---
license: apache-2.0
tags:
- automatic-speech-recognition
- automatic-audio-captioning
- automatic-speech-translation
- music-captioning
- audio-based-storytelling
- speech-audio-coreasoning
- auditory understanding
language:
- en
metrics:
- wer
- bleu
- accuracy
---
# SALMONN: Speech Audio Language Music Open Neural Network
🚀🚀 Welcome to the repo of **SALMONN**!
SALMONN is a large language model (LLM) enabling **speech, audio events, and music inputs**, which is developed by the Department of Electronic Engineering at Tsinghua University and ByteDance. Instead of speech-only input or audio-event-only input, SALMONN can perceive and understand all kinds of audio inputs and therefore obtain emerging capabilities such as multilingual speech recognition & translation and audio-speech co-reasoning. This can be regarded as giving the LLM "ears" and cognitive hearing abilities, which makes SALMONN a step towards hearing-enabled artificial general intelligence.
## News
- [10-08] ✨ We have released [**the model checkpoint**](https://huggingface.co/tsinghua-ee/SALMONN) and **the inference code** for SALMONN-13B!
- [11-13] 🎁 We have released a **7B version of SALMONN** at [tsinghua-ee/SALMONN-7B](https://huggingface.co/tsinghua-ee/SALMONN-7B) and built the 7B demo [here](https://huggingface.co/spaces/tsinghua-ee/SALMONN-7B-gradio)!
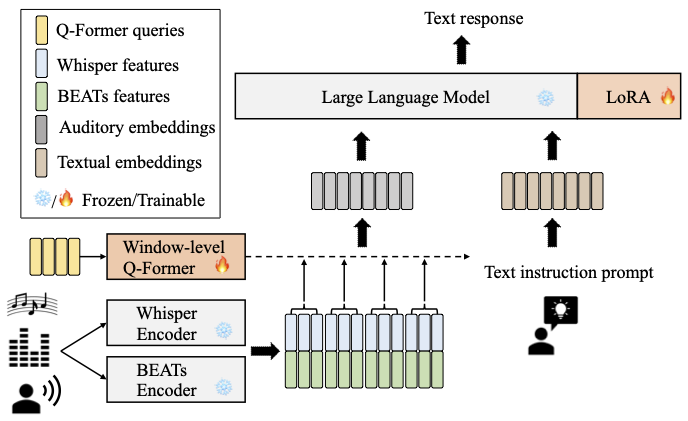
## Structure
The model architecture of SALMONN is shown below. A window-level Q-Former is used as the connection module to fuse the outputs from a Whisper speech encoder and a BEATs audio encoder as augmented audio tokens, which are aligned with the LLM input space. The LoRA adaptor aligns the augmented LLM input space with its output space. The text prompt is used to instruct SALMONN to answer open-ended questions about the general audio inputs and the answers are in the LLM text responses.
## Demos
Compared with traditional speech and audio processing tasks such as speech recognition and audio caption, SALMONN leverages the general knowledge and cognitive abilities of the LLM to achieve a cognitively oriented audio perception, which dramatically improves the versatility of the model and the richness of the task. In addition, SALMONN is able to follow textual commands, and even spoken commands, with a relatively high degree of accuracy. Since SALMONN only uses training data based on textual commands, listening to spoken commands is also a cross-modal emergent ability.
Here are some examples of SALMONN.
| Audio | Response |
| ------------------------------------------------------ | -------------------------------------------- |
| [gunshots.wav](./resource/audio_demo/gunshots.wav) | 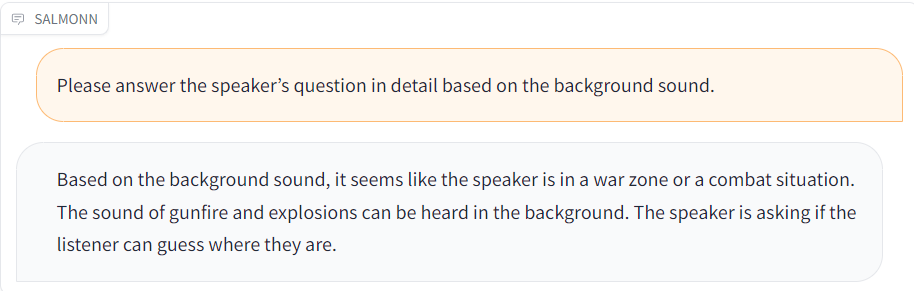 |
| [duck.wav](./resource/audio_demo/duck.wav) | 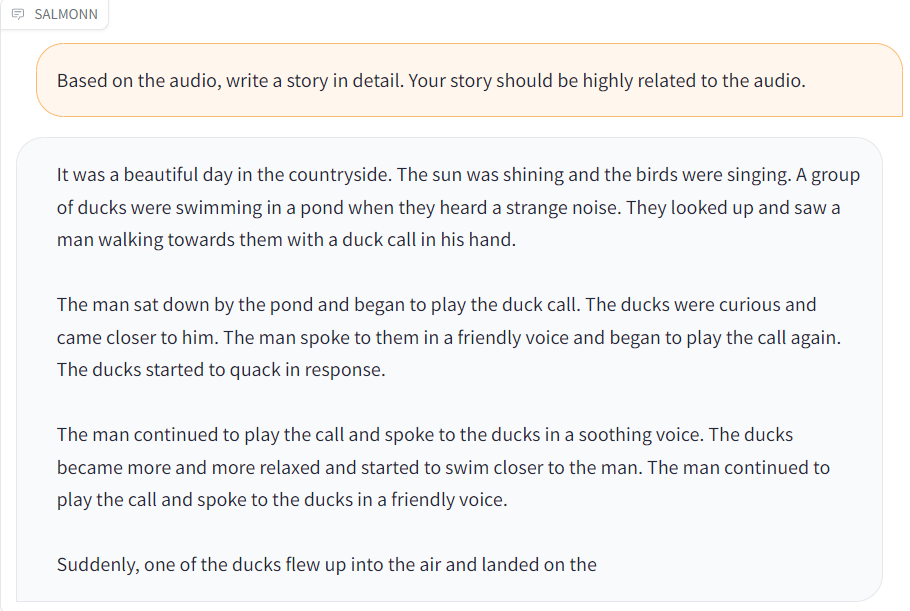 |
| [music.wav](./resource/audio_demo/music.wav) | 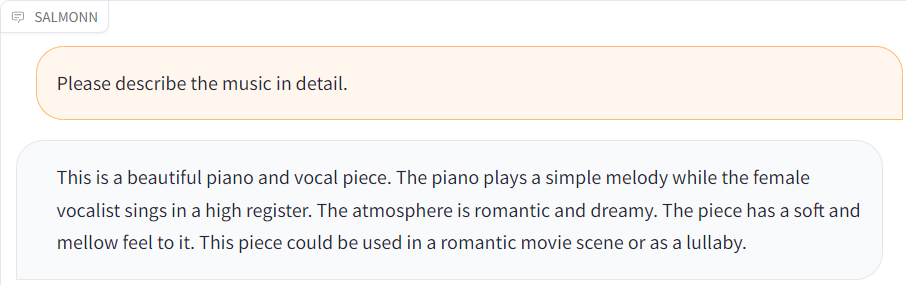 |
## How to inference in CLI
For SALMONN-7B v0, you need to use the following dependencies:
1. Our environment: The python version is 3.9.17, and other required packages can be installed with the following command: ```pip install -r requirements.txt```.
2. Download [whisper large v2](https://huggingface.co/openai/whisper-large-v2/tree/main) to ```whisper_path```.
3. Download [Fine-tuned BEATs_iter3+ (AS2M) (cpt2)](https://valle.blob.core.windows.net/share/BEATs/BEATs_iter3_plus_AS2M_finetuned_on_AS2M_cpt2.pt?sv=2020-08-04&st=2023-03-01T07%3A51%3A05Z&se=2033-03-02T07%3A51%3A00Z&sr=c&sp=rl&sig=QJXmSJG9DbMKf48UDIU1MfzIro8HQOf3sqlNXiflY1I%3D) to `beats_path`.
4. Download [vicuna 7B v1.5](https://huggingface.co/lmsys/vicuna-7b-v1.5/tree/main) to ```vicuna_path```.
5. Download [salmonn-7b v0](https://huggingface.co/tsinghua-ee/SALMONN-7B/blob/main/salmonn_7b_v0.pth) to ```ckpt_path```.
6. Running with ```python3 cli_inference.py --ckpt_path xxx --whisper_path xxx --beats_path xxx --vicuna_path xxx``` to start cli inference. Please make sure your GPU has more than 40G of memory. If your GPU does not have enough memory (e.g. only 24G), you can quantize the model using the `--low_resource` parameter to reduce the memory usage, and can reduce the LoRA scaling factor to maintain the model's emergent abilities, e.g. `--lora_alpha=28`.
## How to launch a web demo
1. Same as **How to inference in CLI: 1-5**.
2. Running with ```python3 web_demo.py --ckpt_path xxx --whisper_path xxx --beats_path xxx --vicuna_path xxx``` in A100-SXM-80GB. You can add `--low_resource` parameter if the GPU memory is not enough, and reduce the LoRA scaling factor to maintain the model's emergent abilities.
## Team
**Team Tsinghua**: Wenyi Yu, Changli Tang, Guangzhi Sun, Chao Zhang
**Team ByteDance**: Xianzhao Chen, Wei Li, Tian Tan, Lu Lu, Zejun Ma
## Citation
If you find SALMONN great and useful, please cite our paper:
```
@article{tang2023salmonn,
title={{SALMONN}: Towards Generic Hearing Abilities for Large Language Models},
author={Changli, Tang and Wenyi, Yu and Guangzhi, Sun and Xianzhao, Chen and Tian, Tan and Wei, Li and Lu, Lu and Zejun, Ma and Chao, Zhang},
journal={arXiv:2310.13289},
year={2023}
}
```