim = net_dino.calculate_global_ssim_loss(a, b).item()
+ l_dino_scores_b2a.append(dino_ssim)
+ dino_score_b2a = np.mean(l_dino_scores_b2a)
+ gen_features = get_folder_features(fid_output_dir, model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_fn_resize=None, description="", verbose=True,
+ custom_image_tranform=None)
+ ed_mu, ed_sigma = np.mean(gen_features, axis=0), np.cov(gen_features, rowvar=False)
+ score_fid_b2a = frechet_distance(b2a_ref_mu, b2a_ref_sigma, ed_mu, ed_sigma)
+ print(f"step={global_step}, fid(b2a)={score_fid_b2a}, dino(b2a)={dino_score_b2a:.3f}")
+ logs["val/fid_a2b"], logs["val/fid_b2a"] = score_fid_a2b, score_fid_b2a
+ logs["val/dino_struct_a2b"], logs["val/dino_struct_b2a"] = dino_score_a2b, dino_score_b2a
+ del net_dino # free up memory
+
+ progress_bar.set_postfix(**logs)
+ accelerator.log(logs, step=global_step)
+ if global_step >= args.max_train_steps:
+ break
+
+
+if __name__ == "__main__":
+ args = parse_args_unpaired_training()
+ main(args)
diff --git a/src/train_pix2pix_turbo.py b/src/train_pix2pix_turbo.py
new file mode 100644
index 0000000000000000000000000000000000000000..2dca15246d1c7104b485d2490be9d6a669927bd6
--- /dev/null
+++ b/src/train_pix2pix_turbo.py
@@ -0,0 +1,307 @@
+import os
+import gc
+import lpips
+import clip
+import numpy as np
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+import transformers
+from accelerate import Accelerator
+from accelerate.utils import set_seed
+from PIL import Image
+from torchvision import transforms
+from tqdm.auto import tqdm
+
+import diffusers
+from diffusers.utils.import_utils import is_xformers_available
+from diffusers.optimization import get_scheduler
+
+import wandb
+from cleanfid.fid import get_folder_features, build_feature_extractor, fid_from_feats
+
+from pix2pix_turbo import Pix2Pix_Turbo
+from my_utils.training_utils import parse_args_paired_training, PairedDataset
+
+
+def main(args):
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with=args.report_to,
+ )
+
+ if accelerator.is_local_main_process:
+ transformers.utils.logging.set_verbosity_warning()
+ diffusers.utils.logging.set_verbosity_info()
+ else:
+ transformers.utils.logging.set_verbosity_error()
+ diffusers.utils.logging.set_verbosity_error()
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if accelerator.is_main_process:
+ os.makedirs(os.path.join(args.output_dir, "checkpoints"), exist_ok=True)
+ os.makedirs(os.path.join(args.output_dir, "eval"), exist_ok=True)
+
+ if args.pretrained_model_name_or_path == "stabilityai/sd-turbo":
+ net_pix2pix = Pix2Pix_Turbo(lora_rank_unet=args.lora_rank_unet, lora_rank_vae=args.lora_rank_vae)
+ net_pix2pix.set_train()
+
+ if args.enable_xformers_memory_efficient_attention:
+ if is_xformers_available():
+ net_pix2pix.unet.enable_xformers_memory_efficient_attention()
+ else:
+ raise ValueError("xformers is not available, please install it by running `pip install xformers`")
+
+ if args.gradient_checkpointing:
+ net_pix2pix.unet.enable_gradient_checkpointing()
+
+ if args.allow_tf32:
+ torch.backends.cuda.matmul.allow_tf32 = True
+
+ if args.gan_disc_type == "vagan_clip":
+ import vision_aided_loss
+ net_disc = vision_aided_loss.Discriminator(cv_type='clip', loss_type=args.gan_loss_type, device="cuda")
+ else:
+ raise NotImplementedError(f"Discriminator type {args.gan_disc_type} not implemented")
+
+ net_disc = net_disc.cuda()
+ net_disc.requires_grad_(True)
+ net_disc.cv_ensemble.requires_grad_(False)
+ net_disc.train()
+
+ net_lpips = lpips.LPIPS(net='vgg').cuda()
+ net_clip, _ = clip.load("ViT-B/32", device="cuda")
+ net_clip.requires_grad_(False)
+ net_clip.eval()
+
+ net_lpips.requires_grad_(False)
+
+ # make the optimizer
+ layers_to_opt = []
+ for n, _p in net_pix2pix.unet.named_parameters():
+ if "lora" in n:
+ assert _p.requires_grad
+ layers_to_opt.append(_p)
+ layers_to_opt += list(net_pix2pix.unet.conv_in.parameters())
+ for n, _p in net_pix2pix.vae.named_parameters():
+ if "lora" in n and "vae_skip" in n:
+ assert _p.requires_grad
+ layers_to_opt.append(_p)
+ layers_to_opt = layers_to_opt + list(net_pix2pix.vae.decoder.skip_conv_1.parameters()) + \
+ list(net_pix2pix.vae.decoder.skip_conv_2.parameters()) + \
+ list(net_pix2pix.vae.decoder.skip_conv_3.parameters()) + \
+ list(net_pix2pix.vae.decoder.skip_conv_4.parameters())
+
+ optimizer = torch.optim.AdamW(layers_to_opt, lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2), weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,)
+ lr_scheduler = get_scheduler(args.lr_scheduler, optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_cycles=args.lr_num_cycles, power=args.lr_power,)
+
+ optimizer_disc = torch.optim.AdamW(net_disc.parameters(), lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2), weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,)
+ lr_scheduler_disc = get_scheduler(args.lr_scheduler, optimizer=optimizer_disc,
+ num_warmup_steps=args.lr_warmup_steps * accelerator.num_processes,
+ num_training_steps=args.max_train_steps * accelerator.num_processes,
+ num_cycles=args.lr_num_cycles, power=args.lr_power)
+
+ dataset_train = PairedDataset(dataset_folder=args.dataset_folder, image_prep=args.train_image_prep, split="train", tokenizer=net_pix2pix.tokenizer)
+ dl_train = torch.utils.data.DataLoader(dataset_train, batch_size=args.train_batch_size, shuffle=True, num_workers=args.dataloader_num_workers)
+ dataset_val = PairedDataset(dataset_folder=args.dataset_folder, image_prep=args.test_image_prep, split="test", tokenizer=net_pix2pix.tokenizer)
+ dl_val = torch.utils.data.DataLoader(dataset_val, batch_size=1, shuffle=False, num_workers=0)
+
+ # Prepare everything with our `accelerator`.
+ net_pix2pix, net_disc, optimizer, optimizer_disc, dl_train, lr_scheduler, lr_scheduler_disc = accelerator.prepare(
+ net_pix2pix, net_disc, optimizer, optimizer_disc, dl_train, lr_scheduler, lr_scheduler_disc
+ )
+ net_clip, net_lpips = accelerator.prepare(net_clip, net_lpips)
+ # renorm with image net statistics
+ t_clip_renorm = transforms.Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
+ weight_dtype = torch.float32
+ if accelerator.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif accelerator.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move al networksr to device and cast to weight_dtype
+ net_pix2pix.to(accelerator.device, dtype=weight_dtype)
+ net_disc.to(accelerator.device, dtype=weight_dtype)
+ net_lpips.to(accelerator.device, dtype=weight_dtype)
+ net_clip.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ tracker_config = dict(vars(args))
+ accelerator.init_trackers(args.tracker_project_name, config=tracker_config)
+
+ progress_bar = tqdm(range(0, args.max_train_steps), initial=0, desc="Steps",
+ disable=not accelerator.is_local_main_process,)
+
+ # turn off eff. attn for the discriminator
+ for name, module in net_disc.named_modules():
+ if "attn" in name:
+ module.fused_attn = False
+
+ # compute the reference stats for FID tracking
+ if accelerator.is_main_process and args.track_val_fid:
+ feat_model = build_feature_extractor("clean", "cuda", use_dataparallel=False)
+
+ def fn_transform(x):
+ x_pil = Image.fromarray(x)
+ out_pil = transforms.Resize(args.resolution, interpolation=transforms.InterpolationMode.LANCZOS)(x_pil)
+ return np.array(out_pil)
+
+ ref_stats = get_folder_features(os.path.join(args.dataset_folder, "test_B"), model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_image_tranform=fn_transform, description="", verbose=True)
+
+ # start the training loop
+ global_step = 0
+ for epoch in range(0, args.num_training_epochs):
+ for step, batch in enumerate(dl_train):
+ l_acc = [net_pix2pix, net_disc]
+ with accelerator.accumulate(*l_acc):
+ x_src = batch["conditioning_pixel_values"]
+ x_tgt = batch["output_pixel_values"]
+ B, C, H, W = x_src.shape
+ # forward pass
+ x_tgt_pred = net_pix2pix(x_src, prompt_tokens=batch["input_ids"], deterministic=True)
+ # Reconstruction loss
+ loss_l2 = F.mse_loss(x_tgt_pred.float(), x_tgt.float(), reduction="mean") * args.lambda_l2
+ loss_lpips = net_lpips(x_tgt_pred.float(), x_tgt.float()).mean() * args.lambda_lpips
+ loss = loss_l2 + loss_lpips
+ # CLIP similarity loss
+ if args.lambda_clipsim > 0:
+ x_tgt_pred_renorm = t_clip_renorm(x_tgt_pred * 0.5 + 0.5)
+ x_tgt_pred_renorm = F.interpolate(x_tgt_pred_renorm, (224, 224), mode="bilinear", align_corners=False)
+ caption_tokens = clip.tokenize(batch["caption"], truncate=True).to(x_tgt_pred.device)
+ clipsim, _ = net_clip(x_tgt_pred_renorm, caption_tokens)
+ loss_clipsim = (1 - clipsim.mean() / 100)
+ loss += loss_clipsim * args.lambda_clipsim
+ accelerator.backward(loss, retain_graph=False)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(layers_to_opt, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad(set_to_none=args.set_grads_to_none)
+
+ """
+ Generator loss: fool the discriminator
+ """
+ x_tgt_pred = net_pix2pix(x_src, prompt_tokens=batch["input_ids"], deterministic=True)
+ lossG = net_disc(x_tgt_pred, for_G=True).mean() * args.lambda_gan
+ accelerator.backward(lossG)
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(layers_to_opt, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad(set_to_none=args.set_grads_to_none)
+
+ """
+ Discriminator loss: fake image vs real image
+ """
+ # real image
+ lossD_real = net_disc(x_tgt.detach(), for_real=True).mean() * args.lambda_gan
+ accelerator.backward(lossD_real.mean())
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(net_disc.parameters(), args.max_grad_norm)
+ optimizer_disc.step()
+ lr_scheduler_disc.step()
+ optimizer_disc.zero_grad(set_to_none=args.set_grads_to_none)
+ # fake image
+ lossD_fake = net_disc(x_tgt_pred.detach(), for_real=False).mean() * args.lambda_gan
+ accelerator.backward(lossD_fake.mean())
+ if accelerator.sync_gradients:
+ accelerator.clip_grad_norm_(net_disc.parameters(), args.max_grad_norm)
+ optimizer_disc.step()
+ optimizer_disc.zero_grad(set_to_none=args.set_grads_to_none)
+ lossD = lossD_real + lossD_fake
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ if accelerator.is_main_process:
+ logs = {}
+ # log all the losses
+ logs["lossG"] = lossG.detach().item()
+ logs["lossD"] = lossD.detach().item()
+ logs["loss_l2"] = loss_l2.detach().item()
+ logs["loss_lpips"] = loss_lpips.detach().item()
+ if args.lambda_clipsim > 0:
+ logs["loss_clipsim"] = loss_clipsim.detach().item()
+ progress_bar.set_postfix(**logs)
+
+ # viz some images
+ if global_step % args.viz_freq == 1:
+ log_dict = {
+ "train/source": [wandb.Image(x_src[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(B)],
+ "train/target": [wandb.Image(x_tgt[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(B)],
+ "train/model_output": [wandb.Image(x_tgt_pred[idx].float().detach().cpu(), caption=f"idx={idx}") for idx in range(B)],
+ }
+ for k in log_dict:
+ logs[k] = log_dict[k]
+
+ # checkpoint the model
+ if global_step % args.checkpointing_steps == 1:
+ outf = os.path.join(args.output_dir, "checkpoints", f"model_{global_step}.pkl")
+ accelerator.unwrap_model(net_pix2pix).save_model(outf)
+
+ # compute validation set FID, L2, LPIPS, CLIP-SIM
+ if global_step % args.eval_freq == 1:
+ l_l2, l_lpips, l_clipsim = [], [], []
+ if args.track_val_fid:
+ os.makedirs(os.path.join(args.output_dir, "eval", f"fid_{global_step}"), exist_ok=True)
+ for step, batch_val in enumerate(dl_val):
+ if step >= args.num_samples_eval:
+ break
+ x_src = batch_val["conditioning_pixel_values"].cuda()
+ x_tgt = batch_val["output_pixel_values"].cuda()
+ B, C, H, W = x_src.shape
+ assert B == 1, "Use batch size 1 for eval."
+ with torch.no_grad():
+ # forward pass
+ x_tgt_pred = accelerator.unwrap_model(net_pix2pix)(x_src, prompt_tokens=batch_val["input_ids"].cuda(), deterministic=True)
+ # compute the reconstruction losses
+ loss_l2 = F.mse_loss(x_tgt_pred.float(), x_tgt.float(), reduction="mean")
+ loss_lpips = net_lpips(x_tgt_pred.float(), x_tgt.float()).mean()
+ # compute clip similarity loss
+ x_tgt_pred_renorm = t_clip_renorm(x_tgt_pred * 0.5 + 0.5)
+ x_tgt_pred_renorm = F.interpolate(x_tgt_pred_renorm, (224, 224), mode="bilinear", align_corners=False)
+ caption_tokens = clip.tokenize(batch_val["caption"], truncate=True).to(x_tgt_pred.device)
+ clipsim, _ = net_clip(x_tgt_pred_renorm, caption_tokens)
+ clipsim = clipsim.mean()
+
+ l_l2.append(loss_l2.item())
+ l_lpips.append(loss_lpips.item())
+ l_clipsim.append(clipsim.item())
+ # save output images to file for FID evaluation
+ if args.track_val_fid:
+ output_pil = transforms.ToPILImage()(x_tgt_pred[0].cpu() * 0.5 + 0.5)
+ outf = os.path.join(args.output_dir, "eval", f"fid_{global_step}", f"val_{step}.png")
+ output_pil.save(outf)
+ if args.track_val_fid:
+ curr_stats = get_folder_features(os.path.join(args.output_dir, "eval", f"fid_{global_step}"), model=feat_model, num_workers=0, num=None,
+ shuffle=False, seed=0, batch_size=8, device=torch.device("cuda"),
+ mode="clean", custom_image_tranform=fn_transform, description="", verbose=True)
+ fid_score = fid_from_feats(ref_stats, curr_stats)
+ logs["val/clean_fid"] = fid_score
+ logs["val/l2"] = np.mean(l_l2)
+ logs["val/lpips"] = np.mean(l_lpips)
+ logs["val/clipsim"] = np.mean(l_clipsim)
+ gc.collect()
+ torch.cuda.empty_cache()
+ accelerator.log(logs, step=global_step)
+
+
+if __name__ == "__main__":
+ args = parse_args_paired_training()
+ main(args)
diff --git a/style.css b/style.css
new file mode 100644
index 0000000000000000000000000000000000000000..3581a0b4a6767bb3ef401db3ee460b84ae5c6a7d
--- /dev/null
+++ b/style.css
@@ -0,0 +1,213 @@
+@import url('https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.1/css/all.min.css');
+
+/* the outermost contrained of the app */
+.main{
+ display: flex;
+ justify-content: center;
+ align-items: center;
+ width: 1200px;
+}
+
+/* #main_row{
+
+} */
+
+/* hide this class */
+.svelte-p4aq0j {
+ display: none;
+}
+
+.wrap.svelte-p4aq0j.svelte-p4aq0j {
+ display: none;
+}
+
+#download_sketch{
+ display: none;
+}
+
+#download_output{
+ display: none;
+}
+
+#column_input, #column_output{
+ width: 500px;
+ display: flex;
+ /* justify-content: center; */
+ align-items: center;
+}
+
+#tools_header, #input_header, #output_header, #process_header {
+ display: flex;
+ justify-content: center;
+ align-items: center;
+ width: 400px;
+}
+
+
+#nn{
+ width: 100px;
+ height: 100px;
+}
+
+
+#column_process{
+ display: flex;
+ justify-content: center; /* Center horizontally */
+ align-items: center; /* Center vertically */
+ height: 600px;
+}
+
+/* this is the "pix2pix-turbo" above the process button */
+#description > span{
+ display: flex;
+ justify-content: center; /* Center horizontally */
+ align-items: center; /* Center vertically */
+}
+
+/* this is the "UNDO_BUTTON, X_BUTTON" */
+div.svelte-1030q2h{
+ width: 30px;
+ height: 30px;
+ display: none;
+}
+
+
+#component-5 > div{
+ border: 0px;
+ box-shadow: none;
+}
+
+#cb-eraser, #cb-line{
+ display: none;
+}
+
+/* eraser text */
+#cb-eraser > label > span{
+ display: none;
+}
+#cb-line > label > span{
+ display: none;
+}
+
+
+.button-row {
+ display: flex;
+ justify-content: center;
+ align-items: center;
+ height: 50px;
+ border: 0px;
+}
+
+#my-toggle-pencil{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/pencil.svg");
+ background-color: white;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+}
+
+#my-toggle-pencil.clicked{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/pencil-fill.svg");
+ transform: scale(0.98);
+ background-color: gray;
+ background-size: cover;
+ /* background-size: 95%;
+ background-position: center; */
+ /* border: 2px solid #000; */
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+}
+
+
+#my-toggle-eraser{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/eraser.svg");
+ background-color: white;
+ background-color: white;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+}
+
+#my-toggle-eraser.clicked{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/eraser-fill.svg");
+ transform: scale(0.98);
+ background-color: gray;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+}
+
+
+
+#my-button-undo{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/arrow-counterclockwise.svg");
+ background-color: white;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+}
+
+#my-button-clear{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/x-lg.svg");
+ background-color: white;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+
+}
+
+
+#my-button-down{
+ background-image: url("https://icons.getbootstrap.com/assets/icons/arrow-down.svg");
+ background-color: white;
+ background-size: cover;
+ margin: 0px;
+ box-shadow: none;
+ width: 40px;
+ height: 40px;
+
+}
+
+.pad2{
+ padding: 2px;
+ background-color: white;
+ border: 2px solid #000;
+ margin: 10px;
+ display: flex;
+ justify-content: center; /* Center horizontally */
+ align-items: center; /* Center vertically */
+}
+
+
+
+
+#output_image, #input_image{
+ border-radius: 0px;
+ border: 5px solid #000;
+ border-width: none;
+}
+
+
+#output_image > img{
+ border: 5px solid #000;
+ border-radius: 0px;
+ border-width: none;
+}
+
+#input_image > div.image-container.svelte-p3y7hu > div.wrap.svelte-yigbas > canvas:nth-child(1){
+ border: 5px solid #000;
+ border-radius: 0px;
+ border-width: none;
+}
\ No newline at end of file