
tangchangli
commited on
Commit
•
7cf7820
1
Parent(s):
3415c92
chore: init repo
Browse files- .gitattributes +1 -0
- .gitignore +163 -0
- LICENSE +201 -0
- README.md +77 -0
- beats/BEATs.py +180 -0
- beats/LICENSE_beats +21 -0
- beats/Tokenizers.py +172 -0
- beats/__init__.py +0 -0
- beats/backbone.py +783 -0
- beats/modules.py +218 -0
- beats/quantizer.py +215 -0
- cli_inference.py +53 -0
- model.py +251 -0
- other_third-party_licenses/LICENSE_vicuna +201 -0
- other_third-party_licenses/LICENSE_whisper +21 -0
- qformer/LICENSE_Lavis +14 -0
- qformer/LICENSE_MiniGPT4 +14 -0
- qformer/LICENSE_VideoLlama +28 -0
- qformer/Qformer.py +1217 -0
- requirements.txt +10 -0
- resource/audio_demo/duck.wav +0 -0
- resource/audio_demo/excitement.wav +0 -0
- resource/audio_demo/gunshots.wav +0 -0
- resource/audio_demo/mountain.wav +0 -0
- resource/audio_demo/music.wav +0 -0
- resource/response_demo/aac.png +0 -0
- resource/response_demo/aed.png +0 -0
- resource/response_demo/asr.png +0 -0
- resource/response_demo/emo.png +0 -0
- resource/response_demo/jsac.png +0 -0
- resource/response_demo/lyrics.png +0 -0
- resource/response_demo/mc.png +0 -0
- resource/response_demo/memo.png +0 -0
- resource/response_demo/pr.png +0 -0
- resource/response_demo/sac.png +0 -0
- resource/response_demo/sq.png +0 -0
- resource/response_demo/sr.png +0 -0
- resource/response_demo/story.png +0 -0
- resource/response_demo/title.png +0 -0
- resource/salmon.png +3 -0
- resource/structure.png +0 -0
- salmonn_7b_v0.pth +3 -0
- web_demo.py +166 -0
.gitattributes
CHANGED
|
@@ -33,3 +33,4 @@ saved_model/**/* filter=lfs diff=lfs merge=lfs -text
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
|
|
|
|
|
| 33 |
*.zip filter=lfs diff=lfs merge=lfs -text
|
| 34 |
*.zst filter=lfs diff=lfs merge=lfs -text
|
| 35 |
*tfevents* filter=lfs diff=lfs merge=lfs -text
|
| 36 |
+
resource/salmon.png filter=lfs diff=lfs merge=lfs -text
|
.gitignore
ADDED
|
@@ -0,0 +1,163 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Byte-compiled / optimized / DLL files
|
| 2 |
+
__pycache__/
|
| 3 |
+
*.py[cod]
|
| 4 |
+
*$py.class
|
| 5 |
+
|
| 6 |
+
# C extensions
|
| 7 |
+
*.so
|
| 8 |
+
|
| 9 |
+
# Distribution / packaging
|
| 10 |
+
.Python
|
| 11 |
+
build/
|
| 12 |
+
develop-eggs/
|
| 13 |
+
dist/
|
| 14 |
+
downloads/
|
| 15 |
+
eggs/
|
| 16 |
+
.eggs/
|
| 17 |
+
lib/
|
| 18 |
+
lib64/
|
| 19 |
+
parts/
|
| 20 |
+
sdist/
|
| 21 |
+
var/
|
| 22 |
+
wheels/
|
| 23 |
+
share/python-wheels/
|
| 24 |
+
*.egg-info/
|
| 25 |
+
.installed.cfg
|
| 26 |
+
*.egg
|
| 27 |
+
MANIFEST
|
| 28 |
+
|
| 29 |
+
# PyInstaller
|
| 30 |
+
# Usually these files are written by a python script from a template
|
| 31 |
+
# before PyInstaller builds the exe, so as to inject date/other infos into it.
|
| 32 |
+
*.manifest
|
| 33 |
+
*.spec
|
| 34 |
+
|
| 35 |
+
# Installer logs
|
| 36 |
+
pip-log.txt
|
| 37 |
+
pip-delete-this-directory.txt
|
| 38 |
+
|
| 39 |
+
# Unit test / coverage reports
|
| 40 |
+
htmlcov/
|
| 41 |
+
.tox/
|
| 42 |
+
.nox/
|
| 43 |
+
.coverage
|
| 44 |
+
.coverage.*
|
| 45 |
+
.cache
|
| 46 |
+
nosetests.xml
|
| 47 |
+
coverage.xml
|
| 48 |
+
*.cover
|
| 49 |
+
*.py,cover
|
| 50 |
+
.hypothesis/
|
| 51 |
+
.pytest_cache/
|
| 52 |
+
cover/
|
| 53 |
+
|
| 54 |
+
# Translations
|
| 55 |
+
*.mo
|
| 56 |
+
*.pot
|
| 57 |
+
|
| 58 |
+
# Django stuff:
|
| 59 |
+
*.log
|
| 60 |
+
local_settings.py
|
| 61 |
+
db.sqlite3
|
| 62 |
+
db.sqlite3-journal
|
| 63 |
+
|
| 64 |
+
# Flask stuff:
|
| 65 |
+
instance/
|
| 66 |
+
.webassets-cache
|
| 67 |
+
|
| 68 |
+
# Scrapy stuff:
|
| 69 |
+
.scrapy
|
| 70 |
+
|
| 71 |
+
# Sphinx documentation
|
| 72 |
+
docs/_build/
|
| 73 |
+
|
| 74 |
+
# PyBuilder
|
| 75 |
+
.pybuilder/
|
| 76 |
+
target/
|
| 77 |
+
|
| 78 |
+
# Jupyter Notebook
|
| 79 |
+
.ipynb_checkpoints
|
| 80 |
+
|
| 81 |
+
# IPython
|
| 82 |
+
profile_default/
|
| 83 |
+
ipython_config.py
|
| 84 |
+
|
| 85 |
+
# pyenv
|
| 86 |
+
# For a library or package, you might want to ignore these files since the code is
|
| 87 |
+
# intended to run in multiple environments; otherwise, check them in:
|
| 88 |
+
# .python-version
|
| 89 |
+
|
| 90 |
+
# pipenv
|
| 91 |
+
# According to pypa/pipenv#598, it is recommended to include Pipfile.lock in version control.
|
| 92 |
+
# However, in case of collaboration, if having platform-specific dependencies or dependencies
|
| 93 |
+
# having no cross-platform support, pipenv may install dependencies that don't work, or not
|
| 94 |
+
# install all needed dependencies.
|
| 95 |
+
#Pipfile.lock
|
| 96 |
+
|
| 97 |
+
# poetry
|
| 98 |
+
# Similar to Pipfile.lock, it is generally recommended to include poetry.lock in version control.
|
| 99 |
+
# This is especially recommended for binary packages to ensure reproducibility, and is more
|
| 100 |
+
# commonly ignored for libraries.
|
| 101 |
+
# https://python-poetry.org/docs/basic-usage/#commit-your-poetrylock-file-to-version-control
|
| 102 |
+
#poetry.lock
|
| 103 |
+
|
| 104 |
+
# pdm
|
| 105 |
+
# Similar to Pipfile.lock, it is generally recommended to include pdm.lock in version control.
|
| 106 |
+
#pdm.lock
|
| 107 |
+
# pdm stores project-wide configurations in .pdm.toml, but it is recommended to not include it
|
| 108 |
+
# in version control.
|
| 109 |
+
# https://pdm.fming.dev/#use-with-ide
|
| 110 |
+
.pdm.toml
|
| 111 |
+
|
| 112 |
+
# PEP 582; used by e.g. github.com/David-OConnor/pyflow and github.com/pdm-project/pdm
|
| 113 |
+
__pypackages__/
|
| 114 |
+
|
| 115 |
+
# Celery stuff
|
| 116 |
+
celerybeat-schedule
|
| 117 |
+
celerybeat.pid
|
| 118 |
+
|
| 119 |
+
# SageMath parsed files
|
| 120 |
+
*.sage.py
|
| 121 |
+
|
| 122 |
+
# Environments
|
| 123 |
+
.env
|
| 124 |
+
.venv
|
| 125 |
+
env/
|
| 126 |
+
venv/
|
| 127 |
+
ENV/
|
| 128 |
+
env.bak/
|
| 129 |
+
venv.bak/
|
| 130 |
+
|
| 131 |
+
# Spyder project settings
|
| 132 |
+
.spyderproject
|
| 133 |
+
.spyproject
|
| 134 |
+
|
| 135 |
+
# Rope project settings
|
| 136 |
+
.ropeproject
|
| 137 |
+
|
| 138 |
+
# mkdocs documentation
|
| 139 |
+
/site
|
| 140 |
+
|
| 141 |
+
# mypy
|
| 142 |
+
.mypy_cache/
|
| 143 |
+
.dmypy.json
|
| 144 |
+
dmypy.json
|
| 145 |
+
|
| 146 |
+
# Pyre type checker
|
| 147 |
+
.pyre/
|
| 148 |
+
|
| 149 |
+
# pytype static type analyzer
|
| 150 |
+
.pytype/
|
| 151 |
+
|
| 152 |
+
# Cython debug symbols
|
| 153 |
+
cython_debug/
|
| 154 |
+
|
| 155 |
+
# PyCharm
|
| 156 |
+
# JetBrains specific template is maintained in a separate JetBrains.gitignore that can
|
| 157 |
+
# be found at https://github.com/github/gitignore/blob/main/Global/JetBrains.gitignore
|
| 158 |
+
# and can be added to the global gitignore or merged into this file. For a more nuclear
|
| 159 |
+
# option (not recommended) you can uncomment the following to ignore the entire idea folder.
|
| 160 |
+
#.idea/
|
| 161 |
+
|
| 162 |
+
**/.DS_Store
|
| 163 |
+
launch.sh
|
LICENSE
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright Changli Tang
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
README.md
CHANGED
|
@@ -1,3 +1,80 @@
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
|
|
|
|
|
|
|
|
|
|
|
|
| 3 |
---
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
---
|
| 2 |
license: apache-2.0
|
| 3 |
+
tags:
|
| 4 |
+
- audio
|
| 5 |
+
- speech
|
| 6 |
+
- music
|
| 7 |
---
|
| 8 |
+
|
| 9 |
+
# SALMONN: Speech Audio Language Music Open Neural Network
|
| 10 |
+
|
| 11 |
+
<div align=center><img src="resource/salmon.png" height="256px" width="256px"/></div>
|
| 12 |
+
|
| 13 |
+
🚀🚀 Welcome to the repo of **SALMONN**!
|
| 14 |
+
|
| 15 |
+
SALMONN is a large language model (LLM) enabling **speech, audio events, and music inputs**, which is developed by the Department of Electronic Engineering at Tsinghua University and ByteDance. Instead of speech-only input or audio-event-only input, SALMONN can perceive and understand all kinds of audio inputs and therefore obtain emerging capabilities such as multilingual speech recognition & translation and audio-speech co-reasoning. This can be regarded as giving the LLM "ears" and cognitive hearing abilities, which makes SALMONN a step towards hearing-enabled artificial general intelligence.
|
| 16 |
+
|
| 17 |
+
<div style='display:flex; gap: 0.25rem; '>
|
| 18 |
+
<a href='https://bytedance.github.io/SALMONN/'><img src='https://img.shields.io/badge/SALMONN_13B-Demo-blue'></a>
|
| 19 |
+
<a href='https://huggingface.co/spaces/tsinghua-ee/SALMONN-7B-gradio'><img src='https://img.shields.io/badge/SALMONN_7B-Demo-orange'></a>
|
| 20 |
+
<a href='https://arxiv.org/pdf/2310.13289.pdf'><img src='https://img.shields.io/badge/paper-PDF-green'></a>
|
| 21 |
+
<a href='https://huggingface.co/tsinghua-ee/SALMONN'><img src='https://img.shields.io/badge/huggingface-checkpoint-yellow'></a>
|
| 22 |
+
</div>
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
## News
|
| 26 |
+
|
| 27 |
+
- [10-08] ✨ We have released [**the model checkpoint**](https://huggingface.co/tsinghua-ee/SALMONN) and **the inference code** for SALMONN-13B!
|
| 28 |
+
- [11-13] 🎁 We have released a **7B version of SALMONN** at [tsinghua-ee/SALMONN-7B](https://huggingface.co/tsinghua-ee/SALMONN-7B) and built the 7B demo [here](https://huggingface.co/spaces/tsinghua-ee/SALMONN-7B-gradio)!
|
| 29 |
+
|
| 30 |
+
## Structure
|
| 31 |
+
|
| 32 |
+
The model architecture of SALMONN is shown below. A window-level Q-Former is used as the connection module to fuse the outputs from a Whisper speech encoder and a BEATs audio encoder as augmented audio tokens, which are aligned with the LLM input space. The LoRA adaptor aligns the augmented LLM input space with its output space. The text prompt is used to instruct SALMONN to answer open-ended questions about the general audio inputs and the answers are in the LLM text responses.
|
| 33 |
+
|
| 34 |
+
<div align=center><img src="resource/structure.png" height="100%" width="75%"/></div>
|
| 35 |
+
|
| 36 |
+
## Demos
|
| 37 |
+
|
| 38 |
+
Compared with traditional speech and audio processing tasks such as speech recognition and audio caption, SALMONN leverages the general knowledge and cognitive abilities of the LLM to achieve a cognitively oriented audio perception, which dramatically improves the versatility of the model and the richness of the task. In addition, SALMONN is able to follow textual commands, and even spoken commands, with a relatively high degree of accuracy. Since SALMONN only uses training data based on textual commands, listening to spoken commands is also a cross-modal emergent ability.
|
| 39 |
+
|
| 40 |
+
Here are some examples of SALMONN.
|
| 41 |
+
|
| 42 |
+
| Audio | Response |
|
| 43 |
+
| ------------------------------------------------------ | -------------------------------------------- |
|
| 44 |
+
| [gunshots.wav](./resource/audio_demo/gunshots.wav) |  |
|
| 45 |
+
| [duck.wav](./resource/audio_demo/duck.wav) |  |
|
| 46 |
+
| [music.wav](./resource/audio_demo/music.wav) |  |
|
| 47 |
+
|
| 48 |
+
|
| 49 |
+
## How to inference in CLI
|
| 50 |
+
|
| 51 |
+
For SALMONN-7B v0, you need to use the following dependencies:
|
| 52 |
+
|
| 53 |
+
1. Our environment: The python version is 3.9.17, and other required packages can be installed with the following command: ```pip install -r requirements.txt```.
|
| 54 |
+
2. Download [whisper large v2](https://huggingface.co/openai/whisper-large-v2/tree/main) to ```whisper_path```.
|
| 55 |
+
3. Download [Fine-tuned BEATs_iter3+ (AS2M) (cpt2)](https://valle.blob.core.windows.net/share/BEATs/BEATs_iter3_plus_AS2M_finetuned_on_AS2M_cpt2.pt?sv=2020-08-04&st=2023-03-01T07%3A51%3A05Z&se=2033-03-02T07%3A51%3A00Z&sr=c&sp=rl&sig=QJXmSJG9DbMKf48UDIU1MfzIro8HQOf3sqlNXiflY1I%3D) to `beats_path`.
|
| 56 |
+
4. Download [vicuna 7B v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5/tree/main) to ```vicuna_path```.
|
| 57 |
+
5. Download [salmonn-7b v0](https://huggingface.co/tsinghua-ee/SALMONN-7B/blob/main/salmonn_7b_v0.pth) to ```ckpt_path```.
|
| 58 |
+
6. Running with ```python3 cli_inference.py --ckpt_path xxx --whisper_path xxx --beats_path xxx --vicuna_path xxx``` to start cli inference. Please make sure your GPU has more than 40G of memory. If your GPU does not have enough memory (e.g. only 24G), you can quantize the model using the `--low_resource` parameter to reduce the memory usage, and can reduce the LoRA scaling factor to maintain the model's emergent abilities, e.g. `--lora_alpha=28`.
|
| 59 |
+
|
| 60 |
+
## How to launch a web demo
|
| 61 |
+
|
| 62 |
+
1. Same as **How to inference in CLI: 1-5**.
|
| 63 |
+
2. Running with ```python3 web_demo.py --ckpt_path xxx --whisper_path xxx --beats_path xxx --vicuna_path xxx``` in A100-SXM-80GB. You can add `--low_resource` parameter if the GPU memory is not enough, and reduce the LoRA scaling factor to maintain the model's emergent abilities.
|
| 64 |
+
|
| 65 |
+
## Team
|
| 66 |
+
|
| 67 |
+
**Team Tsinghua**: Wenyi Yu, Changli Tang, Guangzhi Sun, Chao Zhang
|
| 68 |
+
|
| 69 |
+
**Team ByteDance**: Xianzhao Chen, Wei Li, Tian Tan, Lu Lu, Zejun Ma
|
| 70 |
+
|
| 71 |
+
## Citation
|
| 72 |
+
If you find SALMONN great and useful, please cite our paper:
|
| 73 |
+
```
|
| 74 |
+
@article{tang2023salmonn,
|
| 75 |
+
title={{SALMONN}: Towards Generic Hearing Abilities for Large Language Models},
|
| 76 |
+
author={Changli, Tang and Wenyi, Yu and Guangzhi, Sun and Xianzhao, Chen and Tian, Tan and Wei, Li and Lu, Lu and Zejun, Ma and Chao, Zhang},
|
| 77 |
+
journal={arXiv:2310.13289},
|
| 78 |
+
year={2023}
|
| 79 |
+
}
|
| 80 |
+
```
|
beats/BEATs.py
ADDED
|
@@ -0,0 +1,180 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# BEATs: Audio Pre-Training with Acoustic Tokenizers (https://arxiv.org/abs/2212.09058)
|
| 3 |
+
# Github source: https://github.com/microsoft/unilm/tree/master/beats
|
| 4 |
+
# Copyright (c) 2022 Microsoft
|
| 5 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 6 |
+
# Based on fairseq code bases
|
| 7 |
+
# https://github.com/pytorch/fairseq
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
from torch.nn import LayerNorm
|
| 14 |
+
import torchaudio.compliance.kaldi as ta_kaldi
|
| 15 |
+
|
| 16 |
+
from beats.backbone import (
|
| 17 |
+
TransformerEncoder,
|
| 18 |
+
)
|
| 19 |
+
|
| 20 |
+
import logging
|
| 21 |
+
from typing import Optional
|
| 22 |
+
|
| 23 |
+
logger = logging.getLogger(__name__)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class BEATsConfig:
|
| 27 |
+
def __init__(self, cfg=None):
|
| 28 |
+
self.input_patch_size: int = -1 # path size of patch embedding
|
| 29 |
+
self.embed_dim: int = 512 # patch embedding dimension
|
| 30 |
+
self.conv_bias: bool = False # include bias in conv encoder
|
| 31 |
+
|
| 32 |
+
self.encoder_layers: int = 12 # num encoder layers in the transformer
|
| 33 |
+
self.encoder_embed_dim: int = 768 # encoder embedding dimension
|
| 34 |
+
self.encoder_ffn_embed_dim: int = 3072 # encoder embedding dimension for FFN
|
| 35 |
+
self.encoder_attention_heads: int = 12 # num encoder attention heads
|
| 36 |
+
self.activation_fn: str = "gelu" # activation function to use
|
| 37 |
+
|
| 38 |
+
self.layer_wise_gradient_decay_ratio: float = 1.0 # ratio for layer-wise gradient decay
|
| 39 |
+
self.layer_norm_first: bool = False # apply layernorm first in the transformer
|
| 40 |
+
self.deep_norm: bool = False # apply deep_norm first in the transformer
|
| 41 |
+
|
| 42 |
+
# dropouts
|
| 43 |
+
self.dropout: float = 0.1 # dropout probability for the transformer
|
| 44 |
+
self.attention_dropout: float = 0.1 # dropout probability for attention weights
|
| 45 |
+
self.activation_dropout: float = 0.0 # dropout probability after activation in FFN
|
| 46 |
+
self.encoder_layerdrop: float = 0.0 # probability of dropping a tarnsformer layer
|
| 47 |
+
self.dropout_input: float = 0.0 # dropout to apply to the input (after feat extr)
|
| 48 |
+
|
| 49 |
+
# positional embeddings
|
| 50 |
+
self.conv_pos: int = 128 # number of filters for convolutional positional embeddings
|
| 51 |
+
self.conv_pos_groups: int = 16 # number of groups for convolutional positional embedding
|
| 52 |
+
|
| 53 |
+
# relative position embedding
|
| 54 |
+
self.relative_position_embedding: bool = False # apply relative position embedding
|
| 55 |
+
self.num_buckets: int = 320 # number of buckets for relative position embedding
|
| 56 |
+
self.max_distance: int = 1280 # maximum distance for relative position embedding
|
| 57 |
+
self.gru_rel_pos: bool = False # apply gated relative position embedding
|
| 58 |
+
|
| 59 |
+
# label predictor
|
| 60 |
+
self.finetuned_model: bool = False # whether the model is a fine-tuned model.
|
| 61 |
+
self.predictor_dropout: float = 0.1 # dropout probability for the predictor
|
| 62 |
+
self.predictor_class: int = 527 # target class number for the predictor
|
| 63 |
+
|
| 64 |
+
if cfg is not None:
|
| 65 |
+
self.update(cfg)
|
| 66 |
+
|
| 67 |
+
def update(self, cfg: dict):
|
| 68 |
+
self.__dict__.update(cfg)
|
| 69 |
+
|
| 70 |
+
|
| 71 |
+
class BEATs(nn.Module):
|
| 72 |
+
def __init__(
|
| 73 |
+
self,
|
| 74 |
+
cfg: BEATsConfig,
|
| 75 |
+
) -> None:
|
| 76 |
+
super().__init__()
|
| 77 |
+
logger.info(f"BEATs Config: {cfg.__dict__}")
|
| 78 |
+
|
| 79 |
+
self.cfg = cfg
|
| 80 |
+
|
| 81 |
+
self.embed = cfg.embed_dim
|
| 82 |
+
self.post_extract_proj = (
|
| 83 |
+
nn.Linear(self.embed, cfg.encoder_embed_dim)
|
| 84 |
+
if self.embed != cfg.encoder_embed_dim
|
| 85 |
+
else None
|
| 86 |
+
)
|
| 87 |
+
|
| 88 |
+
self.input_patch_size = cfg.input_patch_size
|
| 89 |
+
self.patch_embedding = nn.Conv2d(1, self.embed, kernel_size=self.input_patch_size, stride=self.input_patch_size,
|
| 90 |
+
bias=cfg.conv_bias)
|
| 91 |
+
|
| 92 |
+
self.dropout_input = nn.Dropout(cfg.dropout_input)
|
| 93 |
+
|
| 94 |
+
assert not cfg.deep_norm or not cfg.layer_norm_first
|
| 95 |
+
self.encoder = TransformerEncoder(cfg)
|
| 96 |
+
self.layer_norm = LayerNorm(self.embed)
|
| 97 |
+
|
| 98 |
+
if cfg.finetuned_model:
|
| 99 |
+
self.predictor_dropout = nn.Dropout(cfg.predictor_dropout)
|
| 100 |
+
self.predictor = nn.Linear(cfg.encoder_embed_dim, cfg.predictor_class)
|
| 101 |
+
else:
|
| 102 |
+
self.predictor = None
|
| 103 |
+
|
| 104 |
+
def forward_padding_mask(
|
| 105 |
+
self,
|
| 106 |
+
features: torch.Tensor,
|
| 107 |
+
padding_mask: torch.Tensor,
|
| 108 |
+
) -> torch.Tensor:
|
| 109 |
+
extra = padding_mask.size(1) % features.size(1)
|
| 110 |
+
if extra > 0:
|
| 111 |
+
padding_mask = padding_mask[:, :-extra]
|
| 112 |
+
padding_mask = padding_mask.view(
|
| 113 |
+
padding_mask.size(0), features.size(1), -1
|
| 114 |
+
)
|
| 115 |
+
padding_mask = padding_mask.all(-1)
|
| 116 |
+
return padding_mask
|
| 117 |
+
|
| 118 |
+
def preprocess(
|
| 119 |
+
self,
|
| 120 |
+
source: torch.Tensor,
|
| 121 |
+
fbank_mean: float = 15.41663,
|
| 122 |
+
fbank_std: float = 6.55582,
|
| 123 |
+
) -> torch.Tensor:
|
| 124 |
+
fbanks = []
|
| 125 |
+
for waveform in source:
|
| 126 |
+
waveform = waveform.unsqueeze(0) * 2 ** 15
|
| 127 |
+
fbank = ta_kaldi.fbank(waveform, num_mel_bins=128, sample_frequency=16000, frame_length=25, frame_shift=10)
|
| 128 |
+
fbanks.append(fbank)
|
| 129 |
+
fbank = torch.stack(fbanks, dim=0)
|
| 130 |
+
fbank = (fbank - fbank_mean) / (2 * fbank_std)
|
| 131 |
+
return fbank
|
| 132 |
+
|
| 133 |
+
def extract_features(
|
| 134 |
+
self,
|
| 135 |
+
source: torch.Tensor,
|
| 136 |
+
padding_mask: Optional[torch.Tensor] = None,
|
| 137 |
+
fbank_mean: float = 15.41663,
|
| 138 |
+
fbank_std: float = 6.55582,
|
| 139 |
+
feature_only=False,
|
| 140 |
+
):
|
| 141 |
+
fbank = self.preprocess(source, fbank_mean=fbank_mean, fbank_std=fbank_std).to(torch.float32)
|
| 142 |
+
|
| 143 |
+
if padding_mask is not None:
|
| 144 |
+
padding_mask = self.forward_padding_mask(fbank, padding_mask)
|
| 145 |
+
|
| 146 |
+
fbank = fbank.unsqueeze(1)
|
| 147 |
+
features = self.patch_embedding(fbank)
|
| 148 |
+
features = features.reshape(features.shape[0], features.shape[1], -1)
|
| 149 |
+
features = features.transpose(1, 2)
|
| 150 |
+
features = self.layer_norm(features)
|
| 151 |
+
|
| 152 |
+
if padding_mask is not None:
|
| 153 |
+
padding_mask = self.forward_padding_mask(features, padding_mask)
|
| 154 |
+
|
| 155 |
+
if self.post_extract_proj is not None:
|
| 156 |
+
features = self.post_extract_proj(features)
|
| 157 |
+
|
| 158 |
+
x = self.dropout_input(features)
|
| 159 |
+
|
| 160 |
+
x, layer_results = self.encoder(
|
| 161 |
+
x,
|
| 162 |
+
padding_mask=padding_mask,
|
| 163 |
+
)
|
| 164 |
+
|
| 165 |
+
if not feature_only and self.predictor is not None:
|
| 166 |
+
x = self.predictor_dropout(x)
|
| 167 |
+
logits = self.predictor(x)
|
| 168 |
+
|
| 169 |
+
if padding_mask is not None and padding_mask.any():
|
| 170 |
+
logits[padding_mask] = 0
|
| 171 |
+
logits = logits.sum(dim=1)
|
| 172 |
+
logits = logits / (~padding_mask).sum(dim=1).unsqueeze(-1).expand_as(logits)
|
| 173 |
+
else:
|
| 174 |
+
logits = logits.mean(dim=1)
|
| 175 |
+
|
| 176 |
+
lprobs = torch.sigmoid(logits)
|
| 177 |
+
|
| 178 |
+
return lprobs, padding_mask
|
| 179 |
+
else:
|
| 180 |
+
return x, padding_mask
|
beats/LICENSE_beats
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
The MIT License (MIT)
|
| 2 |
+
|
| 3 |
+
Copyright (c) Microsoft Corporation
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
beats/Tokenizers.py
ADDED
|
@@ -0,0 +1,172 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# BEATs: Audio Pre-Training with Acoustic Tokenizers (https://arxiv.org/abs/2212.09058)
|
| 3 |
+
# Github source: https://github.com/microsoft/unilm/tree/master/beats
|
| 4 |
+
# Copyright (c) 2022 Microsoft
|
| 5 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 6 |
+
# Based on fairseq code bases
|
| 7 |
+
# https://github.com/pytorch/fairseq
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
|
| 11 |
+
import torch
|
| 12 |
+
import torch.nn as nn
|
| 13 |
+
from torch.nn import LayerNorm
|
| 14 |
+
import torchaudio.compliance.kaldi as ta_kaldi
|
| 15 |
+
|
| 16 |
+
from beats.backbone import (
|
| 17 |
+
TransformerEncoder,
|
| 18 |
+
)
|
| 19 |
+
from beats.quantizer import (
|
| 20 |
+
NormEMAVectorQuantizer,
|
| 21 |
+
)
|
| 22 |
+
|
| 23 |
+
import logging
|
| 24 |
+
from typing import Optional
|
| 25 |
+
|
| 26 |
+
logger = logging.getLogger(__name__)
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class TokenizersConfig:
|
| 30 |
+
def __init__(self, cfg=None):
|
| 31 |
+
self.input_patch_size: int = -1 # path size of patch embedding
|
| 32 |
+
self.embed_dim: int = 512 # patch embedding dimension
|
| 33 |
+
self.conv_bias: bool = False # include bias in conv encoder
|
| 34 |
+
|
| 35 |
+
self.encoder_layers: int = 12 # num encoder layers in the transformer
|
| 36 |
+
self.encoder_embed_dim: int = 768 # encoder embedding dimension
|
| 37 |
+
self.encoder_ffn_embed_dim: int = 3072 # encoder embedding dimension for FFN
|
| 38 |
+
self.encoder_attention_heads: int = 12 # num encoder attention heads
|
| 39 |
+
self.activation_fn: str = "gelu" # activation function to use
|
| 40 |
+
|
| 41 |
+
self.layer_norm_first: bool = False # apply layernorm first in the transformer
|
| 42 |
+
self.deep_norm: bool = False # apply deep_norm first in the transformer
|
| 43 |
+
|
| 44 |
+
# dropouts
|
| 45 |
+
self.dropout: float = 0.1 # dropout probability for the transformer
|
| 46 |
+
self.attention_dropout: float = 0.1 # dropout probability for attention weights
|
| 47 |
+
self.activation_dropout: float = 0.0 # dropout probability after activation in FFN
|
| 48 |
+
self.encoder_layerdrop: float = 0.0 # probability of dropping a tarnsformer layer
|
| 49 |
+
self.dropout_input: float = 0.0 # dropout to apply to the input (after feat extr)
|
| 50 |
+
|
| 51 |
+
# positional embeddings
|
| 52 |
+
self.conv_pos: int = 128 # number of filters for convolutional positional embeddings
|
| 53 |
+
self.conv_pos_groups: int = 16 # number of groups for convolutional positional embedding
|
| 54 |
+
|
| 55 |
+
# relative position embedding
|
| 56 |
+
self.relative_position_embedding: bool = False # apply relative position embedding
|
| 57 |
+
self.num_buckets: int = 320 # number of buckets for relative position embedding
|
| 58 |
+
self.max_distance: int = 1280 # maximum distance for relative position embedding
|
| 59 |
+
self.gru_rel_pos: bool = False # apply gated relative position embedding
|
| 60 |
+
|
| 61 |
+
# quantizer
|
| 62 |
+
self.quant_n: int = 1024 # codebook number in quantizer
|
| 63 |
+
self.quant_dim: int = 256 # codebook dimension in quantizer
|
| 64 |
+
|
| 65 |
+
if cfg is not None:
|
| 66 |
+
self.update(cfg)
|
| 67 |
+
|
| 68 |
+
def update(self, cfg: dict):
|
| 69 |
+
self.__dict__.update(cfg)
|
| 70 |
+
|
| 71 |
+
|
| 72 |
+
class Tokenizers(nn.Module):
|
| 73 |
+
def __init__(
|
| 74 |
+
self,
|
| 75 |
+
cfg: TokenizersConfig,
|
| 76 |
+
) -> None:
|
| 77 |
+
super().__init__()
|
| 78 |
+
logger.info(f"Tokenizers Config: {cfg.__dict__}")
|
| 79 |
+
|
| 80 |
+
self.cfg = cfg
|
| 81 |
+
|
| 82 |
+
self.embed = cfg.embed_dim
|
| 83 |
+
self.post_extract_proj = (
|
| 84 |
+
nn.Linear(self.embed, cfg.encoder_embed_dim)
|
| 85 |
+
if self.embed != cfg.encoder_embed_dim
|
| 86 |
+
else None
|
| 87 |
+
)
|
| 88 |
+
|
| 89 |
+
self.input_patch_size = cfg.input_patch_size
|
| 90 |
+
self.patch_embedding = nn.Conv2d(1, self.embed, kernel_size=self.input_patch_size, stride=self.input_patch_size,
|
| 91 |
+
bias=cfg.conv_bias)
|
| 92 |
+
|
| 93 |
+
self.dropout_input = nn.Dropout(cfg.dropout_input)
|
| 94 |
+
|
| 95 |
+
assert not cfg.deep_norm or not cfg.layer_norm_first
|
| 96 |
+
self.encoder = TransformerEncoder(cfg)
|
| 97 |
+
self.layer_norm = LayerNorm(self.embed)
|
| 98 |
+
|
| 99 |
+
self.quantize = NormEMAVectorQuantizer(
|
| 100 |
+
n_embed=cfg.quant_n, embedding_dim=cfg.quant_dim, beta=1.0, kmeans_init=True, decay=0.99,
|
| 101 |
+
)
|
| 102 |
+
self.quant_n = cfg.quant_n
|
| 103 |
+
self.quantize_layer = nn.Sequential(
|
| 104 |
+
nn.Linear(cfg.encoder_embed_dim, cfg.encoder_embed_dim),
|
| 105 |
+
nn.Tanh(),
|
| 106 |
+
nn.Linear(cfg.encoder_embed_dim, cfg.quant_dim) # for quantize
|
| 107 |
+
)
|
| 108 |
+
|
| 109 |
+
def forward_padding_mask(
|
| 110 |
+
self,
|
| 111 |
+
features: torch.Tensor,
|
| 112 |
+
padding_mask: torch.Tensor,
|
| 113 |
+
) -> torch.Tensor:
|
| 114 |
+
extra = padding_mask.size(1) % features.size(1)
|
| 115 |
+
if extra > 0:
|
| 116 |
+
padding_mask = padding_mask[:, :-extra]
|
| 117 |
+
padding_mask = padding_mask.view(
|
| 118 |
+
padding_mask.size(0), features.size(1), -1
|
| 119 |
+
)
|
| 120 |
+
padding_mask = padding_mask.all(-1)
|
| 121 |
+
return padding_mask
|
| 122 |
+
|
| 123 |
+
def preprocess(
|
| 124 |
+
self,
|
| 125 |
+
source: torch.Tensor,
|
| 126 |
+
fbank_mean: float = 15.41663,
|
| 127 |
+
fbank_std: float = 6.55582,
|
| 128 |
+
) -> torch.Tensor:
|
| 129 |
+
fbanks = []
|
| 130 |
+
for waveform in source:
|
| 131 |
+
waveform = waveform.unsqueeze(0) * 2 ** 15
|
| 132 |
+
fbank = ta_kaldi.fbank(waveform, num_mel_bins=128, sample_frequency=16000, frame_length=25, frame_shift=10)
|
| 133 |
+
fbanks.append(fbank)
|
| 134 |
+
fbank = torch.stack(fbanks, dim=0)
|
| 135 |
+
fbank = (fbank - fbank_mean) / (2 * fbank_std)
|
| 136 |
+
return fbank
|
| 137 |
+
|
| 138 |
+
def extract_labels(
|
| 139 |
+
self,
|
| 140 |
+
source: torch.Tensor,
|
| 141 |
+
padding_mask: Optional[torch.Tensor] = None,
|
| 142 |
+
fbank_mean: float = 15.41663,
|
| 143 |
+
fbank_std: float = 6.55582,
|
| 144 |
+
):
|
| 145 |
+
fbank = self.preprocess(source, fbank_mean=fbank_mean, fbank_std=fbank_std)
|
| 146 |
+
|
| 147 |
+
if padding_mask is not None:
|
| 148 |
+
padding_mask = self.forward_padding_mask(fbank, padding_mask)
|
| 149 |
+
|
| 150 |
+
fbank = fbank.unsqueeze(1)
|
| 151 |
+
features = self.patch_embedding(fbank)
|
| 152 |
+
features = features.reshape(features.shape[0], features.shape[1], -1)
|
| 153 |
+
features = features.transpose(1, 2)
|
| 154 |
+
features = self.layer_norm(features)
|
| 155 |
+
|
| 156 |
+
if padding_mask is not None:
|
| 157 |
+
padding_mask = self.forward_padding_mask(features, padding_mask)
|
| 158 |
+
|
| 159 |
+
if self.post_extract_proj is not None:
|
| 160 |
+
features = self.post_extract_proj(features)
|
| 161 |
+
|
| 162 |
+
x = self.dropout_input(features)
|
| 163 |
+
|
| 164 |
+
x, layer_results = self.encoder(
|
| 165 |
+
x,
|
| 166 |
+
padding_mask=padding_mask,
|
| 167 |
+
)
|
| 168 |
+
|
| 169 |
+
quantize_input = self.quantize_layer(x)
|
| 170 |
+
quantize_feature, embed_loss, embed_ind = self.quantize(quantize_input)
|
| 171 |
+
|
| 172 |
+
return embed_ind
|
beats/__init__.py
ADDED
|
File without changes
|
beats/backbone.py
ADDED
|
@@ -0,0 +1,783 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# BEATs: Audio Pre-Training with Acoustic Tokenizers (https://arxiv.org/abs/2212.09058)
|
| 3 |
+
# Github source: https://github.com/microsoft/unilm/tree/master/beats
|
| 4 |
+
# Copyright (c) 2022 Microsoft
|
| 5 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 6 |
+
# Based on fairseq code bases
|
| 7 |
+
# https://github.com/pytorch/fairseq
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
import math
|
| 11 |
+
import numpy as np
|
| 12 |
+
from typing import Dict, Optional, Tuple
|
| 13 |
+
import torch
|
| 14 |
+
from torch import Tensor, nn
|
| 15 |
+
import torch.nn.functional as F
|
| 16 |
+
from torch.nn import LayerNorm, Parameter
|
| 17 |
+
from beats.modules import (
|
| 18 |
+
GradMultiply,
|
| 19 |
+
SamePad,
|
| 20 |
+
get_activation_fn,
|
| 21 |
+
GLU_Linear,
|
| 22 |
+
quant_noise,
|
| 23 |
+
)
|
| 24 |
+
|
| 25 |
+
|
| 26 |
+
class TransformerEncoder(nn.Module):
|
| 27 |
+
def __init__(self, args):
|
| 28 |
+
super().__init__()
|
| 29 |
+
|
| 30 |
+
self.dropout = args.dropout
|
| 31 |
+
self.embedding_dim = args.encoder_embed_dim
|
| 32 |
+
|
| 33 |
+
self.pos_conv = nn.Conv1d(
|
| 34 |
+
self.embedding_dim,
|
| 35 |
+
self.embedding_dim,
|
| 36 |
+
kernel_size=args.conv_pos,
|
| 37 |
+
padding=args.conv_pos // 2,
|
| 38 |
+
groups=args.conv_pos_groups,
|
| 39 |
+
)
|
| 40 |
+
dropout = 0
|
| 41 |
+
std = math.sqrt((4 * (1.0 - dropout)) / (args.conv_pos * self.embedding_dim))
|
| 42 |
+
nn.init.normal_(self.pos_conv.weight, mean=0, std=std)
|
| 43 |
+
nn.init.constant_(self.pos_conv.bias, 0)
|
| 44 |
+
|
| 45 |
+
self.pos_conv = nn.utils.weight_norm(self.pos_conv, name="weight", dim=2)
|
| 46 |
+
self.pos_conv = nn.Sequential(self.pos_conv, SamePad(args.conv_pos), nn.GELU())
|
| 47 |
+
|
| 48 |
+
if hasattr(args, "relative_position_embedding"):
|
| 49 |
+
self.relative_position_embedding = args.relative_position_embedding
|
| 50 |
+
self.num_buckets = args.num_buckets
|
| 51 |
+
self.max_distance = args.max_distance
|
| 52 |
+
else:
|
| 53 |
+
self.relative_position_embedding = False
|
| 54 |
+
self.num_buckets = 0
|
| 55 |
+
self.max_distance = 0
|
| 56 |
+
|
| 57 |
+
self.layers = nn.ModuleList(
|
| 58 |
+
[
|
| 59 |
+
TransformerSentenceEncoderLayer(
|
| 60 |
+
embedding_dim=self.embedding_dim,
|
| 61 |
+
ffn_embedding_dim=args.encoder_ffn_embed_dim,
|
| 62 |
+
num_attention_heads=args.encoder_attention_heads,
|
| 63 |
+
dropout=self.dropout,
|
| 64 |
+
attention_dropout=args.attention_dropout,
|
| 65 |
+
activation_dropout=args.activation_dropout,
|
| 66 |
+
activation_fn=args.activation_fn,
|
| 67 |
+
layer_norm_first=args.layer_norm_first,
|
| 68 |
+
deep_norm=args.deep_norm,
|
| 69 |
+
has_relative_attention_bias=self.relative_position_embedding,
|
| 70 |
+
num_buckets=self.num_buckets,
|
| 71 |
+
max_distance=self.max_distance,
|
| 72 |
+
gru_rel_pos=args.gru_rel_pos,
|
| 73 |
+
encoder_layers=args.encoder_layers,
|
| 74 |
+
)
|
| 75 |
+
for i in range(args.encoder_layers)
|
| 76 |
+
]
|
| 77 |
+
)
|
| 78 |
+
if self.relative_position_embedding:
|
| 79 |
+
for i in range(1, args.encoder_layers):
|
| 80 |
+
del self.layers[i].self_attn.relative_attention_bias
|
| 81 |
+
self.layers[i].self_attn.relative_attention_bias = self.layers[0].self_attn.relative_attention_bias
|
| 82 |
+
|
| 83 |
+
self.layer_norm_first = args.layer_norm_first
|
| 84 |
+
self.layer_norm = LayerNorm(self.embedding_dim)
|
| 85 |
+
self.layerdrop = args.encoder_layerdrop
|
| 86 |
+
|
| 87 |
+
self.apply(init_bert_params)
|
| 88 |
+
|
| 89 |
+
if args.deep_norm:
|
| 90 |
+
deep_norm_beta = math.pow(8 * args.encoder_layers, -1 / 4)
|
| 91 |
+
for i in range(args.encoder_layers):
|
| 92 |
+
nn.init.xavier_normal_(self.layers[i].self_attn.k_proj.weight, gain=1)
|
| 93 |
+
nn.init.xavier_normal_(self.layers[i].self_attn.v_proj.weight, gain=deep_norm_beta)
|
| 94 |
+
nn.init.xavier_normal_(self.layers[i].self_attn.q_proj.weight, gain=1)
|
| 95 |
+
nn.init.xavier_normal_(self.layers[i].self_attn.out_proj.weight, gain=deep_norm_beta)
|
| 96 |
+
nn.init.xavier_normal_(self.layers[i].fc1.weight, gain=deep_norm_beta)
|
| 97 |
+
nn.init.xavier_normal_(self.layers[i].fc2.weight, gain=deep_norm_beta)
|
| 98 |
+
|
| 99 |
+
self.layer_wise_gradient_decay_ratio = getattr(args, "layer_wise_gradient_decay_ratio", 1)
|
| 100 |
+
|
| 101 |
+
def forward(self, x, padding_mask=None, layer=None):
|
| 102 |
+
x, layer_results = self.extract_features(x, padding_mask, layer)
|
| 103 |
+
|
| 104 |
+
if self.layer_norm_first and layer is None:
|
| 105 |
+
x = self.layer_norm(x)
|
| 106 |
+
|
| 107 |
+
return x, layer_results
|
| 108 |
+
|
| 109 |
+
def extract_features(self, x, padding_mask=None, tgt_layer=None):
|
| 110 |
+
|
| 111 |
+
if padding_mask is not None:
|
| 112 |
+
x[padding_mask] = 0
|
| 113 |
+
|
| 114 |
+
x_conv = self.pos_conv(x.transpose(1, 2))
|
| 115 |
+
x_conv = x_conv.transpose(1, 2)
|
| 116 |
+
x = x + x_conv
|
| 117 |
+
|
| 118 |
+
if not self.layer_norm_first:
|
| 119 |
+
x = self.layer_norm(x)
|
| 120 |
+
|
| 121 |
+
x = F.dropout(x, p=self.dropout, training=self.training)
|
| 122 |
+
|
| 123 |
+
# B x T x C -> T x B x C
|
| 124 |
+
x = x.transpose(0, 1)
|
| 125 |
+
|
| 126 |
+
layer_results = []
|
| 127 |
+
z = None
|
| 128 |
+
if tgt_layer is not None:
|
| 129 |
+
layer_results.append((x, z))
|
| 130 |
+
r = None
|
| 131 |
+
pos_bias = None
|
| 132 |
+
for i, layer in enumerate(self.layers):
|
| 133 |
+
if self.layer_wise_gradient_decay_ratio != 1.0:
|
| 134 |
+
x = GradMultiply.apply(x, self.layer_wise_gradient_decay_ratio)
|
| 135 |
+
dropout_probability = np.random.random()
|
| 136 |
+
if not self.training or (dropout_probability > self.layerdrop):
|
| 137 |
+
x, z, pos_bias = layer(x, self_attn_padding_mask=padding_mask, need_weights=False, pos_bias=pos_bias)
|
| 138 |
+
if tgt_layer is not None:
|
| 139 |
+
layer_results.append((x, z))
|
| 140 |
+
if i == tgt_layer:
|
| 141 |
+
r = x
|
| 142 |
+
break
|
| 143 |
+
|
| 144 |
+
if r is not None:
|
| 145 |
+
x = r
|
| 146 |
+
|
| 147 |
+
# T x B x C -> B x T x C
|
| 148 |
+
x = x.transpose(0, 1)
|
| 149 |
+
|
| 150 |
+
return x, layer_results
|
| 151 |
+
|
| 152 |
+
|
| 153 |
+
class TransformerSentenceEncoderLayer(nn.Module):
|
| 154 |
+
def __init__(
|
| 155 |
+
self,
|
| 156 |
+
embedding_dim: float = 768,
|
| 157 |
+
ffn_embedding_dim: float = 3072,
|
| 158 |
+
num_attention_heads: float = 8,
|
| 159 |
+
dropout: float = 0.1,
|
| 160 |
+
attention_dropout: float = 0.1,
|
| 161 |
+
activation_dropout: float = 0.1,
|
| 162 |
+
activation_fn: str = "relu",
|
| 163 |
+
layer_norm_first: bool = False,
|
| 164 |
+
deep_norm: bool = False,
|
| 165 |
+
has_relative_attention_bias: bool = False,
|
| 166 |
+
num_buckets: int = 0,
|
| 167 |
+
max_distance: int = 0,
|
| 168 |
+
rescale_init: bool = False,
|
| 169 |
+
gru_rel_pos: bool = False,
|
| 170 |
+
encoder_layers: int = 0,
|
| 171 |
+
) -> None:
|
| 172 |
+
|
| 173 |
+
super().__init__()
|
| 174 |
+
self.embedding_dim = embedding_dim
|
| 175 |
+
self.dropout = dropout
|
| 176 |
+
self.activation_dropout = activation_dropout
|
| 177 |
+
|
| 178 |
+
self.activation_name = activation_fn
|
| 179 |
+
self.activation_fn = get_activation_fn(activation_fn)
|
| 180 |
+
self.self_attn = MultiheadAttention(
|
| 181 |
+
self.embedding_dim,
|
| 182 |
+
num_attention_heads,
|
| 183 |
+
dropout=attention_dropout,
|
| 184 |
+
self_attention=True,
|
| 185 |
+
has_relative_attention_bias=has_relative_attention_bias,
|
| 186 |
+
num_buckets=num_buckets,
|
| 187 |
+
max_distance=max_distance,
|
| 188 |
+
rescale_init=rescale_init,
|
| 189 |
+
gru_rel_pos=gru_rel_pos,
|
| 190 |
+
)
|
| 191 |
+
|
| 192 |
+
self.dropout1 = nn.Dropout(dropout)
|
| 193 |
+
self.dropout2 = nn.Dropout(self.activation_dropout)
|
| 194 |
+
self.dropout3 = nn.Dropout(dropout)
|
| 195 |
+
|
| 196 |
+
self.layer_norm_first = layer_norm_first
|
| 197 |
+
|
| 198 |
+
self.self_attn_layer_norm = LayerNorm(self.embedding_dim)
|
| 199 |
+
|
| 200 |
+
if self.activation_name == "glu":
|
| 201 |
+
self.fc1 = GLU_Linear(self.embedding_dim, ffn_embedding_dim, "swish")
|
| 202 |
+
else:
|
| 203 |
+
self.fc1 = nn.Linear(self.embedding_dim, ffn_embedding_dim)
|
| 204 |
+
self.fc2 = nn.Linear(ffn_embedding_dim, self.embedding_dim)
|
| 205 |
+
|
| 206 |
+
self.final_layer_norm = LayerNorm(self.embedding_dim)
|
| 207 |
+
|
| 208 |
+
self.deep_norm = deep_norm
|
| 209 |
+
if self.deep_norm:
|
| 210 |
+
self.deep_norm_alpha = math.pow(2 * encoder_layers, 1 / 4)
|
| 211 |
+
else:
|
| 212 |
+
self.deep_norm_alpha = 1
|
| 213 |
+
|
| 214 |
+
def forward(
|
| 215 |
+
self,
|
| 216 |
+
x: torch.Tensor,
|
| 217 |
+
self_attn_mask: torch.Tensor = None,
|
| 218 |
+
self_attn_padding_mask: torch.Tensor = None,
|
| 219 |
+
need_weights: bool = False,
|
| 220 |
+
pos_bias=None
|
| 221 |
+
):
|
| 222 |
+
residual = x
|
| 223 |
+
|
| 224 |
+
if self.layer_norm_first:
|
| 225 |
+
x = self.self_attn_layer_norm(x)
|
| 226 |
+
x, attn, pos_bias = self.self_attn(
|
| 227 |
+
query=x,
|
| 228 |
+
key=x,
|
| 229 |
+
value=x,
|
| 230 |
+
key_padding_mask=self_attn_padding_mask,
|
| 231 |
+
need_weights=False,
|
| 232 |
+
attn_mask=self_attn_mask,
|
| 233 |
+
position_bias=pos_bias
|
| 234 |
+
)
|
| 235 |
+
x = self.dropout1(x)
|
| 236 |
+
x = residual + x
|
| 237 |
+
|
| 238 |
+
residual = x
|
| 239 |
+
x = self.final_layer_norm(x)
|
| 240 |
+
if self.activation_name == "glu":
|
| 241 |
+
x = self.fc1(x)
|
| 242 |
+
else:
|
| 243 |
+
x = self.activation_fn(self.fc1(x))
|
| 244 |
+
x = self.dropout2(x)
|
| 245 |
+
x = self.fc2(x)
|
| 246 |
+
x = self.dropout3(x)
|
| 247 |
+
x = residual + x
|
| 248 |
+
else:
|
| 249 |
+
x, attn, pos_bias = self.self_attn(
|
| 250 |
+
query=x,
|
| 251 |
+
key=x,
|
| 252 |
+
value=x,
|
| 253 |
+
key_padding_mask=self_attn_padding_mask,
|
| 254 |
+
need_weights=need_weights,
|
| 255 |
+
attn_mask=self_attn_mask,
|
| 256 |
+
position_bias=pos_bias
|
| 257 |
+
)
|
| 258 |
+
|
| 259 |
+
x = self.dropout1(x)
|
| 260 |
+
x = residual * self.deep_norm_alpha + x
|
| 261 |
+
|
| 262 |
+
x = self.self_attn_layer_norm(x)
|
| 263 |
+
|
| 264 |
+
residual = x
|
| 265 |
+
if self.activation_name == "glu":
|
| 266 |
+
x = self.fc1(x)
|
| 267 |
+
else:
|
| 268 |
+
x = self.activation_fn(self.fc1(x))
|
| 269 |
+
x = self.dropout2(x)
|
| 270 |
+
x = self.fc2(x)
|
| 271 |
+
x = self.dropout3(x)
|
| 272 |
+
x = residual * self.deep_norm_alpha + x
|
| 273 |
+
x = self.final_layer_norm(x)
|
| 274 |
+
|
| 275 |
+
return x, attn, pos_bias
|
| 276 |
+
|
| 277 |
+
|
| 278 |
+
class MultiheadAttention(nn.Module):
|
| 279 |
+
"""Multi-headed attention.
|
| 280 |
+
|
| 281 |
+
See "Attention Is All You Need" for more details.
|
| 282 |
+
"""
|
| 283 |
+
|
| 284 |
+
def __init__(
|
| 285 |
+
self,
|
| 286 |
+
embed_dim,
|
| 287 |
+
num_heads,
|
| 288 |
+
kdim=None,
|
| 289 |
+
vdim=None,
|
| 290 |
+
dropout=0.0,
|
| 291 |
+
bias=True,
|
| 292 |
+
add_bias_kv=False,
|
| 293 |
+
add_zero_attn=False,
|
| 294 |
+
self_attention=False,
|
| 295 |
+
encoder_decoder_attention=False,
|
| 296 |
+
q_noise=0.0,
|
| 297 |
+
qn_block_size=8,
|
| 298 |
+
has_relative_attention_bias=False,
|
| 299 |
+
num_buckets=32,
|
| 300 |
+
max_distance=128,
|
| 301 |
+
gru_rel_pos=False,
|
| 302 |
+
rescale_init=False,
|
| 303 |
+
):
|
| 304 |
+
super().__init__()
|
| 305 |
+
self.embed_dim = embed_dim
|
| 306 |
+
self.kdim = kdim if kdim is not None else embed_dim
|
| 307 |
+
self.vdim = vdim if vdim is not None else embed_dim
|
| 308 |
+
self.qkv_same_dim = self.kdim == embed_dim and self.vdim == embed_dim
|
| 309 |
+
|
| 310 |
+
self.num_heads = num_heads
|
| 311 |
+
self.dropout_module = nn.Dropout(dropout)
|
| 312 |
+
|
| 313 |
+
self.has_relative_attention_bias = has_relative_attention_bias
|
| 314 |
+
self.num_buckets = num_buckets
|
| 315 |
+
self.max_distance = max_distance
|
| 316 |
+
if self.has_relative_attention_bias:
|
| 317 |
+
self.relative_attention_bias = nn.Embedding(num_buckets, num_heads)
|
| 318 |
+
|
| 319 |
+
self.head_dim = embed_dim // num_heads
|
| 320 |
+
self.q_head_dim = self.head_dim
|
| 321 |
+
self.k_head_dim = self.head_dim
|
| 322 |
+
assert (
|
| 323 |
+
self.head_dim * num_heads == self.embed_dim
|
| 324 |
+
), "embed_dim must be divisible by num_heads"
|
| 325 |
+
self.scaling = self.head_dim ** -0.5
|
| 326 |
+
|
| 327 |
+
self.self_attention = self_attention
|
| 328 |
+
self.encoder_decoder_attention = encoder_decoder_attention
|
| 329 |
+
|
| 330 |
+
assert not self.self_attention or self.qkv_same_dim, (
|
| 331 |
+
"Self-attention requires query, key and " "value to be of the same size"
|
| 332 |
+
)
|
| 333 |
+
|
| 334 |
+
k_bias = True
|
| 335 |
+
if rescale_init:
|
| 336 |
+
k_bias = False
|
| 337 |
+
|
| 338 |
+
k_embed_dim = embed_dim
|
| 339 |
+
q_embed_dim = embed_dim
|
| 340 |
+
|
| 341 |
+
self.k_proj = quant_noise(
|
| 342 |
+
nn.Linear(self.kdim, k_embed_dim, bias=k_bias), q_noise, qn_block_size
|
| 343 |
+
)
|
| 344 |
+
self.v_proj = quant_noise(
|
| 345 |
+
nn.Linear(self.vdim, embed_dim, bias=bias), q_noise, qn_block_size
|
| 346 |
+
)
|
| 347 |
+
self.q_proj = quant_noise(
|
| 348 |
+
nn.Linear(embed_dim, q_embed_dim, bias=bias), q_noise, qn_block_size
|
| 349 |
+
)
|
| 350 |
+
|
| 351 |
+
self.out_proj = quant_noise(
|
| 352 |
+
nn.Linear(embed_dim, embed_dim, bias=bias), q_noise, qn_block_size
|
| 353 |
+
)
|
| 354 |
+
|
| 355 |
+
if add_bias_kv:
|
| 356 |
+
self.bias_k = Parameter(torch.Tensor(1, 1, embed_dim))
|
| 357 |
+
self.bias_v = Parameter(torch.Tensor(1, 1, embed_dim))
|
| 358 |
+
else:
|
| 359 |
+
self.bias_k = self.bias_v = None
|
| 360 |
+
|
| 361 |
+
self.add_zero_attn = add_zero_attn
|
| 362 |
+
|
| 363 |
+
self.gru_rel_pos = gru_rel_pos
|
| 364 |
+
if self.gru_rel_pos:
|
| 365 |
+
self.grep_linear = nn.Linear(self.q_head_dim, 8)
|
| 366 |
+
self.grep_a = nn.Parameter(torch.ones(1, num_heads, 1, 1))
|
| 367 |
+
|
| 368 |
+
self.reset_parameters()
|
| 369 |
+
|
| 370 |
+
def reset_parameters(self):
|
| 371 |
+
if self.qkv_same_dim:
|
| 372 |
+
# Empirically observed the convergence to be much better with
|
| 373 |
+
# the scaled initialization
|
| 374 |
+
nn.init.xavier_uniform_(self.k_proj.weight, gain=1 / math.sqrt(2))
|
| 375 |
+
nn.init.xavier_uniform_(self.v_proj.weight, gain=1 / math.sqrt(2))
|
| 376 |
+
nn.init.xavier_uniform_(self.q_proj.weight, gain=1 / math.sqrt(2))
|
| 377 |
+
else:
|
| 378 |
+
nn.init.xavier_uniform_(self.k_proj.weight)
|
| 379 |
+
nn.init.xavier_uniform_(self.v_proj.weight)
|
| 380 |
+
nn.init.xavier_uniform_(self.q_proj.weight)
|
| 381 |
+
|
| 382 |
+
nn.init.xavier_uniform_(self.out_proj.weight)
|
| 383 |
+
if self.out_proj.bias is not None:
|
| 384 |
+
nn.init.constant_(self.out_proj.bias, 0.0)
|
| 385 |
+
if self.bias_k is not None:
|
| 386 |
+
nn.init.xavier_normal_(self.bias_k)
|
| 387 |
+
if self.bias_v is not None:
|
| 388 |
+
nn.init.xavier_normal_(self.bias_v)
|
| 389 |
+
if self.has_relative_attention_bias:
|
| 390 |
+
nn.init.xavier_normal_(self.relative_attention_bias.weight)
|
| 391 |
+
|
| 392 |
+
def _relative_positions_bucket(self, relative_positions, bidirectional=True):
|
| 393 |
+
num_buckets = self.num_buckets
|
| 394 |
+
max_distance = self.max_distance
|
| 395 |
+
relative_buckets = 0
|
| 396 |
+
|
| 397 |
+
if bidirectional:
|
| 398 |
+
num_buckets = num_buckets // 2
|
| 399 |
+
relative_buckets += (relative_positions > 0).to(torch.long) * num_buckets
|
| 400 |
+
relative_positions = torch.abs(relative_positions)
|
| 401 |
+
else:
|
| 402 |
+
relative_positions = -torch.min(relative_positions, torch.zeros_like(relative_positions))
|
| 403 |
+
|
| 404 |
+
max_exact = num_buckets // 2
|
| 405 |
+
is_small = relative_positions < max_exact
|
| 406 |
+
|
| 407 |
+
relative_postion_if_large = max_exact + (
|
| 408 |
+
torch.log(relative_positions.float() / max_exact)
|
| 409 |
+
/ math.log(max_distance / max_exact)
|
| 410 |
+
* (num_buckets - max_exact)
|
| 411 |
+
).to(torch.long)
|
| 412 |
+
relative_postion_if_large = torch.min(
|
| 413 |
+
relative_postion_if_large, torch.full_like(relative_postion_if_large, num_buckets - 1)
|
| 414 |
+
)
|
| 415 |
+
|
| 416 |
+
relative_buckets += torch.where(is_small, relative_positions, relative_postion_if_large)
|
| 417 |
+
return relative_buckets
|
| 418 |
+
|
| 419 |
+
def compute_bias(self, query_length, key_length):
|
| 420 |
+
context_position = torch.arange(query_length, dtype=torch.long)[:, None]
|
| 421 |
+
memory_position = torch.arange(key_length, dtype=torch.long)[None, :]
|
| 422 |
+
relative_position = memory_position - context_position
|
| 423 |
+
relative_position_bucket = self._relative_positions_bucket(
|
| 424 |
+
relative_position,
|
| 425 |
+
bidirectional=True
|
| 426 |
+
)
|
| 427 |
+
relative_position_bucket = relative_position_bucket.to(self.relative_attention_bias.weight.device)
|
| 428 |
+
values = self.relative_attention_bias(relative_position_bucket)
|
| 429 |
+
values = values.permute([2, 0, 1])
|
| 430 |
+
return values
|
| 431 |
+
|
| 432 |
+
def forward(
|
| 433 |
+
self,
|
| 434 |
+
query,
|
| 435 |
+
key: Optional[Tensor],
|
| 436 |
+
value: Optional[Tensor],
|
| 437 |
+
key_padding_mask: Optional[Tensor] = None,
|
| 438 |
+
incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]] = None,
|
| 439 |
+
need_weights: bool = True,
|
| 440 |
+
static_kv: bool = False,
|
| 441 |
+
attn_mask: Optional[Tensor] = None,
|
| 442 |
+
before_softmax: bool = False,
|
| 443 |
+
need_head_weights: bool = False,
|
| 444 |
+
position_bias: Optional[Tensor] = None
|
| 445 |
+
) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
|
| 446 |
+
"""Input shape: Time x Batch x Channel
|
| 447 |
+
|
| 448 |
+
Args:
|
| 449 |
+
key_padding_mask (ByteTensor, optional): mask to exclude
|
| 450 |
+
keys that are pads, of shape `(batch, src_len)`, where
|
| 451 |
+
padding elements are indicated by 1s.
|
| 452 |
+
need_weights (bool, optional): return the attention weights,
|
| 453 |
+
averaged over heads (default: False).
|
| 454 |
+
attn_mask (ByteTensor, optional): typically used to
|
| 455 |
+
implement causal attention, where the mask prevents the
|
| 456 |
+
attention from looking forward in time (default: None).
|
| 457 |
+
before_softmax (bool, optional): return the raw attention
|
| 458 |
+
weights and values before the attention softmax.
|
| 459 |
+
need_head_weights (bool, optional): return the attention
|
| 460 |
+
weights for each head. Implies *need_weights*. Default:
|
| 461 |
+
return the average attention weights over all heads.
|
| 462 |
+
"""
|
| 463 |
+
if need_head_weights:
|
| 464 |
+
need_weights = True
|
| 465 |
+
|
| 466 |
+
is_tpu = query.device.type == "xla"
|
| 467 |
+
|
| 468 |
+
tgt_len, bsz, embed_dim = query.size()
|
| 469 |
+
src_len = tgt_len
|
| 470 |
+
assert embed_dim == self.embed_dim
|
| 471 |
+
assert list(query.size()) == [tgt_len, bsz, embed_dim]
|
| 472 |
+
if key is not None:
|
| 473 |
+
src_len, key_bsz, _ = key.size()
|
| 474 |
+
if not torch.jit.is_scripting():
|
| 475 |
+
assert key_bsz == bsz
|
| 476 |
+
assert value is not None
|
| 477 |
+
assert src_len, bsz == value.shape[:2]
|
| 478 |
+
|
| 479 |
+
if self.has_relative_attention_bias and position_bias is None:
|
| 480 |
+
position_bias = self.compute_bias(tgt_len, src_len)
|
| 481 |
+
position_bias = position_bias.unsqueeze(0).repeat(bsz, 1, 1, 1).view(bsz * self.num_heads, tgt_len, src_len)
|
| 482 |
+
|
| 483 |
+
if incremental_state is not None:
|
| 484 |
+
saved_state = self._get_input_buffer(incremental_state)
|
| 485 |
+
if saved_state is not None and "prev_key" in saved_state:
|
| 486 |
+
# previous time steps are cached - no need to recompute
|
| 487 |
+
# key and value if they are static
|
| 488 |
+
if static_kv:
|
| 489 |
+
assert self.encoder_decoder_attention and not self.self_attention
|
| 490 |
+
key = value = None
|
| 491 |
+
else:
|
| 492 |
+
saved_state = None
|
| 493 |
+
|
| 494 |
+
if self.self_attention:
|
| 495 |
+
q = self.q_proj(query)
|
| 496 |
+
k = self.k_proj(query)
|
| 497 |
+
v = self.v_proj(query)
|
| 498 |
+
elif self.encoder_decoder_attention:
|
| 499 |
+
# encoder-decoder attention
|
| 500 |
+
q = self.q_proj(query)
|
| 501 |
+
if key is None:
|
| 502 |
+
assert value is None
|
| 503 |
+
k = v = None
|
| 504 |
+
else:
|
| 505 |
+
k = self.k_proj(key)
|
| 506 |
+
v = self.v_proj(key)
|
| 507 |
+
|
| 508 |
+
else:
|
| 509 |
+
assert key is not None and value is not None
|
| 510 |
+
q = self.q_proj(query)
|
| 511 |
+
k = self.k_proj(key)
|
| 512 |
+
v = self.v_proj(value)
|
| 513 |
+
q *= self.scaling
|
| 514 |
+
alpha = 32
|
| 515 |
+
q *= 1 / alpha
|
| 516 |
+
|
| 517 |
+
if self.bias_k is not None:
|
| 518 |
+
assert self.bias_v is not None
|
| 519 |
+
k = torch.cat([k, self.bias_k.repeat(1, bsz, 1)])
|
| 520 |
+
v = torch.cat([v, self.bias_v.repeat(1, bsz, 1)])
|
| 521 |
+
if attn_mask is not None:
|
| 522 |
+
attn_mask = torch.cat(
|
| 523 |
+
[attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1
|
| 524 |
+
)
|
| 525 |
+
if key_padding_mask is not None:
|
| 526 |
+
key_padding_mask = torch.cat(
|
| 527 |
+
[
|
| 528 |
+
key_padding_mask,
|
| 529 |
+
key_padding_mask.new_zeros(key_padding_mask.size(0), 1),
|
| 530 |
+
],
|
| 531 |
+
dim=1,
|
| 532 |
+
)
|
| 533 |
+
|
| 534 |
+
q = (
|
| 535 |
+
q.contiguous()
|
| 536 |
+
.view(tgt_len, bsz * self.num_heads, self.q_head_dim)
|
| 537 |
+
.transpose(0, 1)
|
| 538 |
+
)
|
| 539 |
+
if k is not None:
|
| 540 |
+
k = (
|
| 541 |
+
k.contiguous()
|
| 542 |
+
.view(-1, bsz * self.num_heads, self.k_head_dim)
|
| 543 |
+
.transpose(0, 1)
|
| 544 |
+
)
|
| 545 |
+
if v is not None:
|
| 546 |
+
v = (
|
| 547 |
+
v.contiguous()
|
| 548 |
+
.view(-1, bsz * self.num_heads, self.head_dim)
|
| 549 |
+
.transpose(0, 1)
|
| 550 |
+
)
|
| 551 |
+
|
| 552 |
+
if saved_state is not None:
|
| 553 |
+
# saved states are stored with shape (bsz, num_heads, seq_len, head_dim)
|
| 554 |
+
if "prev_key" in saved_state:
|
| 555 |
+
_prev_key = saved_state["prev_key"]
|
| 556 |
+
assert _prev_key is not None
|
| 557 |
+
prev_key = _prev_key.view(bsz * self.num_heads, -1, self.head_dim)
|
| 558 |
+
if static_kv:
|
| 559 |
+
k = prev_key
|
| 560 |
+
else:
|
| 561 |
+
assert k is not None
|
| 562 |
+
k = torch.cat([prev_key, k], dim=1)
|
| 563 |
+
src_len = k.size(1)
|
| 564 |
+
if "prev_value" in saved_state:
|
| 565 |
+
_prev_value = saved_state["prev_value"]
|
| 566 |
+
assert _prev_value is not None
|
| 567 |
+
prev_value = _prev_value.view(bsz * self.num_heads, -1, self.head_dim)
|
| 568 |
+
if static_kv:
|
| 569 |
+
v = prev_value
|
| 570 |
+
else:
|
| 571 |
+
assert v is not None
|
| 572 |
+
v = torch.cat([prev_value, v], dim=1)
|
| 573 |
+
prev_key_padding_mask: Optional[Tensor] = None
|
| 574 |
+
if "prev_key_padding_mask" in saved_state:
|
| 575 |
+
prev_key_padding_mask = saved_state["prev_key_padding_mask"]
|
| 576 |
+
assert k is not None and v is not None
|
| 577 |
+
key_padding_mask = MultiheadAttention._append_prev_key_padding_mask(
|
| 578 |
+
key_padding_mask=key_padding_mask,
|
| 579 |
+
prev_key_padding_mask=prev_key_padding_mask,
|
| 580 |
+
batch_size=bsz,
|
| 581 |
+
src_len=k.size(1),
|
| 582 |
+
static_kv=static_kv,
|
| 583 |
+
)
|
| 584 |
+
|
| 585 |
+
saved_state["prev_key"] = k.view(bsz, self.num_heads, -1, self.head_dim)
|
| 586 |
+
saved_state["prev_value"] = v.view(bsz, self.num_heads, -1, self.head_dim)
|
| 587 |
+
saved_state["prev_key_padding_mask"] = key_padding_mask
|
| 588 |
+
# In this branch incremental_state is never None
|
| 589 |
+
assert incremental_state is not None
|
| 590 |
+
incremental_state = self._set_input_buffer(incremental_state, saved_state)
|
| 591 |
+
assert k is not None
|
| 592 |
+
assert k.size(1) == src_len
|
| 593 |
+
|
| 594 |
+
# This is part of a workaround to get around fork/join parallelism
|
| 595 |
+
# not supporting Optional types.
|
| 596 |
+
if key_padding_mask is not None and key_padding_mask.dim() == 0:
|
| 597 |
+
key_padding_mask = None
|
| 598 |
+
|
| 599 |
+
if key_padding_mask is not None:
|
| 600 |
+
assert key_padding_mask.size(0) == bsz
|
| 601 |
+
assert key_padding_mask.size(1) == src_len
|
| 602 |
+
|
| 603 |
+
if self.add_zero_attn:
|
| 604 |
+
assert v is not None
|
| 605 |
+
src_len += 1
|
| 606 |
+
k = torch.cat([k, k.new_zeros((k.size(0), 1) + k.size()[2:])], dim=1)
|
| 607 |
+
v = torch.cat([v, v.new_zeros((v.size(0), 1) + v.size()[2:])], dim=1)
|
| 608 |
+
if attn_mask is not None:
|
| 609 |
+
attn_mask = torch.cat(
|
| 610 |
+
[attn_mask, attn_mask.new_zeros(attn_mask.size(0), 1)], dim=1
|
| 611 |
+
)
|
| 612 |
+
if key_padding_mask is not None:
|
| 613 |
+
key_padding_mask = torch.cat(
|
| 614 |
+
[
|
| 615 |
+
key_padding_mask,
|
| 616 |
+
torch.zeros(key_padding_mask.size(0), 1).type_as(
|
| 617 |
+
key_padding_mask
|
| 618 |
+
),
|
| 619 |
+
],
|
| 620 |
+
dim=1,
|
| 621 |
+
)
|
| 622 |
+
|
| 623 |
+
attn_weights = torch.bmm(q, k.transpose(1, 2))
|
| 624 |
+
attn_weights = (attn_weights - attn_weights.max(dim=-1, keepdim=True)[0]) * alpha
|
| 625 |
+
attn_weights = self.apply_sparse_mask(attn_weights, tgt_len, src_len, bsz)
|
| 626 |
+
|
| 627 |
+
assert list(attn_weights.size()) == [bsz * self.num_heads, tgt_len, src_len]
|
| 628 |
+
|
| 629 |
+
if attn_mask is not None:
|
| 630 |
+
attn_mask = attn_mask.unsqueeze(0)
|
| 631 |
+
attn_weights += attn_mask
|
| 632 |
+
|
| 633 |
+
if key_padding_mask is not None:
|
| 634 |
+
# don't attend to padding symbols
|
| 635 |
+
attn_weights = attn_weights.view(bsz, self.num_heads, tgt_len, src_len)
|
| 636 |
+
if not is_tpu:
|
| 637 |
+
attn_weights = attn_weights.masked_fill(
|
| 638 |
+
key_padding_mask.unsqueeze(1).unsqueeze(2).to(torch.bool),
|
| 639 |
+
float("-inf"),
|
| 640 |
+
)
|
| 641 |
+
else:
|
| 642 |
+
attn_weights = attn_weights.transpose(0, 2)
|
| 643 |
+
attn_weights = attn_weights.masked_fill(key_padding_mask, float("-inf"))
|
| 644 |
+
attn_weights = attn_weights.transpose(0, 2)
|
| 645 |
+
attn_weights = attn_weights.view(bsz * self.num_heads, tgt_len, src_len)
|
| 646 |
+
|
| 647 |
+
if before_softmax:
|
| 648 |
+
return attn_weights, v, position_bias
|
| 649 |
+
|
| 650 |
+
if position_bias is not None:
|
| 651 |
+
attn_mask_rel_pos = position_bias
|
| 652 |
+
if self.gru_rel_pos == 1:
|
| 653 |
+
query_layer = q.view(bsz, self.num_heads, tgt_len, self.q_head_dim) * alpha / self.scaling
|
| 654 |
+
_B, _H, _L, __ = query_layer.size()
|
| 655 |
+
gate_a, gate_b = torch.sigmoid(self.grep_linear(query_layer).view(
|
| 656 |
+
_B, _H, _L, 2, 4).sum(-1, keepdim=False)).chunk(2, dim=-1)
|
| 657 |
+
gate_a_1 = gate_a * (gate_b * self.grep_a - 1.0) + 2.0
|
| 658 |
+
attn_mask_rel_pos = gate_a_1.view(bsz * self.num_heads, tgt_len, 1) * position_bias
|
| 659 |
+
|
| 660 |
+
attn_mask_rel_pos = attn_mask_rel_pos.view(attn_weights.size())
|
| 661 |
+
|
| 662 |
+
attn_weights = attn_weights + attn_mask_rel_pos
|
| 663 |
+
|
| 664 |
+
attn_weights_float = F.softmax(
|
| 665 |
+
attn_weights, dim=-1
|
| 666 |
+
)
|
| 667 |
+
attn_weights = attn_weights_float.type_as(attn_weights)
|
| 668 |
+
attn_probs = self.dropout_module(attn_weights)
|
| 669 |
+
|
| 670 |
+
assert v is not None
|
| 671 |
+
attn = torch.bmm(attn_probs, v)
|
| 672 |
+
assert list(attn.size()) == [bsz * self.num_heads, tgt_len, self.head_dim]
|
| 673 |
+
attn = attn.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
|
| 674 |
+
attn = self.out_proj(attn)
|
| 675 |
+
attn_weights: Optional[Tensor] = None
|
| 676 |
+
if need_weights:
|
| 677 |
+
attn_weights = attn_weights_float.view(
|
| 678 |
+
bsz, self.num_heads, tgt_len, src_len
|
| 679 |
+
).transpose(1, 0)
|
| 680 |
+
if not need_head_weights:
|
| 681 |
+
# average attention weights over heads
|
| 682 |
+
attn_weights = attn_weights.mean(dim=0)
|
| 683 |
+
|
| 684 |
+
return attn, attn_weights, position_bias
|
| 685 |
+
|
| 686 |
+
@staticmethod
|
| 687 |
+
def _append_prev_key_padding_mask(
|
| 688 |
+
key_padding_mask: Optional[Tensor],
|
| 689 |
+
prev_key_padding_mask: Optional[Tensor],
|
| 690 |
+
batch_size: int,
|
| 691 |
+
src_len: int,
|
| 692 |
+
static_kv: bool,
|
| 693 |
+
) -> Optional[Tensor]:
|
| 694 |
+
# saved key padding masks have shape (bsz, seq_len)
|
| 695 |
+
if prev_key_padding_mask is not None and static_kv:
|
| 696 |
+
new_key_padding_mask = prev_key_padding_mask
|
| 697 |
+
elif prev_key_padding_mask is not None and key_padding_mask is not None:
|
| 698 |
+
new_key_padding_mask = torch.cat(
|
| 699 |
+
[prev_key_padding_mask.float(), key_padding_mask.float()], dim=1
|
| 700 |
+
)
|
| 701 |
+
# During incremental decoding, as the padding token enters and
|
| 702 |
+
# leaves the frame, there will be a time when prev or current
|
| 703 |
+
# is None
|
| 704 |
+
elif prev_key_padding_mask is not None:
|
| 705 |
+
if src_len > prev_key_padding_mask.size(1):
|
| 706 |
+
filler = torch.zeros(
|
| 707 |
+
(batch_size, src_len - prev_key_padding_mask.size(1)),
|
| 708 |
+
device=prev_key_padding_mask.device,
|
| 709 |
+
)
|
| 710 |
+
new_key_padding_mask = torch.cat(
|
| 711 |
+
[prev_key_padding_mask.float(), filler.float()], dim=1
|
| 712 |
+
)
|
| 713 |
+
else:
|
| 714 |
+
new_key_padding_mask = prev_key_padding_mask.float()
|
| 715 |
+
elif key_padding_mask is not None:
|
| 716 |
+
if src_len > key_padding_mask.size(1):
|
| 717 |
+
filler = torch.zeros(
|
| 718 |
+
(batch_size, src_len - key_padding_mask.size(1)),
|
| 719 |
+
device=key_padding_mask.device,
|
| 720 |
+
)
|
| 721 |
+
new_key_padding_mask = torch.cat(
|
| 722 |
+
[filler.float(), key_padding_mask.float()], dim=1
|
| 723 |
+
)
|
| 724 |
+
else:
|
| 725 |
+
new_key_padding_mask = key_padding_mask.float()
|
| 726 |
+
else:
|
| 727 |
+
new_key_padding_mask = prev_key_padding_mask
|
| 728 |
+
return new_key_padding_mask
|
| 729 |
+
|
| 730 |
+
def _get_input_buffer(
|
| 731 |
+
self, incremental_state: Optional[Dict[str, Dict[str, Optional[Tensor]]]]
|
| 732 |
+
) -> Dict[str, Optional[Tensor]]:
|
| 733 |
+
result = self.get_incremental_state(incremental_state, "attn_state")
|
| 734 |
+
if result is not None:
|
| 735 |
+
return result
|
| 736 |
+
else:
|
| 737 |
+
empty_result: Dict[str, Optional[Tensor]] = {}
|
| 738 |
+
return empty_result
|
| 739 |
+
|
| 740 |
+
def _set_input_buffer(
|
| 741 |
+
self,
|
| 742 |
+
incremental_state: Dict[str, Dict[str, Optional[Tensor]]],
|
| 743 |
+
buffer: Dict[str, Optional[Tensor]],
|
| 744 |
+
):
|
| 745 |
+
return self.set_incremental_state(incremental_state, "attn_state", buffer)
|
| 746 |
+
|
| 747 |
+
def apply_sparse_mask(self, attn_weights, tgt_len: int, src_len: int, bsz: int):
|
| 748 |
+
return attn_weights
|
| 749 |
+
|
| 750 |
+
|
| 751 |
+
def init_bert_params(module):
|
| 752 |
+
"""
|
| 753 |
+
Initialize the weights specific to the BERT Model.
|
| 754 |
+
This overrides the default initializations depending on the specified arguments.
|
| 755 |
+
1. If normal_init_linear_weights is set then weights of linear
|
| 756 |
+
layer will be initialized using the normal distribution and
|
| 757 |
+
bais will be set to the specified value.
|
| 758 |
+
2. If normal_init_embed_weights is set then weights of embedding
|
| 759 |
+
layer will be initialized using the normal distribution.
|
| 760 |
+
3. If normal_init_proj_weights is set then weights of
|
| 761 |
+
in_project_weight for MultiHeadAttention initialized using
|
| 762 |
+
the normal distribution (to be validated).
|
| 763 |
+
"""
|
| 764 |
+
|
| 765 |
+
def normal_(data):
|
| 766 |
+
# with FSDP, module params will be on CUDA, so we cast them back to CPU
|
| 767 |
+
# so that the RNG is consistent with and without FSDP
|
| 768 |
+
data.copy_(
|
| 769 |
+
data.cpu().normal_(mean=0.0, std=0.02).to(data.device)
|
| 770 |
+
)
|
| 771 |
+
|
| 772 |
+
if isinstance(module, nn.Linear):
|
| 773 |
+
normal_(module.weight.data)
|
| 774 |
+
if module.bias is not None:
|
| 775 |
+
module.bias.data.zero_()
|
| 776 |
+
if isinstance(module, nn.Embedding):
|
| 777 |
+
normal_(module.weight.data)
|
| 778 |
+
if module.padding_idx is not None:
|
| 779 |
+
module.weight.data[module.padding_idx].zero_()
|
| 780 |
+
if isinstance(module, MultiheadAttention):
|
| 781 |
+
normal_(module.q_proj.weight.data)
|
| 782 |
+
normal_(module.k_proj.weight.data)
|
| 783 |
+
normal_(module.v_proj.weight.data)
|
beats/modules.py
ADDED
|
@@ -0,0 +1,218 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# BEATs: Audio Pre-Training with Acoustic Tokenizers (https://arxiv.org/abs/2212.09058)
|
| 3 |
+
# Github source: https://github.com/microsoft/unilm/tree/master/beats
|
| 4 |
+
# Copyright (c) 2022 Microsoft
|
| 5 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 6 |
+
# Based on fairseq code bases
|
| 7 |
+
# https://github.com/pytorch/fairseq
|
| 8 |
+
# --------------------------------------------------------
|
| 9 |
+
|
| 10 |
+
import math
|
| 11 |
+
import warnings
|
| 12 |
+
import torch
|
| 13 |
+
from torch import Tensor, nn
|
| 14 |
+
import torch.nn.functional as F
|
| 15 |
+
|
| 16 |
+
|
| 17 |
+
class GradMultiply(torch.autograd.Function):
|
| 18 |
+
@staticmethod
|
| 19 |
+
def forward(ctx, x, scale):
|
| 20 |
+
ctx.scale = scale
|
| 21 |
+
res = x.new(x)
|
| 22 |
+
return res
|
| 23 |
+
|
| 24 |
+
@staticmethod
|
| 25 |
+
def backward(ctx, grad):
|
| 26 |
+
return grad * ctx.scale, None
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
class SamePad(nn.Module):
|
| 30 |
+
def __init__(self, kernel_size, causal=False):
|
| 31 |
+
super().__init__()
|
| 32 |
+
if causal:
|
| 33 |
+
self.remove = kernel_size - 1
|
| 34 |
+
else:
|
| 35 |
+
self.remove = 1 if kernel_size % 2 == 0 else 0
|
| 36 |
+
|
| 37 |
+
def forward(self, x):
|
| 38 |
+
if self.remove > 0:
|
| 39 |
+
x = x[:, :, : -self.remove]
|
| 40 |
+
return x
|
| 41 |
+
|
| 42 |
+
|
| 43 |
+
class Swish(nn.Module):
|
| 44 |
+
def __init__(self):
|
| 45 |
+
super(Swish, self).__init__()
|
| 46 |
+
self.act = torch.nn.Sigmoid()
|
| 47 |
+
|
| 48 |
+
def forward(self, x):
|
| 49 |
+
return x * self.act(x)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class GLU_Linear(nn.Module):
|
| 53 |
+
def __init__(self, input_dim, output_dim, glu_type="sigmoid", bias_in_glu=True):
|
| 54 |
+
super(GLU_Linear, self).__init__()
|
| 55 |
+
|
| 56 |
+
self.glu_type = glu_type
|
| 57 |
+
self.output_dim = output_dim
|
| 58 |
+
|
| 59 |
+
if glu_type == "sigmoid":
|
| 60 |
+
self.glu_act = torch.nn.Sigmoid()
|
| 61 |
+
elif glu_type == "swish":
|
| 62 |
+
self.glu_act = Swish()
|
| 63 |
+
elif glu_type == "relu":
|
| 64 |
+
self.glu_act = torch.nn.ReLU()
|
| 65 |
+
elif glu_type == "gelu":
|
| 66 |
+
self.glu_act = torch.nn.GELU()
|
| 67 |
+
|
| 68 |
+
if bias_in_glu:
|
| 69 |
+
self.linear = nn.Linear(input_dim, output_dim * 2, True)
|
| 70 |
+
else:
|
| 71 |
+
self.linear = nn.Linear(input_dim, output_dim * 2, False)
|
| 72 |
+
|
| 73 |
+
def forward(self, x):
|
| 74 |
+
# to be consistent with GLU_Linear, we assume the input always has the #channel (#dim) in the last dimension of the tensor, so need to switch the dimension first for 1D-Conv case
|
| 75 |
+
x = self.linear(x)
|
| 76 |
+
|
| 77 |
+
if self.glu_type == "bilinear":
|
| 78 |
+
x = (x[:, :, 0:self.output_dim] * x[:, :, self.output_dim:self.output_dim * 2])
|
| 79 |
+
else:
|
| 80 |
+
x = (x[:, :, 0:self.output_dim] * self.glu_act(x[:, :, self.output_dim:self.output_dim * 2]))
|
| 81 |
+
|
| 82 |
+
return x
|
| 83 |
+
|
| 84 |
+
|
| 85 |
+
def gelu_accurate(x):
|
| 86 |
+
if not hasattr(gelu_accurate, "_a"):
|
| 87 |
+
gelu_accurate._a = math.sqrt(2 / math.pi)
|
| 88 |
+
return (
|
| 89 |
+
0.5 * x * (1 + torch.tanh(gelu_accurate._a * (x + 0.044715 * torch.pow(x, 3))))
|
| 90 |
+
)
|
| 91 |
+
|
| 92 |
+
|
| 93 |
+
def gelu(x: torch.Tensor) -> torch.Tensor:
|
| 94 |
+
return torch.nn.functional.gelu(x.float()).type_as(x)
|
| 95 |
+
|
| 96 |
+
|
| 97 |
+
def get_activation_fn(activation: str):
|
| 98 |
+
"""Returns the activation function corresponding to `activation`"""
|
| 99 |
+
|
| 100 |
+
if activation == "relu":
|
| 101 |
+
return F.relu
|
| 102 |
+
elif activation == "gelu":
|
| 103 |
+
return gelu
|
| 104 |
+
elif activation == "gelu_fast":
|
| 105 |
+
warnings.warn(
|
| 106 |
+
"--activation-fn=gelu_fast has been renamed to gelu_accurate"
|
| 107 |
+
)
|
| 108 |
+
return gelu_accurate
|
| 109 |
+
elif activation == "gelu_accurate":
|
| 110 |
+
return gelu_accurate
|
| 111 |
+
elif activation == "tanh":
|
| 112 |
+
return torch.tanh
|
| 113 |
+
elif activation == "linear":
|
| 114 |
+
return lambda x: x
|
| 115 |
+
elif activation == "glu":
|
| 116 |
+
return lambda x: x
|
| 117 |
+
else:
|
| 118 |
+
raise RuntimeError("--activation-fn {} not supported".format(activation))
|
| 119 |
+
|
| 120 |
+
|
| 121 |
+
def quant_noise(module, p, block_size):
|
| 122 |
+
"""
|
| 123 |
+
Wraps modules and applies quantization noise to the weights for
|
| 124 |
+
subsequent quantization with Iterative Product Quantization as
|
| 125 |
+
described in "Training with Quantization Noise for Extreme Model Compression"
|
| 126 |
+
|
| 127 |
+
Args:
|
| 128 |
+
- module: nn.Module
|
| 129 |
+
- p: amount of Quantization Noise
|
| 130 |
+
- block_size: size of the blocks for subsequent quantization with iPQ
|
| 131 |
+
|
| 132 |
+
Remarks:
|
| 133 |
+
- Module weights must have the right sizes wrt the block size
|
| 134 |
+
- Only Linear, Embedding and Conv2d modules are supported for the moment
|
| 135 |
+
- For more detail on how to quantize by blocks with convolutional weights,
|
| 136 |
+
see "And the Bit Goes Down: Revisiting the Quantization of Neural Networks"
|
| 137 |
+
- We implement the simplest form of noise here as stated in the paper
|
| 138 |
+
which consists in randomly dropping blocks
|
| 139 |
+
"""
|
| 140 |
+
|
| 141 |
+
# if no quantization noise, don't register hook
|
| 142 |
+
if p <= 0:
|
| 143 |
+
return module
|
| 144 |
+
|
| 145 |
+
# supported modules
|
| 146 |
+
assert isinstance(module, (nn.Linear, nn.Embedding, nn.Conv2d))
|
| 147 |
+
|
| 148 |
+
# test whether module.weight has the right sizes wrt block_size
|
| 149 |
+
is_conv = module.weight.ndim == 4
|
| 150 |
+
|
| 151 |
+
# 2D matrix
|
| 152 |
+
if not is_conv:
|
| 153 |
+
assert (
|
| 154 |
+
module.weight.size(1) % block_size == 0
|
| 155 |
+
), "Input features must be a multiple of block sizes"
|
| 156 |
+
|
| 157 |
+
# 4D matrix
|
| 158 |
+
else:
|
| 159 |
+
# 1x1 convolutions
|
| 160 |
+
if module.kernel_size == (1, 1):
|
| 161 |
+
assert (
|
| 162 |
+
module.in_channels % block_size == 0
|
| 163 |
+
), "Input channels must be a multiple of block sizes"
|
| 164 |
+
# regular convolutions
|
| 165 |
+
else:
|
| 166 |
+
k = module.kernel_size[0] * module.kernel_size[1]
|
| 167 |
+
assert k % block_size == 0, "Kernel size must be a multiple of block size"
|
| 168 |
+
|
| 169 |
+
def _forward_pre_hook(mod, input):
|
| 170 |
+
# no noise for evaluation
|
| 171 |
+
if mod.training:
|
| 172 |
+
if not is_conv:
|
| 173 |
+
# gather weight and sizes
|
| 174 |
+
weight = mod.weight
|
| 175 |
+
in_features = weight.size(1)
|
| 176 |
+
out_features = weight.size(0)
|
| 177 |
+
|
| 178 |
+
# split weight matrix into blocks and randomly drop selected blocks
|
| 179 |
+
mask = torch.zeros(
|
| 180 |
+
in_features // block_size * out_features, device=weight.device
|
| 181 |
+
)
|
| 182 |
+
mask.bernoulli_(p)
|
| 183 |
+
mask = mask.repeat_interleave(block_size, -1).view(-1, in_features)
|
| 184 |
+
|
| 185 |
+
else:
|
| 186 |
+
# gather weight and sizes
|
| 187 |
+
weight = mod.weight
|
| 188 |
+
in_channels = mod.in_channels
|
| 189 |
+
out_channels = mod.out_channels
|
| 190 |
+
|
| 191 |
+
# split weight matrix into blocks and randomly drop selected blocks
|
| 192 |
+
if mod.kernel_size == (1, 1):
|
| 193 |
+
mask = torch.zeros(
|
| 194 |
+
int(in_channels // block_size * out_channels),
|
| 195 |
+
device=weight.device,
|
| 196 |
+
)
|
| 197 |
+
mask.bernoulli_(p)
|
| 198 |
+
mask = mask.repeat_interleave(block_size, -1).view(-1, in_channels)
|
| 199 |
+
else:
|
| 200 |
+
mask = torch.zeros(
|
| 201 |
+
weight.size(0), weight.size(1), device=weight.device
|
| 202 |
+
)
|
| 203 |
+
mask.bernoulli_(p)
|
| 204 |
+
mask = (
|
| 205 |
+
mask.unsqueeze(2)
|
| 206 |
+
.unsqueeze(3)
|
| 207 |
+
.repeat(1, 1, mod.kernel_size[0], mod.kernel_size[1])
|
| 208 |
+
)
|
| 209 |
+
|
| 210 |
+
# scale weights and apply mask
|
| 211 |
+
mask = mask.to(
|
| 212 |
+
torch.bool
|
| 213 |
+
) # x.bool() is not currently supported in TorchScript
|
| 214 |
+
s = 1 / (1 - p)
|
| 215 |
+
mod.weight.data = s * weight.masked_fill(mask, 0)
|
| 216 |
+
|
| 217 |
+
module.register_forward_pre_hook(_forward_pre_hook)
|
| 218 |
+
return module
|
beats/quantizer.py
ADDED
|
@@ -0,0 +1,215 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# --------------------------------------------------------
|
| 2 |
+
# BEATs: Audio Pre-Training with Acoustic Tokenizers (https://arxiv.org/abs/2212.09058)
|
| 3 |
+
# Github source: https://github.com/microsoft/unilm/tree/master/beats
|
| 4 |
+
# Copyright (c) 2022 Microsoft
|
| 5 |
+
# Licensed under The MIT License [see LICENSE for details]
|
| 6 |
+
# Based on VQGAN code bases
|
| 7 |
+
# https://github.com/CompVis/taming-transformers
|
| 8 |
+
# --------------------------------------------------------'
|
| 9 |
+
|
| 10 |
+
import torch
|
| 11 |
+
import torch.nn as nn
|
| 12 |
+
import torch.nn.functional as F
|
| 13 |
+
import torch.distributed as distributed
|
| 14 |
+
|
| 15 |
+
try:
|
| 16 |
+
from einops import rearrange, repeat
|
| 17 |
+
except ImportError:
|
| 18 |
+
pass
|
| 19 |
+
|
| 20 |
+
|
| 21 |
+
def l2norm(t):
|
| 22 |
+
return F.normalize(t, p=2, dim=-1)
|
| 23 |
+
|
| 24 |
+
|
| 25 |
+
def ema_inplace(moving_avg, new, decay):
|
| 26 |
+
moving_avg.data.mul_(decay).add_(new, alpha=(1 - decay))
|
| 27 |
+
|
| 28 |
+
|
| 29 |
+
def sample_vectors(samples, num):
|
| 30 |
+
num_samples, device = samples.shape[0], samples.device
|
| 31 |
+
|
| 32 |
+
if num_samples >= num:
|
| 33 |
+
indices = torch.randperm(num_samples, device=device)[:num]
|
| 34 |
+
else:
|
| 35 |
+
indices = torch.randint(0, num_samples, (num,), device=device)
|
| 36 |
+
|
| 37 |
+
return samples[indices]
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
def kmeans(samples, num_clusters, num_iters=10, use_cosine_sim=False):
|
| 41 |
+
dim, dtype, device = samples.shape[-1], samples.dtype, samples.device
|
| 42 |
+
|
| 43 |
+
means = sample_vectors(samples, num_clusters)
|
| 44 |
+
|
| 45 |
+
for _ in range(num_iters):
|
| 46 |
+
if use_cosine_sim:
|
| 47 |
+
dists = samples @ means.t()
|
| 48 |
+
else:
|
| 49 |
+
diffs = rearrange(samples, 'n d -> n () d') \
|
| 50 |
+
- rearrange(means, 'c d -> () c d')
|
| 51 |
+
dists = -(diffs ** 2).sum(dim=-1)
|
| 52 |
+
|
| 53 |
+
buckets = dists.max(dim=-1).indices
|
| 54 |
+
bins = torch.bincount(buckets, minlength=num_clusters)
|
| 55 |
+
zero_mask = bins == 0
|
| 56 |
+
bins_min_clamped = bins.masked_fill(zero_mask, 1)
|
| 57 |
+
|
| 58 |
+
new_means = buckets.new_zeros(num_clusters, dim, dtype=dtype)
|
| 59 |
+
new_means.scatter_add_(0, repeat(buckets, 'n -> n d', d=dim), samples)
|
| 60 |
+
new_means = new_means / bins_min_clamped[..., None]
|
| 61 |
+
|
| 62 |
+
if use_cosine_sim:
|
| 63 |
+
new_means = l2norm(new_means)
|
| 64 |
+
|
| 65 |
+
means = torch.where(zero_mask[..., None], means, new_means)
|
| 66 |
+
|
| 67 |
+
return means, bins
|
| 68 |
+
|
| 69 |
+
|
| 70 |
+
class EmbeddingEMA(nn.Module):
|
| 71 |
+
def __init__(self, num_tokens, codebook_dim, decay=0.99, eps=1e-5, kmeans_init=True, codebook_init_path=''):
|
| 72 |
+
super().__init__()
|
| 73 |
+
self.num_tokens = num_tokens
|
| 74 |
+
self.codebook_dim = codebook_dim
|
| 75 |
+
self.decay = decay
|
| 76 |
+
self.eps = eps
|
| 77 |
+
if codebook_init_path == '':
|
| 78 |
+
if not kmeans_init:
|
| 79 |
+
weight = torch.randn(num_tokens, codebook_dim)
|
| 80 |
+
weight = l2norm(weight)
|
| 81 |
+
else:
|
| 82 |
+
weight = torch.zeros(num_tokens, codebook_dim)
|
| 83 |
+
self.register_buffer('initted', torch.Tensor([not kmeans_init]))
|
| 84 |
+
else:
|
| 85 |
+
print(f"load init codebook weight from {codebook_init_path}")
|
| 86 |
+
codebook_ckpt_weight = torch.load(codebook_init_path, map_location='cpu')
|
| 87 |
+
weight = codebook_ckpt_weight.clone()
|
| 88 |
+
self.register_buffer('initted', torch.Tensor([True]))
|
| 89 |
+
|
| 90 |
+
self.weight = nn.Parameter(weight, requires_grad=False)
|
| 91 |
+
self.cluster_size = nn.Parameter(torch.zeros(num_tokens), requires_grad=False)
|
| 92 |
+
self.embed_avg = nn.Parameter(weight.clone(), requires_grad=False)
|
| 93 |
+
# self.register_buffer('initted', torch.Tensor([not kmeans_init]))
|
| 94 |
+
self.update = True
|
| 95 |
+
|
| 96 |
+
@torch.jit.ignore
|
| 97 |
+
def init_embed_(self, data):
|
| 98 |
+
if self.initted:
|
| 99 |
+
return
|
| 100 |
+
print("Performing Kemans init for codebook")
|
| 101 |
+
embed, cluster_size = kmeans(data, self.num_tokens, 10, use_cosine_sim=True)
|
| 102 |
+
self.weight.data.copy_(embed)
|
| 103 |
+
self.cluster_size.data.copy_(cluster_size)
|
| 104 |
+
self.initted.data.copy_(torch.Tensor([True]))
|
| 105 |
+
|
| 106 |
+
def forward(self, embed_id):
|
| 107 |
+
return F.embedding(embed_id, self.weight)
|
| 108 |
+
|
| 109 |
+
def cluster_size_ema_update(self, new_cluster_size):
|
| 110 |
+
self.cluster_size.data.mul_(self.decay).add_(new_cluster_size, alpha=1 - self.decay)
|
| 111 |
+
|
| 112 |
+
def embed_avg_ema_update(self, new_embed_avg):
|
| 113 |
+
self.embed_avg.data.mul_(self.decay).add_(new_embed_avg, alpha=1 - self.decay)
|
| 114 |
+
|
| 115 |
+
def weight_update(self, num_tokens):
|
| 116 |
+
n = self.cluster_size.sum()
|
| 117 |
+
smoothed_cluster_size = (
|
| 118 |
+
(self.cluster_size + self.eps) / (n + num_tokens * self.eps) * n
|
| 119 |
+
)
|
| 120 |
+
# normalize embedding average with smoothed cluster size
|
| 121 |
+
embed_normalized = self.embed_avg / smoothed_cluster_size.unsqueeze(1)
|
| 122 |
+
# embed_normalized = l2norm(self.embed_avg / smoothed_cluster_size.unsqueeze(1))
|
| 123 |
+
self.weight.data.copy_(embed_normalized)
|
| 124 |
+
|
| 125 |
+
|
| 126 |
+
def norm_ema_inplace(moving_avg, new, decay):
|
| 127 |
+
moving_avg.data.mul_(decay).add_(new, alpha=(1 - decay))
|
| 128 |
+
moving_avg.data.copy_(l2norm(moving_avg.data))
|
| 129 |
+
|
| 130 |
+
|
| 131 |
+
class NormEMAVectorQuantizer(nn.Module):
|
| 132 |
+
def __init__(self, n_embed, embedding_dim, beta, decay=0.99, eps=1e-5,
|
| 133 |
+
statistic_code_usage=True, kmeans_init=False, codebook_init_path=''):
|
| 134 |
+
super().__init__()
|
| 135 |
+
self.codebook_dim = embedding_dim
|
| 136 |
+
self.num_tokens = n_embed
|
| 137 |
+
self.beta = beta
|
| 138 |
+
self.decay = decay
|
| 139 |
+
|
| 140 |
+
# learnable = True if orthogonal_reg_weight > 0 else False
|
| 141 |
+
self.embedding = EmbeddingEMA(self.num_tokens, self.codebook_dim, decay, eps, kmeans_init, codebook_init_path)
|
| 142 |
+
|
| 143 |
+
self.statistic_code_usage = statistic_code_usage
|
| 144 |
+
if statistic_code_usage:
|
| 145 |
+
self.register_buffer('cluster_size', torch.zeros(n_embed))
|
| 146 |
+
if distributed.is_available() and distributed.is_initialized():
|
| 147 |
+
print("ddp is enable, so use ddp_reduce to sync the statistic_code_usage for each gpu!")
|
| 148 |
+
self.all_reduce_fn = distributed.all_reduce
|
| 149 |
+
else:
|
| 150 |
+
self.all_reduce_fn = nn.Identity()
|
| 151 |
+
|
| 152 |
+
def reset_cluster_size(self, device):
|
| 153 |
+
if self.statistic_code_usage:
|
| 154 |
+
self.register_buffer('cluster_size', torch.zeros(self.num_tokens))
|
| 155 |
+
self.cluster_size = self.cluster_size.to(device)
|
| 156 |
+
|
| 157 |
+
def forward(self, z):
|
| 158 |
+
# reshape z -> (batch, height, width, channel) and flatten
|
| 159 |
+
# z, 'b c h w -> b h w c'
|
| 160 |
+
# z = rearrange(z, 'b c h w -> b h w c')
|
| 161 |
+
# z = z.transpose(1, 2)
|
| 162 |
+
z = l2norm(z)
|
| 163 |
+
z_flattened = z.reshape(-1, self.codebook_dim)
|
| 164 |
+
|
| 165 |
+
self.embedding.init_embed_(z_flattened)
|
| 166 |
+
|
| 167 |
+
d = z_flattened.pow(2).sum(dim=1, keepdim=True) + \
|
| 168 |
+
self.embedding.weight.pow(2).sum(dim=1) - 2 * \
|
| 169 |
+
torch.einsum('bd,nd->bn', z_flattened, self.embedding.weight) # 'n d -> d n'
|
| 170 |
+
|
| 171 |
+
encoding_indices = torch.argmin(d, dim=1)
|
| 172 |
+
|
| 173 |
+
z_q = self.embedding(encoding_indices).view(z.shape)
|
| 174 |
+
|
| 175 |
+
encodings = F.one_hot(encoding_indices, self.num_tokens).type(z.dtype)
|
| 176 |
+
|
| 177 |
+
if not self.training:
|
| 178 |
+
with torch.no_grad():
|
| 179 |
+
cluster_size = encodings.sum(0)
|
| 180 |
+
self.all_reduce_fn(cluster_size)
|
| 181 |
+
ema_inplace(self.cluster_size, cluster_size, self.decay)
|
| 182 |
+
|
| 183 |
+
if self.training and self.embedding.update:
|
| 184 |
+
# EMA cluster size
|
| 185 |
+
|
| 186 |
+
bins = encodings.sum(0)
|
| 187 |
+
self.all_reduce_fn(bins)
|
| 188 |
+
|
| 189 |
+
# self.embedding.cluster_size_ema_update(bins)
|
| 190 |
+
ema_inplace(self.cluster_size, bins, self.decay)
|
| 191 |
+
|
| 192 |
+
zero_mask = (bins == 0)
|
| 193 |
+
bins = bins.masked_fill(zero_mask, 1.)
|
| 194 |
+
|
| 195 |
+
embed_sum = z_flattened.t() @ encodings
|
| 196 |
+
self.all_reduce_fn(embed_sum)
|
| 197 |
+
|
| 198 |
+
embed_normalized = (embed_sum / bins.unsqueeze(0)).t()
|
| 199 |
+
embed_normalized = l2norm(embed_normalized)
|
| 200 |
+
|
| 201 |
+
embed_normalized = torch.where(zero_mask[..., None], self.embedding.weight,
|
| 202 |
+
embed_normalized)
|
| 203 |
+
norm_ema_inplace(self.embedding.weight, embed_normalized, self.decay)
|
| 204 |
+
|
| 205 |
+
# compute loss for embedding
|
| 206 |
+
loss = self.beta * F.mse_loss(z_q.detach(), z)
|
| 207 |
+
|
| 208 |
+
# preserve gradients
|
| 209 |
+
z_q = z + (z_q - z).detach()
|
| 210 |
+
|
| 211 |
+
# reshape back to match original input shape
|
| 212 |
+
# z_q, 'b h w c -> b c h w'
|
| 213 |
+
# z_q = rearrange(z_q, 'b h w c -> b c h w')
|
| 214 |
+
# z_q = z_q.transpose(1, 2)
|
| 215 |
+
return z_q, loss, encoding_indices
|
cli_inference.py
ADDED
|
@@ -0,0 +1,53 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (2023) Tsinghua University, Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import argparse
|
| 17 |
+
from model import SALMONN
|
| 18 |
+
|
| 19 |
+
if __name__ == "__main__":
|
| 20 |
+
|
| 21 |
+
parser = argparse.ArgumentParser()
|
| 22 |
+
parser.add_argument("--device", type=str, default="cuda:0")
|
| 23 |
+
parser.add_argument("--ckpt_path", type=str, default=None)
|
| 24 |
+
parser.add_argument("--whisper_path", type=str, default=None)
|
| 25 |
+
parser.add_argument("--beats_path", type=str, default=None)
|
| 26 |
+
parser.add_argument("--vicuna_path", type=str, default=None)
|
| 27 |
+
parser.add_argument("--lora_alpha", type=int, default=32)
|
| 28 |
+
parser.add_argument("--low_resource", action='store_true', default=False)
|
| 29 |
+
parser.add_argument("--debug", action="store_true", default=False)
|
| 30 |
+
|
| 31 |
+
args = parser.parse_args()
|
| 32 |
+
|
| 33 |
+
model = SALMONN(
|
| 34 |
+
ckpt=args.ckpt_path,
|
| 35 |
+
whisper_path=args.whisper_path,
|
| 36 |
+
beats_path=args.beats_path,
|
| 37 |
+
vicuna_path=args.vicuna_path,
|
| 38 |
+
lora_alpha=args.lora_alpha,
|
| 39 |
+
low_resource=args.low_resource
|
| 40 |
+
)
|
| 41 |
+
model.to(args.device)
|
| 42 |
+
model.eval()
|
| 43 |
+
while True:
|
| 44 |
+
print("=====================================")
|
| 45 |
+
wav_path = input("Your Wav Path:\n")
|
| 46 |
+
prompt = input("Your Prompt:\n")
|
| 47 |
+
try:
|
| 48 |
+
print("Output:")
|
| 49 |
+
print(model.generate(wav_path, prompt=prompt)[0])
|
| 50 |
+
except Exception as e:
|
| 51 |
+
print(e)
|
| 52 |
+
if args.debug:
|
| 53 |
+
import pdb; pdb.set_trace()
|
model.py
ADDED
|
@@ -0,0 +1,251 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (2023) Tsinghua University, Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
|
| 16 |
+
import torch
|
| 17 |
+
import soundfile as sf
|
| 18 |
+
import torch.nn as nn
|
| 19 |
+
import torch.nn.functional as F
|
| 20 |
+
from peft import LoraConfig, TaskType, get_peft_model
|
| 21 |
+
from transformers import (
|
| 22 |
+
WhisperFeatureExtractor,
|
| 23 |
+
WhisperModel,
|
| 24 |
+
LlamaForCausalLM,
|
| 25 |
+
LlamaTokenizer
|
| 26 |
+
)
|
| 27 |
+
import librosa
|
| 28 |
+
from beats.BEATs import BEATsConfig, BEATs
|
| 29 |
+
from qformer.Qformer import BertConfig, BertLMHeadModel
|
| 30 |
+
|
| 31 |
+
class SALMONN(nn.Module):
|
| 32 |
+
def __init__(
|
| 33 |
+
self,
|
| 34 |
+
ckpt,
|
| 35 |
+
whisper_path,
|
| 36 |
+
beats_path,
|
| 37 |
+
vicuna_path,
|
| 38 |
+
speech_qformer_token_num=1,
|
| 39 |
+
speech_qformer_layer=2,
|
| 40 |
+
lora=True,
|
| 41 |
+
lora_alpha=32,
|
| 42 |
+
lora_rank=8,
|
| 43 |
+
lora_dropout=0.1,
|
| 44 |
+
second_per_frame=0.333333,
|
| 45 |
+
second_stride=0.333333,
|
| 46 |
+
low_resource=False
|
| 47 |
+
):
|
| 48 |
+
|
| 49 |
+
super().__init__()
|
| 50 |
+
|
| 51 |
+
# feature_extractor
|
| 52 |
+
self.feature_extractor = WhisperFeatureExtractor.from_pretrained(whisper_path)
|
| 53 |
+
|
| 54 |
+
# whisper
|
| 55 |
+
self.speech_encoder = WhisperModel.from_pretrained(whisper_path).encoder
|
| 56 |
+
self.ln_speech = nn.LayerNorm(self.speech_encoder.config.d_model)
|
| 57 |
+
|
| 58 |
+
# beats
|
| 59 |
+
self.beats_ckpt = beats_path
|
| 60 |
+
beats_checkpoint = torch.load(self.beats_ckpt, map_location='cpu')
|
| 61 |
+
beats_cfg = BEATsConfig(beats_checkpoint['cfg'])
|
| 62 |
+
beats = BEATs(beats_cfg)
|
| 63 |
+
beats.load_state_dict(beats_checkpoint['model'])
|
| 64 |
+
self.beats = beats
|
| 65 |
+
self.ln_audio = nn.LayerNorm(self.beats.cfg.encoder_embed_dim)
|
| 66 |
+
for name, param in self.beats.named_parameters():
|
| 67 |
+
param.requires_grad = False
|
| 68 |
+
self.beats.eval()
|
| 69 |
+
|
| 70 |
+
# init speech Qformer
|
| 71 |
+
self.speech_Qformer, self.speech_query_tokens = self.init_speech_Qformer(
|
| 72 |
+
speech_qformer_token_num,
|
| 73 |
+
self.speech_encoder.config.d_model + self.beats.cfg.encoder_embed_dim,
|
| 74 |
+
speech_qformer_layer,
|
| 75 |
+
)
|
| 76 |
+
self.second_per_frame = second_per_frame
|
| 77 |
+
self.second_stride = second_stride
|
| 78 |
+
|
| 79 |
+
# vicuna
|
| 80 |
+
if not low_resource:
|
| 81 |
+
self.llama_model = LlamaForCausalLM.from_pretrained(
|
| 82 |
+
vicuna_path,
|
| 83 |
+
torch_dtype=torch.float16,
|
| 84 |
+
)
|
| 85 |
+
else:
|
| 86 |
+
self.llama_model = LlamaForCausalLM.from_pretrained(
|
| 87 |
+
vicuna_path,
|
| 88 |
+
torch_dtype=torch.float16,
|
| 89 |
+
load_in_8bit=True,
|
| 90 |
+
device_map={'': 0}
|
| 91 |
+
)
|
| 92 |
+
|
| 93 |
+
# lora
|
| 94 |
+
self.lora = lora
|
| 95 |
+
if lora:
|
| 96 |
+
target_modules = None
|
| 97 |
+
self.peft_config = LoraConfig(
|
| 98 |
+
task_type=TaskType.CAUSAL_LM,
|
| 99 |
+
inference_mode=True,
|
| 100 |
+
r=lora_rank,
|
| 101 |
+
lora_alpha=lora_alpha,
|
| 102 |
+
lora_dropout=lora_dropout,
|
| 103 |
+
target_modules=target_modules,
|
| 104 |
+
)
|
| 105 |
+
self.llama_model = get_peft_model(self.llama_model, self.peft_config)
|
| 106 |
+
|
| 107 |
+
# tokenizer
|
| 108 |
+
self.llama_tokenizer = LlamaTokenizer.from_pretrained(vicuna_path, use_fast=False)
|
| 109 |
+
self.llama_tokenizer.add_special_tokens({'pad_token': '[PAD]'})
|
| 110 |
+
self.llama_tokenizer.padding_side = "right"
|
| 111 |
+
|
| 112 |
+
# proj
|
| 113 |
+
self.speech_llama_proj = nn.Linear(
|
| 114 |
+
self.speech_Qformer.config.hidden_size, self.llama_model.config.hidden_size)
|
| 115 |
+
|
| 116 |
+
# load ckpt
|
| 117 |
+
ckpt_dict = torch.load(ckpt)['model']
|
| 118 |
+
self.load_state_dict(ckpt_dict, strict=False)
|
| 119 |
+
|
| 120 |
+
def generate(
|
| 121 |
+
self,
|
| 122 |
+
wav_path,
|
| 123 |
+
prompt,
|
| 124 |
+
prompt_pattern="USER: <Speech><SpeechHere></Speech> {}\nASSISTANT:",
|
| 125 |
+
device='cuda:0',
|
| 126 |
+
max_length=150,
|
| 127 |
+
num_beams=4,
|
| 128 |
+
do_sample=True,
|
| 129 |
+
min_length=1,
|
| 130 |
+
top_p=0.9,
|
| 131 |
+
repetition_penalty=1.0,
|
| 132 |
+
length_penalty=1.0,
|
| 133 |
+
temperature=1.0,
|
| 134 |
+
):
|
| 135 |
+
# read wav
|
| 136 |
+
wav, sr = sf.read(wav_path)
|
| 137 |
+
if len(wav.shape) == 2:
|
| 138 |
+
wav = wav[:, 0]
|
| 139 |
+
if len(wav) > 30 * sr:
|
| 140 |
+
wav = wav[: 30 * sr]
|
| 141 |
+
if sr != 16000:
|
| 142 |
+
wav = librosa.resample(wav, orig_sr=sr, target_sr=16000, res_type="fft")
|
| 143 |
+
|
| 144 |
+
# whisper
|
| 145 |
+
spectrogram = self.feature_extractor(wav, return_tensors="pt", sampling_rate=16000).input_features.to(device) # [1, 80, 3000]
|
| 146 |
+
speech_embeds = self.speech_encoder(spectrogram, return_dict=True).last_hidden_state
|
| 147 |
+
|
| 148 |
+
# beats
|
| 149 |
+
raw_wav = torch.from_numpy(wav).to(device).unsqueeze(0)
|
| 150 |
+
audio_padding_mask = torch.zeros(raw_wav.shape, device=device).bool()
|
| 151 |
+
audio_embeds, _ = self.beats.extract_features(raw_wav, padding_mask=audio_padding_mask, feature_only=True)
|
| 152 |
+
|
| 153 |
+
# auditory embeds
|
| 154 |
+
speech_embeds = self.ln_speech(speech_embeds)
|
| 155 |
+
audio_embeds = self.ln_audio(audio_embeds)
|
| 156 |
+
audio_embeds = F.pad(audio_embeds, (0, 0, 0, speech_embeds.size(1) - audio_embeds.size(1)))
|
| 157 |
+
speech_embeds = torch.cat([speech_embeds, audio_embeds], dim=-1)
|
| 158 |
+
|
| 159 |
+
# split frames
|
| 160 |
+
B, T, C = speech_embeds.shape
|
| 161 |
+
kernel = round(T * self.second_per_frame / 30.0)
|
| 162 |
+
stride = round(T * self.second_stride / 30.0)
|
| 163 |
+
kernel = (1, kernel)
|
| 164 |
+
stride = (1, stride)
|
| 165 |
+
speech_embeds_tr = speech_embeds.transpose(1, 2).unsqueeze(2)
|
| 166 |
+
speech_embeds_overlap = F.unfold(speech_embeds_tr, kernel_size=kernel, dilation=1, padding=0, stride=stride)
|
| 167 |
+
_, _, L = speech_embeds_overlap.shape
|
| 168 |
+
speech_embeds_overlap = speech_embeds_overlap.view(B, -1, kernel[1], L)
|
| 169 |
+
speech_embeds_overlap = torch.permute(speech_embeds_overlap, [0, 3, 2, 1])
|
| 170 |
+
speech_embeds = speech_embeds_overlap.reshape(-1, kernel[1], C)
|
| 171 |
+
speech_atts = torch.ones(speech_embeds.size()[:-1], dtype=torch.long, device=speech_embeds.device)
|
| 172 |
+
|
| 173 |
+
# Qformer
|
| 174 |
+
query_tokens = self.speech_query_tokens.expand(speech_embeds.shape[0], -1, -1)
|
| 175 |
+
query_output = self.speech_Qformer.bert(
|
| 176 |
+
query_embeds=query_tokens,
|
| 177 |
+
encoder_hidden_states=speech_embeds,
|
| 178 |
+
encoder_attention_mask=speech_atts,
|
| 179 |
+
return_dict=True,
|
| 180 |
+
)
|
| 181 |
+
speech_embeds = self.speech_llama_proj(query_output.last_hidden_state)
|
| 182 |
+
speech_embeds = speech_embeds.view(B, -1, speech_embeds.size(2)).contiguous()
|
| 183 |
+
speech_atts = torch.ones(speech_embeds.size()[:-1], dtype=torch.long).to(speech_embeds.device)
|
| 184 |
+
|
| 185 |
+
# USER: <Speech>speech_embeds<Speech> prompt\nASSISTANT:
|
| 186 |
+
embed_tokens = self.llama_model.model.model.embed_tokens if self.lora else self.llama_model.model.embed_tokens
|
| 187 |
+
prompt_left, prompts_right = prompt_pattern.format(prompt).split('<SpeechHere>')
|
| 188 |
+
prompt_left_ids = self.llama_tokenizer(
|
| 189 |
+
prompt_left,
|
| 190 |
+
return_tensors="pt",
|
| 191 |
+
add_special_tokens=False
|
| 192 |
+
).to(speech_embeds.device).input_ids
|
| 193 |
+
prompt_left_embeds = embed_tokens(prompt_left_ids)
|
| 194 |
+
prompt_right_ids = self.llama_tokenizer(
|
| 195 |
+
prompts_right,
|
| 196 |
+
return_tensors="pt",
|
| 197 |
+
add_special_tokens=False
|
| 198 |
+
).to(speech_embeds.device).input_ids
|
| 199 |
+
prompt_right_embeds = embed_tokens(prompt_right_ids)
|
| 200 |
+
|
| 201 |
+
bos_embeds = self.llama_model.model.embed_tokens(
|
| 202 |
+
torch.ones(
|
| 203 |
+
[1, 1],
|
| 204 |
+
dtype=torch.long,
|
| 205 |
+
device=device,
|
| 206 |
+
) * self.llama_tokenizer.bos_token_id
|
| 207 |
+
) if not self.lora else self.llama_model.model.model.embed_tokens(
|
| 208 |
+
torch.ones(
|
| 209 |
+
[1, 1],
|
| 210 |
+
dtype=torch.long,
|
| 211 |
+
device=device,
|
| 212 |
+
) * self.llama_tokenizer.bos_token_id
|
| 213 |
+
)
|
| 214 |
+
|
| 215 |
+
embeds = torch.cat([bos_embeds, prompt_left_embeds, speech_embeds, prompt_right_embeds], dim=1)
|
| 216 |
+
atts = torch.ones(embeds.size()[:-1], dtype=torch.long).to(embeds.device)
|
| 217 |
+
|
| 218 |
+
# generate
|
| 219 |
+
output = self.llama_model.generate(
|
| 220 |
+
inputs_embeds=embeds,
|
| 221 |
+
max_length=max_length,
|
| 222 |
+
num_beams=num_beams,
|
| 223 |
+
do_sample=do_sample,
|
| 224 |
+
min_length=min_length,
|
| 225 |
+
top_p=top_p,
|
| 226 |
+
repetition_penalty=repetition_penalty,
|
| 227 |
+
length_penalty=length_penalty,
|
| 228 |
+
temperature=temperature,
|
| 229 |
+
attention_mask=atts,
|
| 230 |
+
bos_token_id=self.llama_tokenizer.bos_token_id,
|
| 231 |
+
eos_token_id=self.llama_tokenizer.eos_token_id,
|
| 232 |
+
pad_token_id=self.llama_tokenizer.pad_token_id
|
| 233 |
+
)
|
| 234 |
+
|
| 235 |
+
output_text = self.llama_tokenizer.batch_decode(output, add_special_tokens=False, skip_special_tokens=True)
|
| 236 |
+
|
| 237 |
+
return output_text
|
| 238 |
+
|
| 239 |
+
def init_speech_Qformer(self, num_query_token, speech_width, num_hidden_layers=2):
|
| 240 |
+
encoder_config = BertConfig()
|
| 241 |
+
encoder_config.num_hidden_layers = num_hidden_layers
|
| 242 |
+
encoder_config.encoder_width = speech_width
|
| 243 |
+
encoder_config.add_cross_attention = True
|
| 244 |
+
encoder_config.cross_attention_freq = 1
|
| 245 |
+
encoder_config.query_length = num_query_token
|
| 246 |
+
Qformer = BertLMHeadModel(config=encoder_config)
|
| 247 |
+
query_tokens = nn.Parameter(
|
| 248 |
+
torch.zeros(1, num_query_token, encoder_config.hidden_size)
|
| 249 |
+
)
|
| 250 |
+
query_tokens.data.normal_(mean=0.0, std=encoder_config.initializer_range)
|
| 251 |
+
return Qformer, query_tokens
|
other_third-party_licenses/LICENSE_vicuna
ADDED
|
@@ -0,0 +1,201 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
Apache License
|
| 2 |
+
Version 2.0, January 2004
|
| 3 |
+
http://www.apache.org/licenses/
|
| 4 |
+
|
| 5 |
+
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
|
| 6 |
+
|
| 7 |
+
1. Definitions.
|
| 8 |
+
|
| 9 |
+
"License" shall mean the terms and conditions for use, reproduction,
|
| 10 |
+
and distribution as defined by Sections 1 through 9 of this document.
|
| 11 |
+
|
| 12 |
+
"Licensor" shall mean the copyright owner or entity authorized by
|
| 13 |
+
the copyright owner that is granting the License.
|
| 14 |
+
|
| 15 |
+
"Legal Entity" shall mean the union of the acting entity and all
|
| 16 |
+
other entities that control, are controlled by, or are under common
|
| 17 |
+
control with that entity. For the purposes of this definition,
|
| 18 |
+
"control" means (i) the power, direct or indirect, to cause the
|
| 19 |
+
direction or management of such entity, whether by contract or
|
| 20 |
+
otherwise, or (ii) ownership of fifty percent (50%) or more of the
|
| 21 |
+
outstanding shares, or (iii) beneficial ownership of such entity.
|
| 22 |
+
|
| 23 |
+
"You" (or "Your") shall mean an individual or Legal Entity
|
| 24 |
+
exercising permissions granted by this License.
|
| 25 |
+
|
| 26 |
+
"Source" form shall mean the preferred form for making modifications,
|
| 27 |
+
including but not limited to software source code, documentation
|
| 28 |
+
source, and configuration files.
|
| 29 |
+
|
| 30 |
+
"Object" form shall mean any form resulting from mechanical
|
| 31 |
+
transformation or translation of a Source form, including but
|
| 32 |
+
not limited to compiled object code, generated documentation,
|
| 33 |
+
and conversions to other media types.
|
| 34 |
+
|
| 35 |
+
"Work" shall mean the work of authorship, whether in Source or
|
| 36 |
+
Object form, made available under the License, as indicated by a
|
| 37 |
+
copyright notice that is included in or attached to the work
|
| 38 |
+
(an example is provided in the Appendix below).
|
| 39 |
+
|
| 40 |
+
"Derivative Works" shall mean any work, whether in Source or Object
|
| 41 |
+
form, that is based on (or derived from) the Work and for which the
|
| 42 |
+
editorial revisions, annotations, elaborations, or other modifications
|
| 43 |
+
represent, as a whole, an original work of authorship. For the purposes
|
| 44 |
+
of this License, Derivative Works shall not include works that remain
|
| 45 |
+
separable from, or merely link (or bind by name) to the interfaces of,
|
| 46 |
+
the Work and Derivative Works thereof.
|
| 47 |
+
|
| 48 |
+
"Contribution" shall mean any work of authorship, including
|
| 49 |
+
the original version of the Work and any modifications or additions
|
| 50 |
+
to that Work or Derivative Works thereof, that is intentionally
|
| 51 |
+
submitted to Licensor for inclusion in the Work by the copyright owner
|
| 52 |
+
or by an individual or Legal Entity authorized to submit on behalf of
|
| 53 |
+
the copyright owner. For the purposes of this definition, "submitted"
|
| 54 |
+
means any form of electronic, verbal, or written communication sent
|
| 55 |
+
to the Licensor or its representatives, including but not limited to
|
| 56 |
+
communication on electronic mailing lists, source code control systems,
|
| 57 |
+
and issue tracking systems that are managed by, or on behalf of, the
|
| 58 |
+
Licensor for the purpose of discussing and improving the Work, but
|
| 59 |
+
excluding communication that is conspicuously marked or otherwise
|
| 60 |
+
designated in writing by the copyright owner as "Not a Contribution."
|
| 61 |
+
|
| 62 |
+
"Contributor" shall mean Licensor and any individual or Legal Entity
|
| 63 |
+
on behalf of whom a Contribution has been received by Licensor and
|
| 64 |
+
subsequently incorporated within the Work.
|
| 65 |
+
|
| 66 |
+
2. Grant of Copyright License. Subject to the terms and conditions of
|
| 67 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 68 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 69 |
+
copyright license to reproduce, prepare Derivative Works of,
|
| 70 |
+
publicly display, publicly perform, sublicense, and distribute the
|
| 71 |
+
Work and such Derivative Works in Source or Object form.
|
| 72 |
+
|
| 73 |
+
3. Grant of Patent License. Subject to the terms and conditions of
|
| 74 |
+
this License, each Contributor hereby grants to You a perpetual,
|
| 75 |
+
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
|
| 76 |
+
(except as stated in this section) patent license to make, have made,
|
| 77 |
+
use, offer to sell, sell, import, and otherwise transfer the Work,
|
| 78 |
+
where such license applies only to those patent claims licensable
|
| 79 |
+
by such Contributor that are necessarily infringed by their
|
| 80 |
+
Contribution(s) alone or by combination of their Contribution(s)
|
| 81 |
+
with the Work to which such Contribution(s) was submitted. If You
|
| 82 |
+
institute patent litigation against any entity (including a
|
| 83 |
+
cross-claim or counterclaim in a lawsuit) alleging that the Work
|
| 84 |
+
or a Contribution incorporated within the Work constitutes direct
|
| 85 |
+
or contributory patent infringement, then any patent licenses
|
| 86 |
+
granted to You under this License for that Work shall terminate
|
| 87 |
+
as of the date such litigation is filed.
|
| 88 |
+
|
| 89 |
+
4. Redistribution. You may reproduce and distribute copies of the
|
| 90 |
+
Work or Derivative Works thereof in any medium, with or without
|
| 91 |
+
modifications, and in Source or Object form, provided that You
|
| 92 |
+
meet the following conditions:
|
| 93 |
+
|
| 94 |
+
(a) You must give any other recipients of the Work or
|
| 95 |
+
Derivative Works a copy of this License; and
|
| 96 |
+
|
| 97 |
+
(b) You must cause any modified files to carry prominent notices
|
| 98 |
+
stating that You changed the files; and
|
| 99 |
+
|
| 100 |
+
(c) You must retain, in the Source form of any Derivative Works
|
| 101 |
+
that You distribute, all copyright, patent, trademark, and
|
| 102 |
+
attribution notices from the Source form of the Work,
|
| 103 |
+
excluding those notices that do not pertain to any part of
|
| 104 |
+
the Derivative Works; and
|
| 105 |
+
|
| 106 |
+
(d) If the Work includes a "NOTICE" text file as part of its
|
| 107 |
+
distribution, then any Derivative Works that You distribute must
|
| 108 |
+
include a readable copy of the attribution notices contained
|
| 109 |
+
within such NOTICE file, excluding those notices that do not
|
| 110 |
+
pertain to any part of the Derivative Works, in at least one
|
| 111 |
+
of the following places: within a NOTICE text file distributed
|
| 112 |
+
as part of the Derivative Works; within the Source form or
|
| 113 |
+
documentation, if provided along with the Derivative Works; or,
|
| 114 |
+
within a display generated by the Derivative Works, if and
|
| 115 |
+
wherever such third-party notices normally appear. The contents
|
| 116 |
+
of the NOTICE file are for informational purposes only and
|
| 117 |
+
do not modify the License. You may add Your own attribution
|
| 118 |
+
notices within Derivative Works that You distribute, alongside
|
| 119 |
+
or as an addendum to the NOTICE text from the Work, provided
|
| 120 |
+
that such additional attribution notices cannot be construed
|
| 121 |
+
as modifying the License.
|
| 122 |
+
|
| 123 |
+
You may add Your own copyright statement to Your modifications and
|
| 124 |
+
may provide additional or different license terms and conditions
|
| 125 |
+
for use, reproduction, or distribution of Your modifications, or
|
| 126 |
+
for any such Derivative Works as a whole, provided Your use,
|
| 127 |
+
reproduction, and distribution of the Work otherwise complies with
|
| 128 |
+
the conditions stated in this License.
|
| 129 |
+
|
| 130 |
+
5. Submission of Contributions. Unless You explicitly state otherwise,
|
| 131 |
+
any Contribution intentionally submitted for inclusion in the Work
|
| 132 |
+
by You to the Licensor shall be under the terms and conditions of
|
| 133 |
+
this License, without any additional terms or conditions.
|
| 134 |
+
Notwithstanding the above, nothing herein shall supersede or modify
|
| 135 |
+
the terms of any separate license agreement you may have executed
|
| 136 |
+
with Licensor regarding such Contributions.
|
| 137 |
+
|
| 138 |
+
6. Trademarks. This License does not grant permission to use the trade
|
| 139 |
+
names, trademarks, service marks, or product names of the Licensor,
|
| 140 |
+
except as required for reasonable and customary use in describing the
|
| 141 |
+
origin of the Work and reproducing the content of the NOTICE file.
|
| 142 |
+
|
| 143 |
+
7. Disclaimer of Warranty. Unless required by applicable law or
|
| 144 |
+
agreed to in writing, Licensor provides the Work (and each
|
| 145 |
+
Contributor provides its Contributions) on an "AS IS" BASIS,
|
| 146 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
|
| 147 |
+
implied, including, without limitation, any warranties or conditions
|
| 148 |
+
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
|
| 149 |
+
PARTICULAR PURPOSE. You are solely responsible for determining the
|
| 150 |
+
appropriateness of using or redistributing the Work and assume any
|
| 151 |
+
risks associated with Your exercise of permissions under this License.
|
| 152 |
+
|
| 153 |
+
8. Limitation of Liability. In no event and under no legal theory,
|
| 154 |
+
whether in tort (including negligence), contract, or otherwise,
|
| 155 |
+
unless required by applicable law (such as deliberate and grossly
|
| 156 |
+
negligent acts) or agreed to in writing, shall any Contributor be
|
| 157 |
+
liable to You for damages, including any direct, indirect, special,
|
| 158 |
+
incidental, or consequential damages of any character arising as a
|
| 159 |
+
result of this License or out of the use or inability to use the
|
| 160 |
+
Work (including but not limited to damages for loss of goodwill,
|
| 161 |
+
work stoppage, computer failure or malfunction, or any and all
|
| 162 |
+
other commercial damages or losses), even if such Contributor
|
| 163 |
+
has been advised of the possibility of such damages.
|
| 164 |
+
|
| 165 |
+
9. Accepting Warranty or Additional Liability. While redistributing
|
| 166 |
+
the Work or Derivative Works thereof, You may choose to offer,
|
| 167 |
+
and charge a fee for, acceptance of support, warranty, indemnity,
|
| 168 |
+
or other liability obligations and/or rights consistent with this
|
| 169 |
+
License. However, in accepting such obligations, You may act only
|
| 170 |
+
on Your own behalf and on Your sole responsibility, not on behalf
|
| 171 |
+
of any other Contributor, and only if You agree to indemnify,
|
| 172 |
+
defend, and hold each Contributor harmless for any liability
|
| 173 |
+
incurred by, or claims asserted against, such Contributor by reason
|
| 174 |
+
of your accepting any such warranty or additional liability.
|
| 175 |
+
|
| 176 |
+
END OF TERMS AND CONDITIONS
|
| 177 |
+
|
| 178 |
+
APPENDIX: How to apply the Apache License to your work.
|
| 179 |
+
|
| 180 |
+
To apply the Apache License to your work, attach the following
|
| 181 |
+
boilerplate notice, with the fields enclosed by brackets "[]"
|
| 182 |
+
replaced with your own identifying information. (Don't include
|
| 183 |
+
the brackets!) The text should be enclosed in the appropriate
|
| 184 |
+
comment syntax for the file format. We also recommend that a
|
| 185 |
+
file or class name and description of purpose be included on the
|
| 186 |
+
same "printed page" as the copyright notice for easier
|
| 187 |
+
identification within third-party archives.
|
| 188 |
+
|
| 189 |
+
Copyright [yyyy] [name of copyright owner]
|
| 190 |
+
|
| 191 |
+
Licensed under the Apache License, Version 2.0 (the "License");
|
| 192 |
+
you may not use this file except in compliance with the License.
|
| 193 |
+
You may obtain a copy of the License at
|
| 194 |
+
|
| 195 |
+
http://www.apache.org/licenses/LICENSE-2.0
|
| 196 |
+
|
| 197 |
+
Unless required by applicable law or agreed to in writing, software
|
| 198 |
+
distributed under the License is distributed on an "AS IS" BASIS,
|
| 199 |
+
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 200 |
+
See the License for the specific language governing permissions and
|
| 201 |
+
limitations under the License.
|
other_third-party_licenses/LICENSE_whisper
ADDED
|
@@ -0,0 +1,21 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
MIT License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 OpenAI
|
| 4 |
+
|
| 5 |
+
Permission is hereby granted, free of charge, to any person obtaining a copy
|
| 6 |
+
of this software and associated documentation files (the "Software"), to deal
|
| 7 |
+
in the Software without restriction, including without limitation the rights
|
| 8 |
+
to use, copy, modify, merge, publish, distribute, sublicense, and/or sell
|
| 9 |
+
copies of the Software, and to permit persons to whom the Software is
|
| 10 |
+
furnished to do so, subject to the following conditions:
|
| 11 |
+
|
| 12 |
+
The above copyright notice and this permission notice shall be included in all
|
| 13 |
+
copies or substantial portions of the Software.
|
| 14 |
+
|
| 15 |
+
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
| 16 |
+
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
| 17 |
+
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
| 18 |
+
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
| 19 |
+
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
|
| 20 |
+
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
|
| 21 |
+
SOFTWARE.
|
qformer/LICENSE_Lavis
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2022 Salesforce, Inc.
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of Salesforce.com nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
qformer/LICENSE_MiniGPT4
ADDED
|
@@ -0,0 +1,14 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright 2023 Deyao Zhu
|
| 4 |
+
All rights reserved.
|
| 5 |
+
|
| 6 |
+
Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer.
|
| 9 |
+
|
| 10 |
+
2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other materials provided with the distribution.
|
| 11 |
+
|
| 12 |
+
3. Neither the name of the copyright holder nor the names of its contributors may be used to endorse or promote products derived from this software without specific prior written permission.
|
| 13 |
+
|
| 14 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
qformer/LICENSE_VideoLlama
ADDED
|
@@ -0,0 +1,28 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
BSD 3-Clause License
|
| 2 |
+
|
| 3 |
+
Copyright (c) 2023, Multilingual NLP Team at Alibaba DAMO Academy
|
| 4 |
+
|
| 5 |
+
Redistribution and use in source and binary forms, with or without
|
| 6 |
+
modification, are permitted provided that the following conditions are met:
|
| 7 |
+
|
| 8 |
+
1. Redistributions of source code must retain the above copyright notice, this
|
| 9 |
+
list of conditions and the following disclaimer.
|
| 10 |
+
|
| 11 |
+
2. Redistributions in binary form must reproduce the above copyright notice,
|
| 12 |
+
this list of conditions and the following disclaimer in the documentation
|
| 13 |
+
and/or other materials provided with the distribution.
|
| 14 |
+
|
| 15 |
+
3. Neither the name of the copyright holder nor the names of its
|
| 16 |
+
contributors may be used to endorse or promote products derived from
|
| 17 |
+
this software without specific prior written permission.
|
| 18 |
+
|
| 19 |
+
THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS"
|
| 20 |
+
AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
|
| 21 |
+
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE
|
| 22 |
+
DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE
|
| 23 |
+
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
|
| 24 |
+
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR
|
| 25 |
+
SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER
|
| 26 |
+
CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
|
| 27 |
+
OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE
|
| 28 |
+
OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
|
qformer/Qformer.py
ADDED
|
@@ -0,0 +1,1217 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
"""
|
| 2 |
+
Adapted from salesforce@LAVIS. Below is the original copyright:
|
| 3 |
+
* Copyright (c) 2023, salesforce.com, inc.
|
| 4 |
+
* All rights reserved.
|
| 5 |
+
* SPDX-License-Identifier: BSD-3-Clause
|
| 6 |
+
* For full license text, see LICENSE.txt file in the repo root or https://opensource.org/licenses/BSD-3-Clause
|
| 7 |
+
* By Junnan Li
|
| 8 |
+
* Based on hf.rst.imde base
|
| 9 |
+
* https://github.com/huggingface/transformers/blob/v4.15.0/src/transformers/models/bert
|
| 10 |
+
"""
|
| 11 |
+
|
| 12 |
+
import math
|
| 13 |
+
import os
|
| 14 |
+
import warnings
|
| 15 |
+
from dataclasses import dataclass
|
| 16 |
+
from typing import Optional, Tuple, Dict, Any
|
| 17 |
+
|
| 18 |
+
import torch
|
| 19 |
+
from torch import Tensor, device, dtype, nn
|
| 20 |
+
import torch.utils.checkpoint
|
| 21 |
+
from torch import nn
|
| 22 |
+
from torch.nn import CrossEntropyLoss
|
| 23 |
+
import torch.nn.functional as F
|
| 24 |
+
|
| 25 |
+
from transformers.activations import ACT2FN
|
| 26 |
+
from transformers.file_utils import (
|
| 27 |
+
ModelOutput,
|
| 28 |
+
)
|
| 29 |
+
from transformers.modeling_outputs import (
|
| 30 |
+
BaseModelOutputWithPastAndCrossAttentions,
|
| 31 |
+
BaseModelOutputWithPoolingAndCrossAttentions,
|
| 32 |
+
CausalLMOutputWithCrossAttentions,
|
| 33 |
+
MaskedLMOutput,
|
| 34 |
+
MultipleChoiceModelOutput,
|
| 35 |
+
NextSentencePredictorOutput,
|
| 36 |
+
QuestionAnsweringModelOutput,
|
| 37 |
+
SequenceClassifierOutput,
|
| 38 |
+
TokenClassifierOutput,
|
| 39 |
+
)
|
| 40 |
+
from transformers.modeling_utils import (
|
| 41 |
+
PreTrainedModel,
|
| 42 |
+
apply_chunking_to_forward,
|
| 43 |
+
find_pruneable_heads_and_indices,
|
| 44 |
+
prune_linear_layer,
|
| 45 |
+
)
|
| 46 |
+
from transformers.utils import logging
|
| 47 |
+
from transformers.models.bert.configuration_bert import BertConfig
|
| 48 |
+
|
| 49 |
+
logger = logging.get_logger(__name__)
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
class BertEmbeddings(nn.Module):
|
| 53 |
+
"""Construct the embeddings from word and position embeddings."""
|
| 54 |
+
|
| 55 |
+
def __init__(self, config):
|
| 56 |
+
super().__init__()
|
| 57 |
+
self.word_embeddings = nn.Embedding(
|
| 58 |
+
config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id
|
| 59 |
+
)
|
| 60 |
+
self.position_embeddings = nn.Embedding(
|
| 61 |
+
config.max_position_embeddings, config.hidden_size
|
| 62 |
+
)
|
| 63 |
+
|
| 64 |
+
# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load
|
| 65 |
+
# any TensorFlow checkpoint file
|
| 66 |
+
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 67 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 68 |
+
|
| 69 |
+
# position_ids (1, len position emb) is contiguous in memory and exported when serialized
|
| 70 |
+
self.register_buffer(
|
| 71 |
+
"position_ids", torch.arange(config.max_position_embeddings).expand((1, -1))
|
| 72 |
+
)
|
| 73 |
+
self.position_embedding_type = getattr(
|
| 74 |
+
config, "position_embedding_type", "absolute"
|
| 75 |
+
)
|
| 76 |
+
|
| 77 |
+
self.config = config
|
| 78 |
+
|
| 79 |
+
def forward(
|
| 80 |
+
self,
|
| 81 |
+
input_ids=None,
|
| 82 |
+
position_ids=None,
|
| 83 |
+
query_embeds=None,
|
| 84 |
+
past_key_values_length=0,
|
| 85 |
+
):
|
| 86 |
+
if input_ids is not None:
|
| 87 |
+
seq_length = input_ids.size()[1]
|
| 88 |
+
else:
|
| 89 |
+
seq_length = 0
|
| 90 |
+
|
| 91 |
+
if position_ids is None:
|
| 92 |
+
position_ids = self.position_ids[
|
| 93 |
+
:, past_key_values_length : seq_length + past_key_values_length
|
| 94 |
+
].clone()
|
| 95 |
+
|
| 96 |
+
if input_ids is not None:
|
| 97 |
+
embeddings = self.word_embeddings(input_ids)
|
| 98 |
+
if self.position_embedding_type == "absolute":
|
| 99 |
+
position_embeddings = self.position_embeddings(position_ids)
|
| 100 |
+
embeddings = embeddings + position_embeddings
|
| 101 |
+
|
| 102 |
+
if query_embeds is not None:
|
| 103 |
+
embeddings = torch.cat((query_embeds, embeddings), dim=1)
|
| 104 |
+
else:
|
| 105 |
+
embeddings = query_embeds
|
| 106 |
+
|
| 107 |
+
embeddings = self.LayerNorm(embeddings)
|
| 108 |
+
embeddings = self.dropout(embeddings)
|
| 109 |
+
return embeddings
|
| 110 |
+
|
| 111 |
+
|
| 112 |
+
class BertSelfAttention(nn.Module):
|
| 113 |
+
def __init__(self, config, is_cross_attention):
|
| 114 |
+
super().__init__()
|
| 115 |
+
self.config = config
|
| 116 |
+
if config.hidden_size % config.num_attention_heads != 0 and not hasattr(
|
| 117 |
+
config, "embedding_size"
|
| 118 |
+
):
|
| 119 |
+
raise ValueError(
|
| 120 |
+
"The hidden size (%d) is not a multiple of the number of attention "
|
| 121 |
+
"heads (%d)" % (config.hidden_size, config.num_attention_heads)
|
| 122 |
+
)
|
| 123 |
+
|
| 124 |
+
self.num_attention_heads = config.num_attention_heads
|
| 125 |
+
self.attention_head_size = int(config.hidden_size / config.num_attention_heads)
|
| 126 |
+
self.all_head_size = self.num_attention_heads * self.attention_head_size
|
| 127 |
+
|
| 128 |
+
self.query = nn.Linear(config.hidden_size, self.all_head_size)
|
| 129 |
+
if is_cross_attention:
|
| 130 |
+
self.key = nn.Linear(config.encoder_width, self.all_head_size)
|
| 131 |
+
self.value = nn.Linear(config.encoder_width, self.all_head_size)
|
| 132 |
+
else:
|
| 133 |
+
self.key = nn.Linear(config.hidden_size, self.all_head_size)
|
| 134 |
+
self.value = nn.Linear(config.hidden_size, self.all_head_size)
|
| 135 |
+
|
| 136 |
+
self.dropout = nn.Dropout(config.attention_probs_dropout_prob)
|
| 137 |
+
self.position_embedding_type = getattr(
|
| 138 |
+
config, "position_embedding_type", "absolute"
|
| 139 |
+
)
|
| 140 |
+
if (
|
| 141 |
+
self.position_embedding_type == "relative_key"
|
| 142 |
+
or self.position_embedding_type == "relative_key_query"
|
| 143 |
+
):
|
| 144 |
+
self.max_position_embeddings = config.max_position_embeddings
|
| 145 |
+
self.distance_embedding = nn.Embedding(
|
| 146 |
+
2 * config.max_position_embeddings - 1, self.attention_head_size
|
| 147 |
+
)
|
| 148 |
+
self.save_attention = False
|
| 149 |
+
|
| 150 |
+
def save_attn_gradients(self, attn_gradients):
|
| 151 |
+
self.attn_gradients = attn_gradients
|
| 152 |
+
|
| 153 |
+
def get_attn_gradients(self):
|
| 154 |
+
return self.attn_gradients
|
| 155 |
+
|
| 156 |
+
def save_attention_map(self, attention_map):
|
| 157 |
+
self.attention_map = attention_map
|
| 158 |
+
|
| 159 |
+
def get_attention_map(self):
|
| 160 |
+
return self.attention_map
|
| 161 |
+
|
| 162 |
+
def transpose_for_scores(self, x):
|
| 163 |
+
new_x_shape = x.size()[:-1] + (
|
| 164 |
+
self.num_attention_heads,
|
| 165 |
+
self.attention_head_size,
|
| 166 |
+
)
|
| 167 |
+
x = x.view(*new_x_shape)
|
| 168 |
+
return x.permute(0, 2, 1, 3)
|
| 169 |
+
|
| 170 |
+
def forward(
|
| 171 |
+
self,
|
| 172 |
+
hidden_states,
|
| 173 |
+
attention_mask=None,
|
| 174 |
+
head_mask=None,
|
| 175 |
+
encoder_hidden_states=None,
|
| 176 |
+
encoder_attention_mask=None,
|
| 177 |
+
past_key_value=None,
|
| 178 |
+
output_attentions=False,
|
| 179 |
+
):
|
| 180 |
+
|
| 181 |
+
# If this is instantiated as a cross-attention module, the keys
|
| 182 |
+
# and values come from an encoder; the attention mask needs to be
|
| 183 |
+
# such that the encoder's padding tokens are not attended to.
|
| 184 |
+
is_cross_attention = encoder_hidden_states is not None
|
| 185 |
+
|
| 186 |
+
if is_cross_attention:
|
| 187 |
+
key_layer = self.transpose_for_scores(self.key(encoder_hidden_states))
|
| 188 |
+
value_layer = self.transpose_for_scores(self.value(encoder_hidden_states))
|
| 189 |
+
attention_mask = encoder_attention_mask
|
| 190 |
+
elif past_key_value is not None:
|
| 191 |
+
key_layer = self.transpose_for_scores(self.key(hidden_states))
|
| 192 |
+
value_layer = self.transpose_for_scores(self.value(hidden_states))
|
| 193 |
+
key_layer = torch.cat([past_key_value[0], key_layer], dim=2)
|
| 194 |
+
value_layer = torch.cat([past_key_value[1], value_layer], dim=2)
|
| 195 |
+
else:
|
| 196 |
+
key_layer = self.transpose_for_scores(self.key(hidden_states))
|
| 197 |
+
value_layer = self.transpose_for_scores(self.value(hidden_states))
|
| 198 |
+
|
| 199 |
+
mixed_query_layer = self.query(hidden_states)
|
| 200 |
+
|
| 201 |
+
query_layer = self.transpose_for_scores(mixed_query_layer)
|
| 202 |
+
|
| 203 |
+
past_key_value = (key_layer, value_layer)
|
| 204 |
+
|
| 205 |
+
# Take the dot product between "query" and "key" to get the raw attention scores.
|
| 206 |
+
attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2))
|
| 207 |
+
|
| 208 |
+
if (
|
| 209 |
+
self.position_embedding_type == "relative_key"
|
| 210 |
+
or self.position_embedding_type == "relative_key_query"
|
| 211 |
+
):
|
| 212 |
+
seq_length = hidden_states.size()[1]
|
| 213 |
+
position_ids_l = torch.arange(
|
| 214 |
+
seq_length, dtype=torch.long, device=hidden_states.device
|
| 215 |
+
).view(-1, 1)
|
| 216 |
+
position_ids_r = torch.arange(
|
| 217 |
+
seq_length, dtype=torch.long, device=hidden_states.device
|
| 218 |
+
).view(1, -1)
|
| 219 |
+
distance = position_ids_l - position_ids_r
|
| 220 |
+
positional_embedding = self.distance_embedding(
|
| 221 |
+
distance + self.max_position_embeddings - 1
|
| 222 |
+
)
|
| 223 |
+
positional_embedding = positional_embedding.to(
|
| 224 |
+
dtype=query_layer.dtype
|
| 225 |
+
) # fp16 compatibility
|
| 226 |
+
|
| 227 |
+
if self.position_embedding_type == "relative_key":
|
| 228 |
+
relative_position_scores = torch.einsum(
|
| 229 |
+
"bhld,lrd->bhlr", query_layer, positional_embedding
|
| 230 |
+
)
|
| 231 |
+
attention_scores = attention_scores + relative_position_scores
|
| 232 |
+
elif self.position_embedding_type == "relative_key_query":
|
| 233 |
+
relative_position_scores_query = torch.einsum(
|
| 234 |
+
"bhld,lrd->bhlr", query_layer, positional_embedding
|
| 235 |
+
)
|
| 236 |
+
relative_position_scores_key = torch.einsum(
|
| 237 |
+
"bhrd,lrd->bhlr", key_layer, positional_embedding
|
| 238 |
+
)
|
| 239 |
+
attention_scores = (
|
| 240 |
+
attention_scores
|
| 241 |
+
+ relative_position_scores_query
|
| 242 |
+
+ relative_position_scores_key
|
| 243 |
+
)
|
| 244 |
+
|
| 245 |
+
attention_scores = attention_scores / math.sqrt(self.attention_head_size)
|
| 246 |
+
if attention_mask is not None:
|
| 247 |
+
# Apply the attention mask is (precomputed for all layers in BertModel forward() function)
|
| 248 |
+
attention_scores = attention_scores + attention_mask
|
| 249 |
+
|
| 250 |
+
# Normalize the attention scores to probabilities.
|
| 251 |
+
attention_probs = nn.Softmax(dim=-1)(attention_scores)
|
| 252 |
+
|
| 253 |
+
if is_cross_attention and self.save_attention:
|
| 254 |
+
self.save_attention_map(attention_probs)
|
| 255 |
+
attention_probs.register_hook(self.save_attn_gradients)
|
| 256 |
+
|
| 257 |
+
# This is actually dropping out entire tokens to attend to, which might
|
| 258 |
+
# seem a bit unusual, but is taken from the original Transformer paper.
|
| 259 |
+
attention_probs_dropped = self.dropout(attention_probs)
|
| 260 |
+
|
| 261 |
+
# Mask heads if we want to
|
| 262 |
+
if head_mask is not None:
|
| 263 |
+
attention_probs_dropped = attention_probs_dropped * head_mask
|
| 264 |
+
|
| 265 |
+
context_layer = torch.matmul(attention_probs_dropped, value_layer)
|
| 266 |
+
|
| 267 |
+
context_layer = context_layer.permute(0, 2, 1, 3).contiguous()
|
| 268 |
+
new_context_layer_shape = context_layer.size()[:-2] + (self.all_head_size,)
|
| 269 |
+
context_layer = context_layer.view(*new_context_layer_shape)
|
| 270 |
+
|
| 271 |
+
outputs = (
|
| 272 |
+
(context_layer, attention_probs) if output_attentions else (context_layer,)
|
| 273 |
+
)
|
| 274 |
+
|
| 275 |
+
outputs = outputs + (past_key_value,)
|
| 276 |
+
return outputs
|
| 277 |
+
|
| 278 |
+
|
| 279 |
+
class BertSelfOutput(nn.Module):
|
| 280 |
+
def __init__(self, config):
|
| 281 |
+
super().__init__()
|
| 282 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 283 |
+
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 284 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 285 |
+
|
| 286 |
+
def forward(self, hidden_states, input_tensor):
|
| 287 |
+
hidden_states = self.dense(hidden_states)
|
| 288 |
+
hidden_states = self.dropout(hidden_states)
|
| 289 |
+
hidden_states = self.LayerNorm(hidden_states + input_tensor)
|
| 290 |
+
return hidden_states
|
| 291 |
+
|
| 292 |
+
|
| 293 |
+
class BertAttention(nn.Module):
|
| 294 |
+
def __init__(self, config, is_cross_attention=False):
|
| 295 |
+
super().__init__()
|
| 296 |
+
self.self = BertSelfAttention(config, is_cross_attention)
|
| 297 |
+
self.output = BertSelfOutput(config)
|
| 298 |
+
self.pruned_heads = set()
|
| 299 |
+
|
| 300 |
+
def prune_heads(self, heads):
|
| 301 |
+
if len(heads) == 0:
|
| 302 |
+
return
|
| 303 |
+
heads, index = find_pruneable_heads_and_indices(
|
| 304 |
+
heads,
|
| 305 |
+
self.self.num_attention_heads,
|
| 306 |
+
self.self.attention_head_size,
|
| 307 |
+
self.pruned_heads,
|
| 308 |
+
)
|
| 309 |
+
|
| 310 |
+
# Prune linear layers
|
| 311 |
+
self.self.query = prune_linear_layer(self.self.query, index)
|
| 312 |
+
self.self.key = prune_linear_layer(self.self.key, index)
|
| 313 |
+
self.self.value = prune_linear_layer(self.self.value, index)
|
| 314 |
+
self.output.dense = prune_linear_layer(self.output.dense, index, dim=1)
|
| 315 |
+
|
| 316 |
+
# Update hyper params and store pruned heads
|
| 317 |
+
self.self.num_attention_heads = self.self.num_attention_heads - len(heads)
|
| 318 |
+
self.self.all_head_size = (
|
| 319 |
+
self.self.attention_head_size * self.self.num_attention_heads
|
| 320 |
+
)
|
| 321 |
+
self.pruned_heads = self.pruned_heads.union(heads)
|
| 322 |
+
|
| 323 |
+
def forward(
|
| 324 |
+
self,
|
| 325 |
+
hidden_states,
|
| 326 |
+
attention_mask=None,
|
| 327 |
+
head_mask=None,
|
| 328 |
+
encoder_hidden_states=None,
|
| 329 |
+
encoder_attention_mask=None,
|
| 330 |
+
past_key_value=None,
|
| 331 |
+
output_attentions=False,
|
| 332 |
+
):
|
| 333 |
+
self_outputs = self.self(
|
| 334 |
+
hidden_states,
|
| 335 |
+
attention_mask,
|
| 336 |
+
head_mask,
|
| 337 |
+
encoder_hidden_states,
|
| 338 |
+
encoder_attention_mask,
|
| 339 |
+
past_key_value,
|
| 340 |
+
output_attentions,
|
| 341 |
+
)
|
| 342 |
+
attention_output = self.output(self_outputs[0], hidden_states)
|
| 343 |
+
|
| 344 |
+
outputs = (attention_output,) + self_outputs[
|
| 345 |
+
1:
|
| 346 |
+
] # add attentions if we output them
|
| 347 |
+
return outputs
|
| 348 |
+
|
| 349 |
+
|
| 350 |
+
class BertIntermediate(nn.Module):
|
| 351 |
+
def __init__(self, config):
|
| 352 |
+
super().__init__()
|
| 353 |
+
self.dense = nn.Linear(config.hidden_size, config.intermediate_size)
|
| 354 |
+
if isinstance(config.hidden_act, str):
|
| 355 |
+
self.intermediate_act_fn = ACT2FN[config.hidden_act]
|
| 356 |
+
else:
|
| 357 |
+
self.intermediate_act_fn = config.hidden_act
|
| 358 |
+
|
| 359 |
+
def forward(self, hidden_states):
|
| 360 |
+
hidden_states = self.dense(hidden_states)
|
| 361 |
+
hidden_states = self.intermediate_act_fn(hidden_states)
|
| 362 |
+
return hidden_states
|
| 363 |
+
|
| 364 |
+
|
| 365 |
+
class BertOutput(nn.Module):
|
| 366 |
+
def __init__(self, config):
|
| 367 |
+
super().__init__()
|
| 368 |
+
self.dense = nn.Linear(config.intermediate_size, config.hidden_size)
|
| 369 |
+
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 370 |
+
self.dropout = nn.Dropout(config.hidden_dropout_prob)
|
| 371 |
+
|
| 372 |
+
def forward(self, hidden_states, input_tensor):
|
| 373 |
+
hidden_states = self.dense(hidden_states)
|
| 374 |
+
hidden_states = self.dropout(hidden_states)
|
| 375 |
+
hidden_states = self.LayerNorm(hidden_states + input_tensor)
|
| 376 |
+
return hidden_states
|
| 377 |
+
|
| 378 |
+
|
| 379 |
+
class BertLayer(nn.Module):
|
| 380 |
+
def __init__(self, config, layer_num):
|
| 381 |
+
super().__init__()
|
| 382 |
+
self.config = config
|
| 383 |
+
self.chunk_size_feed_forward = config.chunk_size_feed_forward
|
| 384 |
+
self.seq_len_dim = 1
|
| 385 |
+
self.attention = BertAttention(config)
|
| 386 |
+
self.layer_num = layer_num
|
| 387 |
+
if (
|
| 388 |
+
self.config.add_cross_attention
|
| 389 |
+
and layer_num % self.config.cross_attention_freq == 0
|
| 390 |
+
):
|
| 391 |
+
self.crossattention = BertAttention(
|
| 392 |
+
config, is_cross_attention=self.config.add_cross_attention
|
| 393 |
+
)
|
| 394 |
+
self.has_cross_attention = True
|
| 395 |
+
else:
|
| 396 |
+
self.has_cross_attention = False
|
| 397 |
+
self.intermediate = BertIntermediate(config)
|
| 398 |
+
self.output = BertOutput(config)
|
| 399 |
+
|
| 400 |
+
self.intermediate_query = BertIntermediate(config)
|
| 401 |
+
self.output_query = BertOutput(config)
|
| 402 |
+
|
| 403 |
+
def forward(
|
| 404 |
+
self,
|
| 405 |
+
hidden_states,
|
| 406 |
+
attention_mask=None,
|
| 407 |
+
head_mask=None,
|
| 408 |
+
encoder_hidden_states=None,
|
| 409 |
+
encoder_attention_mask=None,
|
| 410 |
+
past_key_value=None,
|
| 411 |
+
output_attentions=False,
|
| 412 |
+
query_length=0,
|
| 413 |
+
):
|
| 414 |
+
# decoder uni-directional self-attention cached key/values tuple is at positions 1,2
|
| 415 |
+
self_attn_past_key_value = (
|
| 416 |
+
past_key_value[:2] if past_key_value is not None else None
|
| 417 |
+
)
|
| 418 |
+
self_attention_outputs = self.attention(
|
| 419 |
+
hidden_states,
|
| 420 |
+
attention_mask,
|
| 421 |
+
head_mask,
|
| 422 |
+
output_attentions=output_attentions,
|
| 423 |
+
past_key_value=self_attn_past_key_value,
|
| 424 |
+
)
|
| 425 |
+
attention_output = self_attention_outputs[0]
|
| 426 |
+
outputs = self_attention_outputs[1:-1]
|
| 427 |
+
|
| 428 |
+
present_key_value = self_attention_outputs[-1]
|
| 429 |
+
|
| 430 |
+
if query_length > 0:
|
| 431 |
+
query_attention_output = attention_output[:, :query_length, :]
|
| 432 |
+
|
| 433 |
+
if self.has_cross_attention:
|
| 434 |
+
assert (
|
| 435 |
+
encoder_hidden_states is not None
|
| 436 |
+
), "encoder_hidden_states must be given for cross-attention layers"
|
| 437 |
+
cross_attention_outputs = self.crossattention(
|
| 438 |
+
query_attention_output,
|
| 439 |
+
attention_mask,
|
| 440 |
+
head_mask,
|
| 441 |
+
encoder_hidden_states,
|
| 442 |
+
encoder_attention_mask,
|
| 443 |
+
output_attentions=output_attentions,
|
| 444 |
+
)
|
| 445 |
+
query_attention_output = cross_attention_outputs[0]
|
| 446 |
+
outputs = (
|
| 447 |
+
outputs + cross_attention_outputs[1:-1]
|
| 448 |
+
) # add cross attentions if we output attention weights
|
| 449 |
+
|
| 450 |
+
layer_output = apply_chunking_to_forward(
|
| 451 |
+
self.feed_forward_chunk_query,
|
| 452 |
+
self.chunk_size_feed_forward,
|
| 453 |
+
self.seq_len_dim,
|
| 454 |
+
query_attention_output,
|
| 455 |
+
)
|
| 456 |
+
if attention_output.shape[1] > query_length:
|
| 457 |
+
layer_output_text = apply_chunking_to_forward(
|
| 458 |
+
self.feed_forward_chunk,
|
| 459 |
+
self.chunk_size_feed_forward,
|
| 460 |
+
self.seq_len_dim,
|
| 461 |
+
attention_output[:, query_length:, :],
|
| 462 |
+
)
|
| 463 |
+
layer_output = torch.cat([layer_output, layer_output_text], dim=1)
|
| 464 |
+
else:
|
| 465 |
+
layer_output = apply_chunking_to_forward(
|
| 466 |
+
self.feed_forward_chunk,
|
| 467 |
+
self.chunk_size_feed_forward,
|
| 468 |
+
self.seq_len_dim,
|
| 469 |
+
attention_output,
|
| 470 |
+
)
|
| 471 |
+
outputs = (layer_output,) + outputs
|
| 472 |
+
|
| 473 |
+
outputs = outputs + (present_key_value,)
|
| 474 |
+
|
| 475 |
+
return outputs
|
| 476 |
+
|
| 477 |
+
def feed_forward_chunk(self, attention_output):
|
| 478 |
+
intermediate_output = self.intermediate(attention_output)
|
| 479 |
+
layer_output = self.output(intermediate_output, attention_output)
|
| 480 |
+
return layer_output
|
| 481 |
+
|
| 482 |
+
def feed_forward_chunk_query(self, attention_output):
|
| 483 |
+
intermediate_output = self.intermediate_query(attention_output)
|
| 484 |
+
layer_output = self.output_query(intermediate_output, attention_output)
|
| 485 |
+
return layer_output
|
| 486 |
+
|
| 487 |
+
|
| 488 |
+
class BertEncoder(nn.Module):
|
| 489 |
+
def __init__(self, config):
|
| 490 |
+
super().__init__()
|
| 491 |
+
self.config = config
|
| 492 |
+
self.layer = nn.ModuleList(
|
| 493 |
+
[BertLayer(config, i) for i in range(config.num_hidden_layers)]
|
| 494 |
+
)
|
| 495 |
+
|
| 496 |
+
def forward(
|
| 497 |
+
self,
|
| 498 |
+
hidden_states,
|
| 499 |
+
attention_mask=None,
|
| 500 |
+
head_mask=None,
|
| 501 |
+
encoder_hidden_states=None,
|
| 502 |
+
encoder_attention_mask=None,
|
| 503 |
+
past_key_values=None,
|
| 504 |
+
use_cache=None,
|
| 505 |
+
output_attentions=False,
|
| 506 |
+
output_hidden_states=False,
|
| 507 |
+
return_dict=True,
|
| 508 |
+
query_length=0,
|
| 509 |
+
):
|
| 510 |
+
all_hidden_states = () if output_hidden_states else None
|
| 511 |
+
all_self_attentions = () if output_attentions else None
|
| 512 |
+
all_cross_attentions = (
|
| 513 |
+
() if output_attentions and self.config.add_cross_attention else None
|
| 514 |
+
)
|
| 515 |
+
|
| 516 |
+
next_decoder_cache = () if use_cache else None
|
| 517 |
+
|
| 518 |
+
for i in range(self.config.num_hidden_layers):
|
| 519 |
+
layer_module = self.layer[i]
|
| 520 |
+
if output_hidden_states:
|
| 521 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 522 |
+
|
| 523 |
+
layer_head_mask = head_mask[i] if head_mask is not None else None
|
| 524 |
+
past_key_value = past_key_values[i] if past_key_values is not None else None
|
| 525 |
+
|
| 526 |
+
if getattr(self.config, "gradient_checkpointing", False) and self.training:
|
| 527 |
+
|
| 528 |
+
if use_cache:
|
| 529 |
+
logger.warn(
|
| 530 |
+
"`use_cache=True` is incompatible with gradient checkpointing. Setting `use_cache=False`..."
|
| 531 |
+
)
|
| 532 |
+
use_cache = False
|
| 533 |
+
|
| 534 |
+
def create_custom_forward(module):
|
| 535 |
+
def custom_forward(*inputs):
|
| 536 |
+
return module(
|
| 537 |
+
*inputs, past_key_value, output_attentions, query_length
|
| 538 |
+
)
|
| 539 |
+
|
| 540 |
+
return custom_forward
|
| 541 |
+
|
| 542 |
+
layer_outputs = torch.utils.checkpoint.checkpoint(
|
| 543 |
+
create_custom_forward(layer_module),
|
| 544 |
+
hidden_states,
|
| 545 |
+
attention_mask,
|
| 546 |
+
layer_head_mask,
|
| 547 |
+
encoder_hidden_states,
|
| 548 |
+
encoder_attention_mask,
|
| 549 |
+
)
|
| 550 |
+
else:
|
| 551 |
+
layer_outputs = layer_module(
|
| 552 |
+
hidden_states,
|
| 553 |
+
attention_mask,
|
| 554 |
+
layer_head_mask,
|
| 555 |
+
encoder_hidden_states,
|
| 556 |
+
encoder_attention_mask,
|
| 557 |
+
past_key_value,
|
| 558 |
+
output_attentions,
|
| 559 |
+
query_length,
|
| 560 |
+
)
|
| 561 |
+
|
| 562 |
+
hidden_states = layer_outputs[0]
|
| 563 |
+
if use_cache:
|
| 564 |
+
next_decoder_cache += (layer_outputs[-1],)
|
| 565 |
+
if output_attentions:
|
| 566 |
+
all_self_attentions = all_self_attentions + (layer_outputs[1],)
|
| 567 |
+
all_cross_attentions = all_cross_attentions + (layer_outputs[2],)
|
| 568 |
+
|
| 569 |
+
if output_hidden_states:
|
| 570 |
+
all_hidden_states = all_hidden_states + (hidden_states,)
|
| 571 |
+
|
| 572 |
+
if not return_dict:
|
| 573 |
+
return tuple(
|
| 574 |
+
v
|
| 575 |
+
for v in [
|
| 576 |
+
hidden_states,
|
| 577 |
+
next_decoder_cache,
|
| 578 |
+
all_hidden_states,
|
| 579 |
+
all_self_attentions,
|
| 580 |
+
all_cross_attentions,
|
| 581 |
+
]
|
| 582 |
+
if v is not None
|
| 583 |
+
)
|
| 584 |
+
return BaseModelOutputWithPastAndCrossAttentions(
|
| 585 |
+
last_hidden_state=hidden_states,
|
| 586 |
+
past_key_values=next_decoder_cache,
|
| 587 |
+
hidden_states=all_hidden_states,
|
| 588 |
+
attentions=all_self_attentions,
|
| 589 |
+
cross_attentions=all_cross_attentions,
|
| 590 |
+
)
|
| 591 |
+
|
| 592 |
+
|
| 593 |
+
class BertPooler(nn.Module):
|
| 594 |
+
def __init__(self, config):
|
| 595 |
+
super().__init__()
|
| 596 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 597 |
+
self.activation = nn.Tanh()
|
| 598 |
+
|
| 599 |
+
def forward(self, hidden_states):
|
| 600 |
+
# We "pool" the model by simply taking the hidden state corresponding
|
| 601 |
+
# to the first token.
|
| 602 |
+
first_token_tensor = hidden_states[:, 0]
|
| 603 |
+
pooled_output = self.dense(first_token_tensor)
|
| 604 |
+
pooled_output = self.activation(pooled_output)
|
| 605 |
+
return pooled_output
|
| 606 |
+
|
| 607 |
+
|
| 608 |
+
class BertPredictionHeadTransform(nn.Module):
|
| 609 |
+
def __init__(self, config):
|
| 610 |
+
super().__init__()
|
| 611 |
+
self.dense = nn.Linear(config.hidden_size, config.hidden_size)
|
| 612 |
+
if isinstance(config.hidden_act, str):
|
| 613 |
+
self.transform_act_fn = ACT2FN[config.hidden_act]
|
| 614 |
+
else:
|
| 615 |
+
self.transform_act_fn = config.hidden_act
|
| 616 |
+
self.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)
|
| 617 |
+
|
| 618 |
+
def forward(self, hidden_states):
|
| 619 |
+
hidden_states = self.dense(hidden_states)
|
| 620 |
+
hidden_states = self.transform_act_fn(hidden_states)
|
| 621 |
+
hidden_states = self.LayerNorm(hidden_states)
|
| 622 |
+
return hidden_states
|
| 623 |
+
|
| 624 |
+
|
| 625 |
+
class BertLMPredictionHead(nn.Module):
|
| 626 |
+
def __init__(self, config):
|
| 627 |
+
super().__init__()
|
| 628 |
+
self.transform = BertPredictionHeadTransform(config)
|
| 629 |
+
|
| 630 |
+
# The output weights are the same as the input embeddings, but there is
|
| 631 |
+
# an output-only bias for each token.
|
| 632 |
+
self.decoder = nn.Linear(config.hidden_size, config.vocab_size, bias=False)
|
| 633 |
+
|
| 634 |
+
self.bias = nn.Parameter(torch.zeros(config.vocab_size))
|
| 635 |
+
|
| 636 |
+
# Need a link between the two variables so that the bias is correctly resized with `resize_token_embeddings`
|
| 637 |
+
self.decoder.bias = self.bias
|
| 638 |
+
|
| 639 |
+
def forward(self, hidden_states):
|
| 640 |
+
hidden_states = self.transform(hidden_states)
|
| 641 |
+
hidden_states = self.decoder(hidden_states)
|
| 642 |
+
return hidden_states
|
| 643 |
+
|
| 644 |
+
|
| 645 |
+
class BertOnlyMLMHead(nn.Module):
|
| 646 |
+
def __init__(self, config):
|
| 647 |
+
super().__init__()
|
| 648 |
+
self.predictions = BertLMPredictionHead(config)
|
| 649 |
+
|
| 650 |
+
def forward(self, sequence_output):
|
| 651 |
+
prediction_scores = self.predictions(sequence_output)
|
| 652 |
+
return prediction_scores
|
| 653 |
+
|
| 654 |
+
|
| 655 |
+
class BertPreTrainedModel(PreTrainedModel):
|
| 656 |
+
"""
|
| 657 |
+
An abstract class to handle weights initialization and a simple interface for downloading and loading pretrained
|
| 658 |
+
models.
|
| 659 |
+
"""
|
| 660 |
+
|
| 661 |
+
config_class = BertConfig
|
| 662 |
+
base_model_prefix = "bert"
|
| 663 |
+
_keys_to_ignore_on_load_missing = [r"position_ids"]
|
| 664 |
+
|
| 665 |
+
def _init_weights(self, module):
|
| 666 |
+
"""Initialize the weights"""
|
| 667 |
+
if isinstance(module, (nn.Linear, nn.Embedding)):
|
| 668 |
+
# Slightly different from the TF version which uses truncated_normal for initialization
|
| 669 |
+
# cf https://github.com/pytorch/pytorch/pull/5617
|
| 670 |
+
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
|
| 671 |
+
elif isinstance(module, nn.LayerNorm):
|
| 672 |
+
module.bias.data.zero_()
|
| 673 |
+
module.weight.data.fill_(1.0)
|
| 674 |
+
if isinstance(module, nn.Linear) and module.bias is not None:
|
| 675 |
+
module.bias.data.zero_()
|
| 676 |
+
|
| 677 |
+
|
| 678 |
+
class BertModel(BertPreTrainedModel):
|
| 679 |
+
"""
|
| 680 |
+
The model can behave as an encoder (with only self-attention) as well as a decoder, in which case a layer of
|
| 681 |
+
cross-attention is added between the self-attention layers, following the architecture described in `Attention is
|
| 682 |
+
all you need <https://arxiv.org/abs/1706.03762>`__ by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit,
|
| 683 |
+
Llion Jones, Aidan N. Gomez, Lukasz Kaiser and Illia Polosukhin.
|
| 684 |
+
argument and :obj:`add_cross_attention` set to :obj:`True`; an :obj:`encoder_hidden_states` is then expected as an
|
| 685 |
+
input to the forward pass.
|
| 686 |
+
"""
|
| 687 |
+
|
| 688 |
+
def __init__(self, config, add_pooling_layer=False):
|
| 689 |
+
super().__init__(config)
|
| 690 |
+
self.config = config
|
| 691 |
+
|
| 692 |
+
self.embeddings = BertEmbeddings(config)
|
| 693 |
+
|
| 694 |
+
self.encoder = BertEncoder(config)
|
| 695 |
+
|
| 696 |
+
self.pooler = BertPooler(config) if add_pooling_layer else None
|
| 697 |
+
|
| 698 |
+
self.init_weights()
|
| 699 |
+
|
| 700 |
+
def get_input_embeddings(self):
|
| 701 |
+
return self.embeddings.word_embeddings
|
| 702 |
+
|
| 703 |
+
def set_input_embeddings(self, value):
|
| 704 |
+
self.embeddings.word_embeddings = value
|
| 705 |
+
|
| 706 |
+
def _prune_heads(self, heads_to_prune):
|
| 707 |
+
"""
|
| 708 |
+
Prunes heads of the model. heads_to_prune: dict of {layer_num: list of heads to prune in this layer} See base
|
| 709 |
+
class PreTrainedModel
|
| 710 |
+
"""
|
| 711 |
+
for layer, heads in heads_to_prune.items():
|
| 712 |
+
self.encoder.layer[layer].attention.prune_heads(heads)
|
| 713 |
+
|
| 714 |
+
def get_extended_attention_mask(
|
| 715 |
+
self,
|
| 716 |
+
attention_mask: Tensor,
|
| 717 |
+
input_shape: Tuple[int],
|
| 718 |
+
device: device,
|
| 719 |
+
is_decoder: bool,
|
| 720 |
+
has_query: bool = False,
|
| 721 |
+
) -> Tensor:
|
| 722 |
+
"""
|
| 723 |
+
Makes broadcastable attention and causal masks so that future and masked tokens are ignored.
|
| 724 |
+
|
| 725 |
+
Arguments:
|
| 726 |
+
attention_mask (:obj:`torch.Tensor`):
|
| 727 |
+
Mask with ones indicating tokens to attend to, zeros for tokens to ignore.
|
| 728 |
+
input_shape (:obj:`Tuple[int]`):
|
| 729 |
+
The shape of the input to the model.
|
| 730 |
+
device: (:obj:`torch.device`):
|
| 731 |
+
The device of the input to the model.
|
| 732 |
+
|
| 733 |
+
Returns:
|
| 734 |
+
:obj:`torch.Tensor` The extended attention mask, with a the same dtype as :obj:`attention_mask.dtype`.
|
| 735 |
+
"""
|
| 736 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 737 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 738 |
+
if attention_mask.dim() == 3:
|
| 739 |
+
extended_attention_mask = attention_mask[:, None, :, :]
|
| 740 |
+
elif attention_mask.dim() == 2:
|
| 741 |
+
# Provided a padding mask of dimensions [batch_size, seq_length]
|
| 742 |
+
# - if the model is a decoder, apply a causal mask in addition to the padding mask
|
| 743 |
+
# - if the model is an encoder, make the mask broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 744 |
+
if is_decoder:
|
| 745 |
+
batch_size, seq_length = input_shape
|
| 746 |
+
|
| 747 |
+
seq_ids = torch.arange(seq_length, device=device)
|
| 748 |
+
causal_mask = (
|
| 749 |
+
seq_ids[None, None, :].repeat(batch_size, seq_length, 1)
|
| 750 |
+
<= seq_ids[None, :, None]
|
| 751 |
+
)
|
| 752 |
+
|
| 753 |
+
# add a prefix ones mask to the causal mask
|
| 754 |
+
# causal and attention masks must have same type with pytorch version < 1.3
|
| 755 |
+
causal_mask = causal_mask.to(attention_mask.dtype)
|
| 756 |
+
|
| 757 |
+
if causal_mask.shape[1] < attention_mask.shape[1]:
|
| 758 |
+
prefix_seq_len = attention_mask.shape[1] - causal_mask.shape[1]
|
| 759 |
+
if has_query: # UniLM style attention mask
|
| 760 |
+
causal_mask = torch.cat(
|
| 761 |
+
[
|
| 762 |
+
torch.zeros(
|
| 763 |
+
(batch_size, prefix_seq_len, seq_length),
|
| 764 |
+
device=device,
|
| 765 |
+
dtype=causal_mask.dtype,
|
| 766 |
+
),
|
| 767 |
+
causal_mask,
|
| 768 |
+
],
|
| 769 |
+
axis=1,
|
| 770 |
+
)
|
| 771 |
+
causal_mask = torch.cat(
|
| 772 |
+
[
|
| 773 |
+
torch.ones(
|
| 774 |
+
(batch_size, causal_mask.shape[1], prefix_seq_len),
|
| 775 |
+
device=device,
|
| 776 |
+
dtype=causal_mask.dtype,
|
| 777 |
+
),
|
| 778 |
+
causal_mask,
|
| 779 |
+
],
|
| 780 |
+
axis=-1,
|
| 781 |
+
)
|
| 782 |
+
extended_attention_mask = (
|
| 783 |
+
causal_mask[:, None, :, :] * attention_mask[:, None, None, :]
|
| 784 |
+
)
|
| 785 |
+
else:
|
| 786 |
+
extended_attention_mask = attention_mask[:, None, None, :]
|
| 787 |
+
else:
|
| 788 |
+
raise ValueError(
|
| 789 |
+
"Wrong shape for input_ids (shape {}) or attention_mask (shape {})".format(
|
| 790 |
+
input_shape, attention_mask.shape
|
| 791 |
+
)
|
| 792 |
+
)
|
| 793 |
+
|
| 794 |
+
# Since attention_mask is 1.0 for positions we want to attend and 0.0 for
|
| 795 |
+
# masked positions, this operation will create a tensor which is 0.0 for
|
| 796 |
+
# positions we want to attend and -10000.0 for masked positions.
|
| 797 |
+
# Since we are adding it to the raw scores before the softmax, this is
|
| 798 |
+
# effectively the same as removing these entirely.
|
| 799 |
+
extended_attention_mask = extended_attention_mask.to(
|
| 800 |
+
dtype=self.dtype
|
| 801 |
+
) # fp16 compatibility
|
| 802 |
+
extended_attention_mask = (1.0 - extended_attention_mask) * -10000.0
|
| 803 |
+
return extended_attention_mask
|
| 804 |
+
|
| 805 |
+
def forward(
|
| 806 |
+
self,
|
| 807 |
+
input_ids=None,
|
| 808 |
+
attention_mask=None,
|
| 809 |
+
position_ids=None,
|
| 810 |
+
head_mask=None,
|
| 811 |
+
query_embeds=None,
|
| 812 |
+
encoder_hidden_states=None,
|
| 813 |
+
encoder_attention_mask=None,
|
| 814 |
+
past_key_values=None,
|
| 815 |
+
use_cache=None,
|
| 816 |
+
output_attentions=None,
|
| 817 |
+
output_hidden_states=None,
|
| 818 |
+
return_dict=None,
|
| 819 |
+
is_decoder=False,
|
| 820 |
+
):
|
| 821 |
+
r"""
|
| 822 |
+
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
|
| 823 |
+
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
|
| 824 |
+
the model is configured as a decoder.
|
| 825 |
+
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
|
| 826 |
+
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
|
| 827 |
+
the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
|
| 828 |
+
- 1 for tokens that are **not masked**,
|
| 829 |
+
- 0 for tokens that are **masked**.
|
| 830 |
+
past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
|
| 831 |
+
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
|
| 832 |
+
If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
|
| 833 |
+
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
|
| 834 |
+
instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
|
| 835 |
+
use_cache (:obj:`bool`, `optional`):
|
| 836 |
+
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
|
| 837 |
+
decoding (see :obj:`past_key_values`).
|
| 838 |
+
"""
|
| 839 |
+
output_attentions = (
|
| 840 |
+
output_attentions
|
| 841 |
+
if output_attentions is not None
|
| 842 |
+
else self.config.output_attentions
|
| 843 |
+
)
|
| 844 |
+
output_hidden_states = (
|
| 845 |
+
output_hidden_states
|
| 846 |
+
if output_hidden_states is not None
|
| 847 |
+
else self.config.output_hidden_states
|
| 848 |
+
)
|
| 849 |
+
return_dict = (
|
| 850 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 851 |
+
)
|
| 852 |
+
|
| 853 |
+
# use_cache = use_cache if use_cache is not None else self.config.use_cache
|
| 854 |
+
|
| 855 |
+
if input_ids is None:
|
| 856 |
+
assert (
|
| 857 |
+
query_embeds is not None
|
| 858 |
+
), "You have to specify query_embeds when input_ids is None"
|
| 859 |
+
|
| 860 |
+
# past_key_values_length
|
| 861 |
+
past_key_values_length = (
|
| 862 |
+
past_key_values[0][0].shape[2] - self.config.query_length
|
| 863 |
+
if past_key_values is not None
|
| 864 |
+
else 0
|
| 865 |
+
)
|
| 866 |
+
|
| 867 |
+
query_length = query_embeds.shape[1] if query_embeds is not None else 0
|
| 868 |
+
|
| 869 |
+
embedding_output = self.embeddings(
|
| 870 |
+
input_ids=input_ids,
|
| 871 |
+
position_ids=position_ids,
|
| 872 |
+
query_embeds=query_embeds,
|
| 873 |
+
past_key_values_length=past_key_values_length,
|
| 874 |
+
)
|
| 875 |
+
|
| 876 |
+
input_shape = embedding_output.size()[:-1]
|
| 877 |
+
batch_size, seq_length = input_shape
|
| 878 |
+
device = embedding_output.device
|
| 879 |
+
|
| 880 |
+
if attention_mask is None:
|
| 881 |
+
attention_mask = torch.ones(
|
| 882 |
+
((batch_size, seq_length + past_key_values_length)), device=device
|
| 883 |
+
)
|
| 884 |
+
|
| 885 |
+
# We can provide a self-attention mask of dimensions [batch_size, from_seq_length, to_seq_length]
|
| 886 |
+
# ourselves in which case we just need to make it broadcastable to all heads.
|
| 887 |
+
if is_decoder:
|
| 888 |
+
extended_attention_mask = self.get_extended_attention_mask(
|
| 889 |
+
attention_mask,
|
| 890 |
+
input_ids.shape,
|
| 891 |
+
device,
|
| 892 |
+
is_decoder,
|
| 893 |
+
has_query=(query_embeds is not None),
|
| 894 |
+
)
|
| 895 |
+
else:
|
| 896 |
+
extended_attention_mask = self.get_extended_attention_mask(
|
| 897 |
+
attention_mask, input_shape, device, is_decoder
|
| 898 |
+
)
|
| 899 |
+
|
| 900 |
+
# If a 2D or 3D attention mask is provided for the cross-attention
|
| 901 |
+
# we need to make broadcastable to [batch_size, num_heads, seq_length, seq_length]
|
| 902 |
+
if encoder_hidden_states is not None:
|
| 903 |
+
if type(encoder_hidden_states) == list:
|
| 904 |
+
encoder_batch_size, encoder_sequence_length, _ = encoder_hidden_states[
|
| 905 |
+
0
|
| 906 |
+
].size()
|
| 907 |
+
else:
|
| 908 |
+
(
|
| 909 |
+
encoder_batch_size,
|
| 910 |
+
encoder_sequence_length,
|
| 911 |
+
_,
|
| 912 |
+
) = encoder_hidden_states.size()
|
| 913 |
+
encoder_hidden_shape = (encoder_batch_size, encoder_sequence_length)
|
| 914 |
+
|
| 915 |
+
if type(encoder_attention_mask) == list:
|
| 916 |
+
encoder_extended_attention_mask = [
|
| 917 |
+
self.invert_attention_mask(mask) for mask in encoder_attention_mask
|
| 918 |
+
]
|
| 919 |
+
elif encoder_attention_mask is None:
|
| 920 |
+
encoder_attention_mask = torch.ones(encoder_hidden_shape, device=device)
|
| 921 |
+
encoder_extended_attention_mask = self.invert_attention_mask(
|
| 922 |
+
encoder_attention_mask
|
| 923 |
+
)
|
| 924 |
+
else:
|
| 925 |
+
encoder_extended_attention_mask = self.invert_attention_mask(
|
| 926 |
+
encoder_attention_mask
|
| 927 |
+
)
|
| 928 |
+
else:
|
| 929 |
+
encoder_extended_attention_mask = None
|
| 930 |
+
|
| 931 |
+
# Prepare head mask if needed
|
| 932 |
+
# 1.0 in head_mask indicate we keep the head
|
| 933 |
+
# attention_probs has shape bsz x n_heads x N x N
|
| 934 |
+
# input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
|
| 935 |
+
# and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
|
| 936 |
+
head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
|
| 937 |
+
|
| 938 |
+
encoder_outputs = self.encoder(
|
| 939 |
+
embedding_output,
|
| 940 |
+
attention_mask=extended_attention_mask,
|
| 941 |
+
head_mask=head_mask,
|
| 942 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 943 |
+
encoder_attention_mask=encoder_extended_attention_mask,
|
| 944 |
+
past_key_values=past_key_values,
|
| 945 |
+
use_cache=use_cache,
|
| 946 |
+
output_attentions=output_attentions,
|
| 947 |
+
output_hidden_states=output_hidden_states,
|
| 948 |
+
return_dict=return_dict,
|
| 949 |
+
query_length=query_length,
|
| 950 |
+
)
|
| 951 |
+
sequence_output = encoder_outputs[0]
|
| 952 |
+
pooled_output = (
|
| 953 |
+
self.pooler(sequence_output) if self.pooler is not None else None
|
| 954 |
+
)
|
| 955 |
+
|
| 956 |
+
if not return_dict:
|
| 957 |
+
return (sequence_output, pooled_output) + encoder_outputs[1:]
|
| 958 |
+
|
| 959 |
+
return BaseModelOutputWithPoolingAndCrossAttentions(
|
| 960 |
+
last_hidden_state=sequence_output,
|
| 961 |
+
pooler_output=pooled_output,
|
| 962 |
+
past_key_values=encoder_outputs.past_key_values,
|
| 963 |
+
hidden_states=encoder_outputs.hidden_states,
|
| 964 |
+
attentions=encoder_outputs.attentions,
|
| 965 |
+
cross_attentions=encoder_outputs.cross_attentions,
|
| 966 |
+
)
|
| 967 |
+
|
| 968 |
+
|
| 969 |
+
class BertLMHeadModel(BertPreTrainedModel):
|
| 970 |
+
|
| 971 |
+
_keys_to_ignore_on_load_unexpected = [r"pooler"]
|
| 972 |
+
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
|
| 973 |
+
|
| 974 |
+
def __init__(self, config):
|
| 975 |
+
super().__init__(config)
|
| 976 |
+
|
| 977 |
+
self.bert = BertModel(config, add_pooling_layer=False)
|
| 978 |
+
self.cls = BertOnlyMLMHead(config)
|
| 979 |
+
|
| 980 |
+
self.init_weights()
|
| 981 |
+
|
| 982 |
+
def get_output_embeddings(self):
|
| 983 |
+
return self.cls.predictions.decoder
|
| 984 |
+
|
| 985 |
+
def set_output_embeddings(self, new_embeddings):
|
| 986 |
+
self.cls.predictions.decoder = new_embeddings
|
| 987 |
+
|
| 988 |
+
def forward(
|
| 989 |
+
self,
|
| 990 |
+
input_ids=None,
|
| 991 |
+
attention_mask=None,
|
| 992 |
+
position_ids=None,
|
| 993 |
+
head_mask=None,
|
| 994 |
+
query_embeds=None,
|
| 995 |
+
encoder_hidden_states=None,
|
| 996 |
+
encoder_attention_mask=None,
|
| 997 |
+
labels=None,
|
| 998 |
+
past_key_values=None,
|
| 999 |
+
use_cache=True,
|
| 1000 |
+
output_attentions=None,
|
| 1001 |
+
output_hidden_states=None,
|
| 1002 |
+
return_dict=None,
|
| 1003 |
+
return_logits=False,
|
| 1004 |
+
is_decoder=True,
|
| 1005 |
+
reduction="mean",
|
| 1006 |
+
):
|
| 1007 |
+
r"""
|
| 1008 |
+
encoder_hidden_states (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length, hidden_size)`, `optional`):
|
| 1009 |
+
Sequence of hidden-states at the output of the last layer of the encoder. Used in the cross-attention if
|
| 1010 |
+
the model is configured as a decoder.
|
| 1011 |
+
encoder_attention_mask (:obj:`torch.FloatTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
|
| 1012 |
+
Mask to avoid performing attention on the padding token indices of the encoder input. This mask is used in
|
| 1013 |
+
the cross-attention if the model is configured as a decoder. Mask values selected in ``[0, 1]``:
|
| 1014 |
+
- 1 for tokens that are **not masked**,
|
| 1015 |
+
- 0 for tokens that are **masked**.
|
| 1016 |
+
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
|
| 1017 |
+
Labels for computing the left-to-right language modeling loss (next word prediction). Indices should be in
|
| 1018 |
+
``[-100, 0, ..., config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are
|
| 1019 |
+
ignored (masked), the loss is only computed for the tokens with labels n ``[0, ..., config.vocab_size]``
|
| 1020 |
+
past_key_values (:obj:`tuple(tuple(torch.FloatTensor))` of length :obj:`config.n_layers` with each tuple having 4 tensors of shape :obj:`(batch_size, num_heads, sequence_length - 1, embed_size_per_head)`):
|
| 1021 |
+
Contains precomputed key and value hidden states of the attention blocks. Can be used to speed up decoding.
|
| 1022 |
+
If :obj:`past_key_values` are used, the user can optionally input only the last :obj:`decoder_input_ids`
|
| 1023 |
+
(those that don't have their past key value states given to this model) of shape :obj:`(batch_size, 1)`
|
| 1024 |
+
instead of all :obj:`decoder_input_ids` of shape :obj:`(batch_size, sequence_length)`.
|
| 1025 |
+
use_cache (:obj:`bool`, `optional`):
|
| 1026 |
+
If set to :obj:`True`, :obj:`past_key_values` key value states are returned and can be used to speed up
|
| 1027 |
+
decoding (see :obj:`past_key_values`).
|
| 1028 |
+
Returns:
|
| 1029 |
+
Example::
|
| 1030 |
+
>>> from transformers import BertTokenizer, BertLMHeadModel, BertConfig
|
| 1031 |
+
>>> import torch
|
| 1032 |
+
>>> tokenizer = BertTokenizer.from_pretrained('bert-base-cased')
|
| 1033 |
+
>>> config = BertConfig.from_pretrained("bert-base-cased")
|
| 1034 |
+
>>> model = BertLMHeadModel.from_pretrained('bert-base-cased', config=config)
|
| 1035 |
+
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
|
| 1036 |
+
>>> outputs = model(**inputs)
|
| 1037 |
+
>>> prediction_logits = outputs.logits
|
| 1038 |
+
"""
|
| 1039 |
+
return_dict = (
|
| 1040 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1041 |
+
)
|
| 1042 |
+
if labels is not None:
|
| 1043 |
+
use_cache = False
|
| 1044 |
+
if past_key_values is not None:
|
| 1045 |
+
query_embeds = None
|
| 1046 |
+
|
| 1047 |
+
outputs = self.bert(
|
| 1048 |
+
input_ids,
|
| 1049 |
+
attention_mask=attention_mask,
|
| 1050 |
+
position_ids=position_ids,
|
| 1051 |
+
head_mask=head_mask,
|
| 1052 |
+
query_embeds=query_embeds,
|
| 1053 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1054 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1055 |
+
past_key_values=past_key_values,
|
| 1056 |
+
use_cache=use_cache,
|
| 1057 |
+
output_attentions=output_attentions,
|
| 1058 |
+
output_hidden_states=output_hidden_states,
|
| 1059 |
+
return_dict=return_dict,
|
| 1060 |
+
is_decoder=is_decoder,
|
| 1061 |
+
)
|
| 1062 |
+
|
| 1063 |
+
sequence_output = outputs[0]
|
| 1064 |
+
if query_embeds is not None:
|
| 1065 |
+
sequence_output = outputs[0][:, query_embeds.shape[1] :, :]
|
| 1066 |
+
|
| 1067 |
+
prediction_scores = self.cls(sequence_output)
|
| 1068 |
+
|
| 1069 |
+
if return_logits:
|
| 1070 |
+
return prediction_scores[:, :-1, :].contiguous()
|
| 1071 |
+
|
| 1072 |
+
lm_loss = None
|
| 1073 |
+
if labels is not None:
|
| 1074 |
+
# we are doing next-token prediction; shift prediction scores and input ids by one
|
| 1075 |
+
shifted_prediction_scores = prediction_scores[:, :-1, :].contiguous()
|
| 1076 |
+
labels = labels[:, 1:].contiguous()
|
| 1077 |
+
loss_fct = CrossEntropyLoss(reduction=reduction, label_smoothing=0.1)
|
| 1078 |
+
lm_loss = loss_fct(
|
| 1079 |
+
shifted_prediction_scores.view(-1, self.config.vocab_size),
|
| 1080 |
+
labels.view(-1),
|
| 1081 |
+
)
|
| 1082 |
+
if reduction == "none":
|
| 1083 |
+
lm_loss = lm_loss.view(prediction_scores.size(0), -1).sum(1)
|
| 1084 |
+
|
| 1085 |
+
if not return_dict:
|
| 1086 |
+
output = (prediction_scores,) + outputs[2:]
|
| 1087 |
+
return ((lm_loss,) + output) if lm_loss is not None else output
|
| 1088 |
+
|
| 1089 |
+
return CausalLMOutputWithCrossAttentions(
|
| 1090 |
+
loss=lm_loss,
|
| 1091 |
+
logits=prediction_scores,
|
| 1092 |
+
past_key_values=outputs.past_key_values,
|
| 1093 |
+
hidden_states=outputs.hidden_states,
|
| 1094 |
+
attentions=outputs.attentions,
|
| 1095 |
+
cross_attentions=outputs.cross_attentions,
|
| 1096 |
+
)
|
| 1097 |
+
|
| 1098 |
+
def prepare_inputs_for_generation(
|
| 1099 |
+
self, input_ids, query_embeds, past=None, attention_mask=None, **model_kwargs
|
| 1100 |
+
):
|
| 1101 |
+
# if model is used as a decoder in encoder-decoder model, the decoder attention mask is created on the fly
|
| 1102 |
+
if attention_mask is None:
|
| 1103 |
+
attention_mask = input_ids.new_ones(input_ids.shape)
|
| 1104 |
+
query_mask = input_ids.new_ones(query_embeds.shape[:-1])
|
| 1105 |
+
attention_mask = torch.cat([query_mask, attention_mask], dim=-1)
|
| 1106 |
+
|
| 1107 |
+
# cut decoder_input_ids if past is used
|
| 1108 |
+
if past is not None:
|
| 1109 |
+
input_ids = input_ids[:, -1:]
|
| 1110 |
+
|
| 1111 |
+
return {
|
| 1112 |
+
"input_ids": input_ids,
|
| 1113 |
+
"query_embeds": query_embeds,
|
| 1114 |
+
"attention_mask": attention_mask,
|
| 1115 |
+
"past_key_values": past,
|
| 1116 |
+
"encoder_hidden_states": model_kwargs.get("encoder_hidden_states", None),
|
| 1117 |
+
"encoder_attention_mask": model_kwargs.get("encoder_attention_mask", None),
|
| 1118 |
+
"is_decoder": True,
|
| 1119 |
+
}
|
| 1120 |
+
|
| 1121 |
+
def _reorder_cache(self, past, beam_idx):
|
| 1122 |
+
reordered_past = ()
|
| 1123 |
+
for layer_past in past:
|
| 1124 |
+
reordered_past += (
|
| 1125 |
+
tuple(
|
| 1126 |
+
past_state.index_select(0, beam_idx) for past_state in layer_past
|
| 1127 |
+
),
|
| 1128 |
+
)
|
| 1129 |
+
return reordered_past
|
| 1130 |
+
|
| 1131 |
+
|
| 1132 |
+
class BertForMaskedLM(BertPreTrainedModel):
|
| 1133 |
+
|
| 1134 |
+
_keys_to_ignore_on_load_unexpected = [r"pooler"]
|
| 1135 |
+
_keys_to_ignore_on_load_missing = [r"position_ids", r"predictions.decoder.bias"]
|
| 1136 |
+
|
| 1137 |
+
def __init__(self, config):
|
| 1138 |
+
super().__init__(config)
|
| 1139 |
+
|
| 1140 |
+
self.bert = BertModel(config, add_pooling_layer=False)
|
| 1141 |
+
self.cls = BertOnlyMLMHead(config)
|
| 1142 |
+
|
| 1143 |
+
self.init_weights()
|
| 1144 |
+
|
| 1145 |
+
def get_output_embeddings(self):
|
| 1146 |
+
return self.cls.predictions.decoder
|
| 1147 |
+
|
| 1148 |
+
def set_output_embeddings(self, new_embeddings):
|
| 1149 |
+
self.cls.predictions.decoder = new_embeddings
|
| 1150 |
+
|
| 1151 |
+
def forward(
|
| 1152 |
+
self,
|
| 1153 |
+
input_ids=None,
|
| 1154 |
+
attention_mask=None,
|
| 1155 |
+
position_ids=None,
|
| 1156 |
+
head_mask=None,
|
| 1157 |
+
query_embeds=None,
|
| 1158 |
+
encoder_hidden_states=None,
|
| 1159 |
+
encoder_attention_mask=None,
|
| 1160 |
+
labels=None,
|
| 1161 |
+
output_attentions=None,
|
| 1162 |
+
output_hidden_states=None,
|
| 1163 |
+
return_dict=None,
|
| 1164 |
+
return_logits=False,
|
| 1165 |
+
is_decoder=False,
|
| 1166 |
+
):
|
| 1167 |
+
r"""
|
| 1168 |
+
labels (:obj:`torch.LongTensor` of shape :obj:`(batch_size, sequence_length)`, `optional`):
|
| 1169 |
+
Labels for computing the masked language modeling loss. Indices should be in ``[-100, 0, ...,
|
| 1170 |
+
config.vocab_size]`` (see ``input_ids`` docstring) Tokens with indices set to ``-100`` are ignored
|
| 1171 |
+
(masked), the loss is only computed for the tokens with labels in ``[0, ..., config.vocab_size]``
|
| 1172 |
+
"""
|
| 1173 |
+
|
| 1174 |
+
return_dict = (
|
| 1175 |
+
return_dict if return_dict is not None else self.config.use_return_dict
|
| 1176 |
+
)
|
| 1177 |
+
|
| 1178 |
+
outputs = self.bert(
|
| 1179 |
+
input_ids,
|
| 1180 |
+
attention_mask=attention_mask,
|
| 1181 |
+
position_ids=position_ids,
|
| 1182 |
+
head_mask=head_mask,
|
| 1183 |
+
query_embeds=query_embeds,
|
| 1184 |
+
encoder_hidden_states=encoder_hidden_states,
|
| 1185 |
+
encoder_attention_mask=encoder_attention_mask,
|
| 1186 |
+
output_attentions=output_attentions,
|
| 1187 |
+
output_hidden_states=output_hidden_states,
|
| 1188 |
+
return_dict=return_dict,
|
| 1189 |
+
is_decoder=is_decoder,
|
| 1190 |
+
)
|
| 1191 |
+
|
| 1192 |
+
if query_embeds is not None:
|
| 1193 |
+
sequence_output = outputs[0][:, query_embeds.shape[1] :, :]
|
| 1194 |
+
prediction_scores = self.cls(sequence_output)
|
| 1195 |
+
|
| 1196 |
+
if return_logits:
|
| 1197 |
+
return prediction_scores
|
| 1198 |
+
|
| 1199 |
+
masked_lm_loss = None
|
| 1200 |
+
if labels is not None:
|
| 1201 |
+
loss_fct = CrossEntropyLoss() # -100 index = padding token
|
| 1202 |
+
masked_lm_loss = loss_fct(
|
| 1203 |
+
prediction_scores.view(-1, self.config.vocab_size), labels.view(-1)
|
| 1204 |
+
)
|
| 1205 |
+
|
| 1206 |
+
if not return_dict:
|
| 1207 |
+
output = (prediction_scores,) + outputs[2:]
|
| 1208 |
+
return (
|
| 1209 |
+
((masked_lm_loss,) + output) if masked_lm_loss is not None else output
|
| 1210 |
+
)
|
| 1211 |
+
|
| 1212 |
+
return MaskedLMOutput(
|
| 1213 |
+
loss=masked_lm_loss,
|
| 1214 |
+
logits=prediction_scores,
|
| 1215 |
+
hidden_states=outputs.hidden_states,
|
| 1216 |
+
attentions=outputs.attentions,
|
| 1217 |
+
)
|
requirements.txt
ADDED
|
@@ -0,0 +1,10 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
torch==2.0.1
|
| 2 |
+
torchaudio==2.0.2
|
| 3 |
+
peft==0.3.0
|
| 4 |
+
soundfile
|
| 5 |
+
librosa
|
| 6 |
+
transformers==4.28.0
|
| 7 |
+
sentencepiece==0.1.97
|
| 8 |
+
accelerate==0.20.3
|
| 9 |
+
bitsandbytes==0.35.0
|
| 10 |
+
gradio==3.23.0
|
resource/audio_demo/duck.wav
ADDED
|
Binary file (640 kB). View file
|
|
|
resource/audio_demo/excitement.wav
ADDED
|
Binary file (40.4 kB). View file
|
|
|
resource/audio_demo/gunshots.wav
ADDED
|
Binary file (320 kB). View file
|
|
|
resource/audio_demo/mountain.wav
ADDED
|
Binary file (79.1 kB). View file
|
|
|
resource/audio_demo/music.wav
ADDED
|
Binary file (639 kB). View file
|
|
|
resource/response_demo/aac.png
ADDED
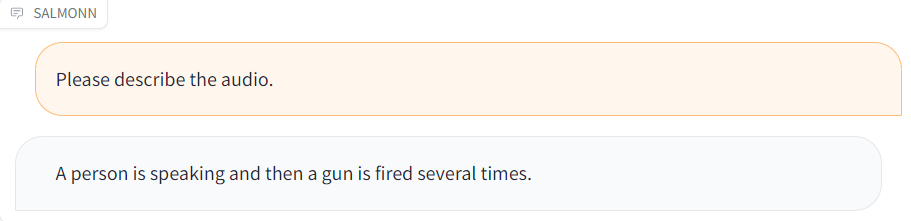
|
resource/response_demo/aed.png
ADDED

|
resource/response_demo/asr.png
ADDED

|
resource/response_demo/emo.png
ADDED

|
resource/response_demo/jsac.png
ADDED
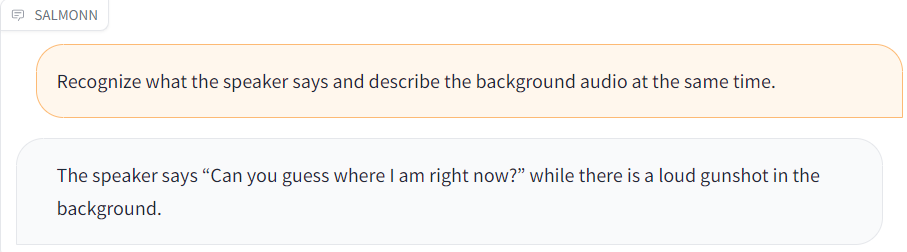
|
resource/response_demo/lyrics.png
ADDED
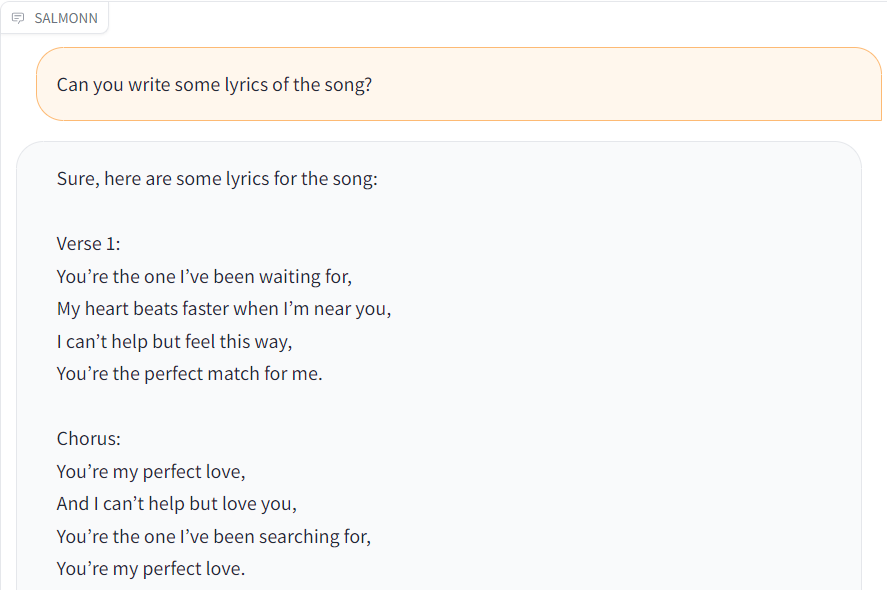
|
resource/response_demo/mc.png
ADDED
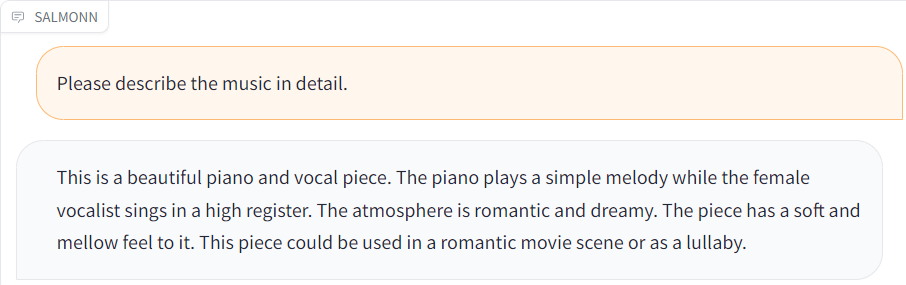
|
resource/response_demo/memo.png
ADDED
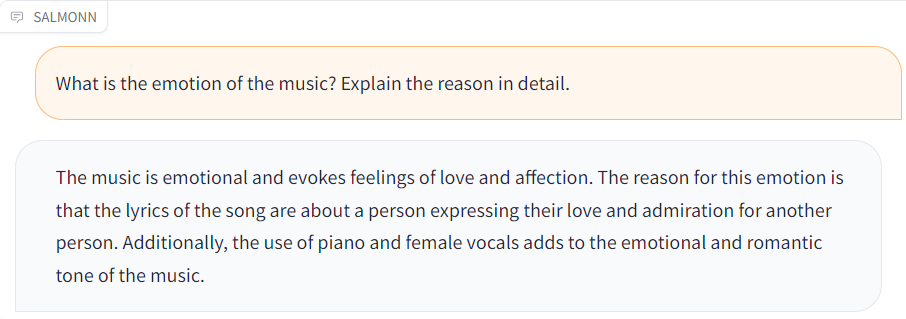
|
resource/response_demo/pr.png
ADDED
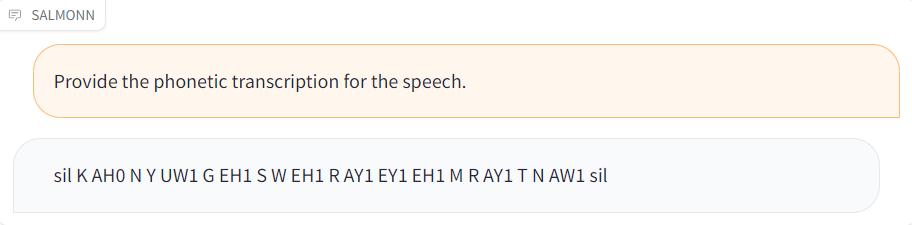
|
resource/response_demo/sac.png
ADDED
|
resource/response_demo/sq.png
ADDED

|
resource/response_demo/sr.png
ADDED

|
resource/response_demo/story.png
ADDED
|
resource/response_demo/title.png
ADDED

|
resource/salmon.png
ADDED

|
Git LFS Details
|
resource/structure.png
ADDED

|
salmonn_7b_v0.pth
ADDED
|
@@ -0,0 +1,3 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
version https://git-lfs.github.com/spec/v1
|
| 2 |
+
oid sha256:2cb2782495b2e3f487222763a30b53b02f727d49059201cc5fa88a7a1fd9dff9
|
| 3 |
+
size 362638989
|
web_demo.py
ADDED
|
@@ -0,0 +1,166 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
# Copyright (2023) Tsinghua University, Bytedance Ltd. and/or its affiliates
|
| 2 |
+
#
|
| 3 |
+
# Licensed under the Apache License, Version 2.0 (the "License");
|
| 4 |
+
# you may not use this file except in compliance with the License.
|
| 5 |
+
# You may obtain a copy of the License at
|
| 6 |
+
#
|
| 7 |
+
# http://www.apache.org/licenses/LICENSE-2.0
|
| 8 |
+
#
|
| 9 |
+
# Unless required by applicable law or agreed to in writing, software
|
| 10 |
+
# distributed under the License is distributed on an "AS IS" BASIS,
|
| 11 |
+
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
| 12 |
+
# See the License for the specific language governing permissions and
|
| 13 |
+
# limitations under the License.
|
| 14 |
+
|
| 15 |
+
import gradio as gr
|
| 16 |
+
import argparse
|
| 17 |
+
from model import SALMONN
|
| 18 |
+
|
| 19 |
+
class ff:
|
| 20 |
+
def generate(self, wav_path, prompt, prompt_pattern, num_beams, temperature, top_p):
|
| 21 |
+
print(f'wav_path: {wav_path}, prompt: {prompt}, temperature: {temperature}, num_beams: {num_beams}, top_p: {top_p}')
|
| 22 |
+
return "I'm sorry, but I cannot answer that question as it is not clear what you are asking. Can you please provide more context or clarify your question?"
|
| 23 |
+
|
| 24 |
+
parser = argparse.ArgumentParser()
|
| 25 |
+
parser.add_argument("--device", type=str, default="cuda:0")
|
| 26 |
+
parser.add_argument("--ckpt_path", type=str, default=None)
|
| 27 |
+
parser.add_argument("--whisper_path", type=str, default=None)
|
| 28 |
+
parser.add_argument("--beats_path", type=str, default=None)
|
| 29 |
+
parser.add_argument("--vicuna_path", type=str, default=None)
|
| 30 |
+
parser.add_argument("--low_resource", action='store_true', default=False)
|
| 31 |
+
parser.add_argument("--lora_alpha", type=int, default=32)
|
| 32 |
+
parser.add_argument("--port", default=9527)
|
| 33 |
+
|
| 34 |
+
args = parser.parse_args()
|
| 35 |
+
# model = ff()
|
| 36 |
+
model = SALMONN(
|
| 37 |
+
ckpt=args.ckpt_path,
|
| 38 |
+
whisper_path=args.whisper_path,
|
| 39 |
+
beats_path=args.beats_path,
|
| 40 |
+
vicuna_path=args.vicuna_path,
|
| 41 |
+
lora_alpha=args.lora_alpha,
|
| 42 |
+
low_resource=args.low_resource
|
| 43 |
+
)
|
| 44 |
+
model.to(args.device)
|
| 45 |
+
model.eval()
|
| 46 |
+
|
| 47 |
+
# gradio
|
| 48 |
+
def gradio_reset(chat_state):
|
| 49 |
+
|
| 50 |
+
chat_state = []
|
| 51 |
+
return (None,
|
| 52 |
+
gr.update(value=None, interactive=True),
|
| 53 |
+
gr.update(placeholder='Please upload your wav first', interactive=False),
|
| 54 |
+
gr.update(value="Upload & Start Chat", interactive=True),
|
| 55 |
+
chat_state)
|
| 56 |
+
|
| 57 |
+
def upload_speech(gr_speech, text_input, chat_state):
|
| 58 |
+
|
| 59 |
+
if gr_speech is None:
|
| 60 |
+
return None, None, gr.update(interactive=True), chat_state, None
|
| 61 |
+
chat_state.append(gr_speech)
|
| 62 |
+
return (gr.update(interactive=False),
|
| 63 |
+
gr.update(interactive=True, placeholder='Type and press Enter'),
|
| 64 |
+
gr.update(value="Start Chatting", interactive=False),
|
| 65 |
+
chat_state)
|
| 66 |
+
|
| 67 |
+
def gradio_ask(user_message, chatbot, chat_state):
|
| 68 |
+
|
| 69 |
+
if len(user_message) == 0:
|
| 70 |
+
return gr.update(interactive=True, placeholder='Input should not be empty!'), chatbot, chat_state
|
| 71 |
+
chat_state.append(user_message)
|
| 72 |
+
chatbot.append([user_message, None])
|
| 73 |
+
#
|
| 74 |
+
return gr.update(interactive=False, placeholder='Currently only single round conversations are supported.'), chatbot, chat_state
|
| 75 |
+
|
| 76 |
+
def gradio_answer(chatbot, chat_state, num_beams, temperature, top_p):
|
| 77 |
+
llm_message = model.generate(
|
| 78 |
+
wav_path=chat_state[0],
|
| 79 |
+
prompt=chat_state[1],
|
| 80 |
+
num_beams=num_beams,
|
| 81 |
+
temperature=temperature,
|
| 82 |
+
top_p=top_p,
|
| 83 |
+
)
|
| 84 |
+
chatbot[-1][1] = llm_message[0]
|
| 85 |
+
return chatbot, chat_state
|
| 86 |
+
|
| 87 |
+
title = """<h1 align="center">SALMONN: Speech Audio Language Music Open Neural Network</h1>"""
|
| 88 |
+
image_src = """<h1 align="center"><a href="https://github.com/bytedance/SALMONN"><img src="https://raw.githubusercontent.com/bytedance/SALMONN/main/resource/salmon.png", alt="SALMONN" border="0" style="margin: 0 auto; height: 200px;" /></a> </h1>"""
|
| 89 |
+
description = """<h3>This is the demo of SALMONN. Upload your audio and start chatting!</h3>"""
|
| 90 |
+
|
| 91 |
+
|
| 92 |
+
with gr.Blocks() as demo:
|
| 93 |
+
gr.Markdown(title)
|
| 94 |
+
gr.Markdown(image_src)
|
| 95 |
+
gr.Markdown(description)
|
| 96 |
+
|
| 97 |
+
with gr.Row():
|
| 98 |
+
with gr.Column():
|
| 99 |
+
speech = gr.Audio(label="Audio", type='filepath')
|
| 100 |
+
upload_button = gr.Button(value="Upload & Start Chat", interactive=True, variant="primary")
|
| 101 |
+
clear = gr.Button("Restart")
|
| 102 |
+
|
| 103 |
+
num_beams = gr.Slider(
|
| 104 |
+
minimum=1,
|
| 105 |
+
maximum=10,
|
| 106 |
+
value=4,
|
| 107 |
+
step=1,
|
| 108 |
+
interactive=True,
|
| 109 |
+
label="beam search numbers",
|
| 110 |
+
)
|
| 111 |
+
|
| 112 |
+
top_p = gr.Slider(
|
| 113 |
+
minimum=0.1,
|
| 114 |
+
maximum=1.0,
|
| 115 |
+
value=0.9,
|
| 116 |
+
step=0.1,
|
| 117 |
+
interactive=True,
|
| 118 |
+
label="top p",
|
| 119 |
+
)
|
| 120 |
+
|
| 121 |
+
temperature = gr.Slider(
|
| 122 |
+
minimum=0.8,
|
| 123 |
+
maximum=2.0,
|
| 124 |
+
value=1.0,
|
| 125 |
+
step=0.1,
|
| 126 |
+
interactive=False,
|
| 127 |
+
label="temperature",
|
| 128 |
+
)
|
| 129 |
+
|
| 130 |
+
with gr.Column():
|
| 131 |
+
chat_state = gr.State([])
|
| 132 |
+
|
| 133 |
+
chatbot = gr.Chatbot(label='SALMONN')
|
| 134 |
+
text_input = gr.Textbox(label='User', placeholder='Please upload your speech first', interactive=False)
|
| 135 |
+
|
| 136 |
+
with gr.Row():
|
| 137 |
+
examples = gr.Examples(
|
| 138 |
+
examples = [
|
| 139 |
+
["resource/audio_demo/gunshots.wav", "Recognize the speech and give me the transcription."],
|
| 140 |
+
["resource/audio_demo/gunshots.wav", "Provide the phonetic transcription for the speech."],
|
| 141 |
+
["resource/audio_demo/gunshots.wav", "Please describe the audio."],
|
| 142 |
+
["resource/audio_demo/gunshots.wav", "Recognize what the speaker says and describe the background audio at the same time."],
|
| 143 |
+
["resource/audio_demo/gunshots.wav", "Please answer the speaker's question in detail based on the background sound."],
|
| 144 |
+
["resource/audio_demo/duck.wav", "Please list each event in the audio in order."],
|
| 145 |
+
["resource/audio_demo/duck.wav", "Based on the audio, write a story in detail. Your story should be highly related to the audio."],
|
| 146 |
+
["resource/audio_demo/duck.wav", "How many speakers did you hear in this audio? Who are they?"],
|
| 147 |
+
["resource/audio_demo/excitement.wav", "Describe the emotion of the speaker."],
|
| 148 |
+
["resource/audio_demo/mountain.wav", "Please answer the question in detail."],
|
| 149 |
+
["resource/audio_demo/music.wav", "Please describe the music in detail."],
|
| 150 |
+
["resource/audio_demo/music.wav", "What is the emotion of the music? Explain the reason in detail."],
|
| 151 |
+
["resource/audio_demo/music.wav", "Can you write some lyrics of the song?"],
|
| 152 |
+
["resource/audio_demo/music.wav", "Give me a title of the music based on its rhythm and emotion."]
|
| 153 |
+
],
|
| 154 |
+
inputs=[speech, text_input]
|
| 155 |
+
)
|
| 156 |
+
|
| 157 |
+
upload_button.click(upload_speech, [speech, text_input, chat_state], [speech, text_input, upload_button, chat_state])
|
| 158 |
+
|
| 159 |
+
text_input.submit(gradio_ask, [text_input, chatbot, chat_state], [text_input, chatbot, chat_state]).then(
|
| 160 |
+
gradio_answer, [chatbot, chat_state, num_beams, temperature, top_p], [chatbot, chat_state]
|
| 161 |
+
)
|
| 162 |
+
clear.click(gradio_reset, [chat_state], [chatbot, speech, text_input, upload_button, chat_state], queue=False)
|
| 163 |
+
|
| 164 |
+
|
| 165 |
+
|
| 166 |
+
demo.launch(share=True, enable_queue=True, server_port=int(args.port))
|